Last week, I attended a meeting at Columbia University on attribution science and climate law, hosted by the Sabin Center. It was a fantastic event, bringing together scientists and legal experts working at the intersection of extreme event attribution and climate law.
For those unfamiliar with it, extreme event attribution attempts to quantify the contribution of climate change to an extreme event. For example, severalgroupsanalyzed the impact of climate change on Hurricane Harvey’s enormous rainfall totals over Houston, Texas and they found that climate change increased rainfall by 15 to 38%.
One thing that came up again and again was how terrified fossil-fuel interests are of extreme event attribution science. They are acutely aware that this research could land them in court. And losing those cases would leave them legally liable for billions of dollars in climate damages.
Because the legal stakes are so high, the blowback has turned ugly. I spoke with several scientists at the meeting who are facing ongoing harassment over their work.
This blowback is a coordinated campaign to make the entire field look suspect. The goal is to create the impression that attribution science is too uncertain, too political, or too conflicted to be useful in court or in public policy. The strategy is not based on actual science or evidence of misconduct, but on the generation of doubt.
The new Merchants of Doubt
We’ve seen this before. In fact, not that long ago: We only have to go back a year to the Department of Energy (DOE) Climate Working Group (CWG) report to see an example of using doubt as the tool to push back against well-established science.
This strategy is laid out in an email from a member of the CWG, Dr. Roy Spencer, that was released during litigation over the Climate Working Group process.
About all I can hope is that what we write will provide sufficient “reasonable scientific doubt” regarding the science claims in the 2009 TSD [technical support document], based upon almost 2 decades of new science, to call into question the original reasoning for the EPA Administrator’s decision that CO2 presents a threat to human health and welfare.
This statement is strong evidence that at least some members of the committee were working to support a particular policy outcome: revoking the Endangerment Finding. The email also explains how they planned to do it: by attempting to generate “reasonable doubt”.
This is going to be hard, Spencer implies. Despite falsely claiming that “2 decades of new science” weakens the case, Spencer explicitly acknowledges that the actual peer-reviewed science of climate change overwhelmingly rejects his position:
But if the science argument is decided upon by a vote, or by the number of published citations, we lose the science argument.
We can go back even further: This CWG email shares unmistakable DNA with the infamous 1969 tobacco memo that declared: “Doubt is our product, since it is the best means of competing with the ‘body of fact’ that exists in the mind of the general public. It is also the means of establishing a controversy.”
The people attacking the IPCC chapter on extreme event attribution are the newest iteration of the Merchants of Doubt. Their goal, like all Merchants before them, is to introduce doubt into the process.
Because the report is not even out yet, they cannot attack its conclusions. So they are attacking the authors instead. Here is a press release from the House Science, Space, and Technology Committee:
In the letter, the Chairmen express concerns about potential conflicts of interest involving members of the Attribution Committee, stating that “publicly available information suggests a troubling pattern” in which committee members are affiliated with nonprofits that support climate accountability lawsuits, “raising the appearance of impropriety and member bias.”
To be clear, this is just innuendo. There is no actual evidence of bias. And given the robust process that these reports go through, including multiple lines of peer review, it seems very unlikely that significant bias can survive into the report.
When the report comes out, critics will have the opportunity to make legitimate criticisms of the report — if any exist. If none do, however, they’ll still make criticisms, but they’ll be bogus, simply designed to generate doubt. We’ll see.
A note to the press: Fix your frame
To any journalists reading this: The public debate over extreme event attribution science is not going away. The science is simply too dangerous to fossil-fuel interests for them to stop fighting it.
You very well might be assigned to write an article about this area of research in the future. When you do, do not automatically adopt the framing that climate misinformers want you to use.
They want you to frame the story around questions like: Are climate scientists trying to put their thumb on the scale to achieve a predetermined, politically motivated result? Are climate scientists improperly letting their politics invade the science of the IPCC?
That frame is a trap.
Instead, you need to view this through the historical lens of the Merchants of Doubt. How does the ecosystem of doubt operate? Who funds it? What methods do they use to misrepresent science and slime researchers? What scientific results are they trying to keep people from understanding are legitimate?
Ultimately, you need to focus your article on the generation of doubt as a way to maintain the fossil fuel industry’s social and legal license to keep burning oil, gas, and coal.
If you treat the misinformers’ frame as a legitimate, good-faith scientific critique, you are helping them produce doubt. Don’t do it. Don’t be a Merchant of Doubt.
Jim Franke pulls away the cover page of a presentation on the wraparound desk in his office, revealing an illustration of an odd-looking aircraft with massive wings stretching out from a stubby fuselage.
The uncrewed plane is soaring thousands of meters higher than commercial jets fly—so high you can see the curvature of the Earth. It’s precisely the type of aircraft one would need to begin artificially cooling the planet. Those outsize wings would keep the plane and its payload aloft in the stratosphere, about a dozen miles (or 20 kilometers) above the surface, where the air is much thinner—as little as 5% the density near the ground. Once at altitude, the plane would release materials that could, after a few steps of chemistry, reflect sunlight back into space.
“If you want to get to 20 kilometers in the near term, this is probably the best bet,” says Franke, a research assistant professor at the University of Chicago.
Franke is one of a small but growing cohort of scientists focused on the engineering challenges associated with solar geoengineering, the controversial idea that we could deliberately intervene in the climate system to counteract global warming.
The concept came from volcanoes. Massive eruptions in the past have reduced temperatures worldwide by blasting sulfur dioxide and other compounds into the stratosphere, where they convert into sunlight-scattering particles. Hundreds of studies in recent decades have suggested that a human attempt to mimic this mechanism would work quickly and efficiently—at least within the confines of climate models.
But these computer simulations are approximations of how the real world works. They gloss over numerous challenges. Like the fact that aircraft capable of carrying the necessary loads to the necessary altitudes don’t exist. Or that we don’t know for sure how to release material so that most of it turns into tiny reflective aerosols instead of, say, clumping together and falling out of the sky. Or even what specific substance we would want to load onto an aircraft, given open questions about safety, cost, and effectiveness.
Amid these compounding unknowns, more and more research on solar geoengineering is moving beyond computer simulations, delving into the detailed design and practical engineering work that would be needed before we could carry out a campaign to dial down temperatures. The tasks required range from inventing high-altitude aircraft to mastering the precise chemistry and delivery mechanisms for dispersing materials to building out the monitoring infrastructure that we’ll need in order to know if any of it actually works.
The question of whether we should geoengineer the planet has no clear-cut answer. It might save millions of lives by reducing the dangers of catastrophic heat waves, floods, droughts, and famines. But many fear it’s too dangerous to even consider, much less seriously study, arguing that we can’t possibly predict the spiraling consequences of manipulating such large, complex, interconnected planetary systems.
Critics argue that the building momentum in this phase of research will make it ever more likely that someone, somewhere in the world, will eventually pull the trigger on geoengineering, no matter the remaining unknowns or the dangers for certain parts of the world.
“I do think it’s very dangerous because of what we know about science and technology,” says Jennie Stephens, a professor of climate justice at Maynooth University in Ireland. “The more investment that’s made, the further the advances, the more likely it is that it will be deployed.”
But proponents of this practical research argue that playing out how we’d mount a solar geoengineering program will improve our understanding of the potential benefits and risks, helping to ensure that if anyone does try to tweak the climate, they might at least do so in an informed and potentially safer way.
The Climate Systems Engineering Initiative (CSEi) at the University of Chicago formally launched in 2024 under the leadership of the prominent geoengineering researcher David Keith.
It’s still very much a niche field. Much of the work now underway is happening at the Climate Systems Engineering Initiative (CSEi) at the University of Chicago, which formally launched in 2024 under the leadership of the prominent geoengineering researcher David Keith.
Franke, a professional engineer before earning his doctorate in geosciences, is overseeing a series of overlapping research projects and collaborations aimed at resolving many of the engineering uncertainties. That includes working out the designs now on his desk—renderings of the type of aircraft that could be used in the initial phase of a geoengineering program.
Franke argues that more computer simulations are simply not going to answer the big remaining questions in the field, including the most compelling one: the “boogeyman” of what could go wrong.
“I’m kind of personally skeptical that additional model development or more simulations are going to satisfactorily resolve those things,” he says. “And so I’m not really that interested in turning the crank on more models.”
For Franke, it’s time for the next step: “We’re interested in seeing how you’d actually do this thing if you wanted to do it.”
What we don’t know
Solar geoengineering is often portrayed as a relatively cheap and easy fix for climate change. But as researchers take a harder look at the nuts and bolts, they’re finding considerable uncertainties, missing tools, and unbuilt infrastructure.
None of that may be a showstopper, but we’ll need time and money to develop the components necessary to implement even the early stages of a solar geoengineering program. What this research is about, at its core, is not actually launching something, but figuring out what it would take to do so.
A young San Francisco nonprofit, Reflective, recently worked with scientists in the field to figure out just how much we still don’t know.
The process began by outlining what the organization, which pools money from donors to fund geoengineering studies, describes as a “well-managed, moderate” scenario: In 2035, some nation or group of nations begins a small-scale geoengineering deployment, spraying an equal amount of sulfur dioxide or hydrogen sulfide—gases that should convert into reflective aerosols in the stratosphere—near both the North and South Poles. The initial program would release enough material to reduce temperatures by about 0.1 °C, shaving off a fraction of the roughly 1.4 °C of worldwide warming that’s occurred since the start of the industrial era.
The poles figure prominently in this and other early-stage geoengineering scenarios, for a simple reason: The stratosphere starts as low as seven kilometers there—as opposed to around 18 to 20 kilometers at the equator. That makes it easier to reach, enabling existing aircraft, with some modifications, to carry sizable payloads up there.
The wrinkle is that the cooling effect would be more pronounced in the northernmost and southernmost latitudes. That’s because, among other complicated mechanisms, higher temperatures in the tropical stratosphere would mostly prevent aerosols released around the poles from drifting toward the equator. So deploying geoengineering in those areas would likely have milder effects on the hotter and poorer nations around the tropics, which are also some of the areas most vulnerable to climate change.
To cool the world evenly—and fairly—you’d eventually want to add flights closer to the equator. Over the following decade or so, under Reflective’s scenario, the program would scale up, shift to novel aircraft flying above the subtropics, and release enough material to achieve global cooling of 0.5 °C.
The question the researchers then examined was: If we wanted to carry out such a scenario, what would we still need to do to pull it off?
Quite a bit, it turns out. Earlier this year, Reflective published its SAI Uncertainty Database (SAI stands for “stratospheric aerosol injection”), highlighting a variety of scientific unknowns and six engineering obstacles.
Among them: sorting out how hard or expensive it would be to retrofit existing aircraft to carry out the early stages of the project. Deploying at the poles could also require constructing new airports, establishing new shipping lanes or railways to transport supplies, and building facilities that could process raw materials—by, for example, combusting elemental sulfur to produce sulfur dioxide.
We would also need to build more instruments and send them up to the stratosphere aboard balloons, drones, or other aircraft to observe the baseline chemistry, reflectivity, and distribution of compounds there—and to track what changed once new materials were released.
Finally, the main satellites that observe the stratosphere from space are set to go out of commission in the coming years, creating the risk of an “imminent data desert,” as a 2025 paper in the Bulletin of the American Meteorological Society warned. Several new instruments are in development or available for launch, but there could be a gap in observations at a point where we’d want to have a clear picture of the baseline conditions, Reflective notes.
Dakota Gruener, the chief executive officer of the nonprofit, stresses that the organization isn’t advocating the use of solar geoengineering. But she says it’s important for the field to begin addressing engineering uncertainties now because it stress-tests the assumptions in climate models. It helps us determine whether the scenarios explored in silico are feasible in the real world.
It’s also important to do this, she says, because it may take a long time to resolve all these unknowns while the climate grows steadily warmer. “If we aren’t putting adequate attention to them now, we might be caught flat-footed,” Gruener told MIT Technology Review.
A 2024 analysis in the journal Earth’s Future highlighted just how expensive and time-consuming it might be to develop the aircraft and infrastructure required for an initial deployment. The study explored what it would take for a geoengineering program around the poles, capable of reducing temperatures by 2 °C in the northernmost and southernmost parts of the planet, to be up and running by 2040. The conclusion: It could require at least a decade of work and a $35 billion investment.
Wake Smith, a research fellow at Harvard and lead author of the study, also says that researchers need to move forward with engineering studies now, because the urge to use the technology will likely grow stronger as climate change becomes increasingly catastrophic.
“The risk I worry about is needing it before we understand it and therefore doing it badly,” he says, later adding: “The sooner we get going with it, the better decisions we’ll be able to make a few decades hence in terms of whether to do it, how to do it, when to do it.”
A novel aircraft
The aircraft pictured on Franke’s desk, which is still just a concept, could reach just beyond the threshold of the stratosphere above the tropics when fully loaded. A fleet of 270 of them could disperse about a million metric tons of material per year, enough to ease global surface temperatures by about 0.26 °C.
The CSEi outsourced the work of designing it to John Langford, a well-known aeronautical engineer and entrepreneur. Langford’s company, Electra.aero, had previously collaborated with the MIT Department of Aeronautics and Astronautics to develop autonomous, solar-powered aircraft that could carry out extended scientific missions in the stratosphere. He is now spinning out a new business, Iris Aero, to produce those planes, which are assembled from a single, continuous wing covered in solar panels and suspended above a tiny fuselage.
Langford expects the solar plane to find its main initial commercial applications in wildfire monitoring and forecasting. But by swapping in a different set of instruments, it could be used to monitor how materials dispersed in the stratosphere might alter conditions there, he says.
The novel aircraft is a variation on the observational plane, with the added space and thrust necessary to carry these materials to the stratosphere and release them. It has a wider wingspan and swaps out those solar panels for a pair of Rolls-Royce AE 3007 engines.
The aircraft would also include a detachable tank that would function something like a trailer on a semi. This would make it possible to load materials between flights and prevent any damage to the plane itself from those materials, some of which are corrosive, Langford says.
He says he and his team have completed the initial designs and are now doing more detailed engineering and cost analyses. They intend to publish the findings when the effort is complete.
“We’d love to build a prototype of such an airplane and feel we could do so relatively quickly,” Langford says. “But that all depends on what David’s group wants to do.”
The program
David Keith’s group, CSEi, is still coming together.
The University of Chicago unveiled the research initiative in 2024 and has committed to hiring 10 additional faculty members to advance scientific understanding of various forms of geoengineering and explore the thorny questions related to policy, ethics, and governance. It had hiredtwo of them as of press time.
The university saw an opportunity to step up as a leader in a field that wasn’t getting adequate academic attention despite its potential to address the dangers of climate change, says Michael Greenstone, a climate economist and the founding director of the university’s Institute for Climate and Sustainable Growth.
“Universities, as a whole, were committing academic malpractice by not investigating the technical, the social, the political, and the even kind of humanist elements of geoengineering,” Greenstone says.
He helped recruit Keith to lead the initiative.
Keith, 62, previously spent nearly 13 years as a professor of applied physics and public policy at Harvard, where he led the establishment of the university’s Solar Geoengineering Research Program. More famously, he strove to carry out what could have been the first solar geoengineering experiment to release material in the stratosphere, known as SCoPEx. But after years of work and multiple delays, the research team finally scrapped the project in early 2024, following mounting criticism from environmental and Indigenous groups and the eventual intervention of the Swedish government.
Keith has long argued that researchers should seriously study geoengineering because it might substantially reduce the dangers of climate change, alleviating death, destruction, and suffering on massive scales.
He says that the overarching goal of the Chicago initiative is to expand the field by bringing together “enough independent professors and other research professionals” to “build a community around climate engineering as a broad field of inquiry.”
“Solar geoengineering certainly has complex and potentially dangerous political consequences, but so do a host of other emerging ideas and technologies.” David Keith, geoengineering researcher
“The University of Chicago was the first big university to try and build this as a field in a serious way, to make it not about one person,” he tells me. “It’s a giant commitment.”
Keith himself has become a divisive figure, the face of geoengineering to some. He says he now wants to help build a larger, sustainable research program that will outlive his involvement. He told the administrators that he shouldn’t run the program for more than five years.
“It’s important to have a generational handover,” he says, adding: “I think it’s really important that this not be ‘the David Keith Show.’”
The CSEi researchers are now exploring nearly every engineering challenge that Reflective highlighted in its analysis. In addition to the work on novel aircraft and in situ observations, the group is designing small “cube” satellites with optical sensors optimized for observing the stratosphere. It is also studying which materials might prove most practical to ship to the stratosphere and how best to release them.
The goal is “producing public information which can be independently assessed, critically assessed, so policymakers can understand more about what’s possible and not,” Keith says.
Normalizing a dangerous idea
The debate around solar geoengineering is quickly moving beyond the academic and theoretical realm. A handful of startups, some more serious than others, have begun testing technologies that could one day be used to cool the planet.
Yet to critics, solar geoengineering is the peak of techno-solutionism, affixing a high-tech Band-Aid to a global crisis caused by earlier technologies instead of addressing the root cause. Further, they argue that there’s no way to deploy or govern it in a globally equitable way, because any use of it will prove more advantageous to some regions than others.
Even if solar geoengineering succeeded in reducing the average global temperature by 1 °C or so, that would mean very different things in different regions.
It could keep farmers prosperous and cities safe across, say, much of the US and the world’s temperate zones. But the lower temperature might be too cool for Russia to boost its agricultural productivity, while it might still be too hot for subsistence farming in northern Africa.
Some studies also suggest that high levels of solar geoengineering could create new dangers in some regions, potentially altering monsoon rains, decreasing agricultural output, shifting the range of infectious diseases, and more.
These complications raise a long list of thorny and divisive ethical questions. Even if solar geoengineering produced better conditions across most of the planet relative to a world with unchecked climate change, would it still be acceptable if it unleashed deadly famines or floods in a few regions? What kind of global consensus should be required to decide it’s okay to deploy it? And how should we determine where to set the planet’s temperature—and when, if ever, to shut the technology off?
Stephens argues that the answers, like so much else in the world, will come down to wealth and power. Countries, corporations, or even wealthy individuals with the resources to deploy such a system would have every incentive to tune it for their optimal benefit, no matter what it might mean for others.
“It will be certain people who have a lot of wealth and power deciding when and how, and who should benefit and who will get screwed,” she says. “That’s the fundamental reason I think any advance in this technology is so dangerous.”
Duncan McLaren, an environmental researcher and political scientist, argues that the shift into practical engineering studies demands more oversight of the research field.
For many critics of outdoor experiments like SCoPEx, he explains, the major concern wasn’t the environmental or safety risks, which were minimal; the issue was the normalization of a concept that could reduce pressures to cut greenhouse-gas emissions.
He says that any advance in research—whether it’s on paper, in the lab, or in the stratosphere—raises a similar risk: undermining progress on climate action by allowing the fossil-fuel sector and other business interests to say there’s an easier solution in development that doesn’t require overhauling our energy systems. A policy paper that the Texas Conservative Coalition Research Institute released in March advanced this very argument, citing the far lower costs of solar geoengineering relative to the “staggering costs” of a “forced transition.”
Given this so-called moral hazard risk, design and engineering work should demand the same level of scientific supervision that outdoor experiments do, including ethical review, risk assessments, and public engagement, McLaren says.
“It ought to be more onerous,” he says. “There ought to be more barriers to researchers saying they want to do this.”
“The next ethical step”
Keith pushes back forcefully on that assertion, condemning as “profoundly illiberal” the idea that we should regulate open academic research posing no physical risks.
“Solar geoengineering certainly has complex and potentially dangerous political consequences, but so do a host of other emerging ideas and technologies,” he said in an email. “The best chance to manage these challenges is to debate them openly and freely.”
Keith is all for keeping solar geoengineering technology in the public domain, and he agrees that the first line of climate defense must be rapid and deep reduction of greenhouse-gas emissions. But the world has made little progress in cutting climate pollution, carbon dioxide can persist for thousands of years in the atmosphere, and the planet is heating up fast. So, he argues, we may need to pursue other measures to temper the growing threats.
The bar for restricting research in this field should be “very high,” he says, given the potential promise of the technology.
After visiting flood-devastated villages in Bangladesh, Keith underscored this point in an interview with the director of Plan C for Civilization, a recent documentary that profiles his work. “I think people have to take the next ethical step,” he said. “Because if you are really going to withhold access to and knowledge of a technology that could potentially save enormous numbers of lives—real lives, people we’ve met in the last few days—you’ve got to be very confident that that technology is going to be misused.”
The particles
Mingyi Wang, an assistant professor at the University of Chicago, leads me down the hall to a square, white lab room in the Henry Hinds Laboratory for Geophysical Sciences.
He pulls open the doors to a gray Haier biomedical freezer just inside the entrance, revealing a transparent flow tube hanging vertically and tapering at the bottom.
It’s a miniature stratosphere, chilled below −50 °C and filled with the same mix of oxygen, nitrogen, and other air molecules you’d find 20 or so kilometers above us. A series of Teflon and stainless-steel tubes run into the vessel, allowing Wang and his team to add various gases or particles and observe how they react.
Wang is an atmospheric scientist who studies how aerosols form, and he is now exploring what materials might be the most effective for reducing temperatures.
This rendering illustrates the type of high-altitude aircraft that could one day be used to deliver Earth-cooling material into the stratosphere.
Most modeling experiments focusing on solar geoengineering explore the impact of adding sulfuric acid to the stratosphere, because that’s what ultimately ends up there after a volcanic blast.
But it would be costly and complicated to simply haul sulfuric acid up there and release it, because it’s heavy and sticky. So Wang and his team are conducting experiments in that chilly flow tube to determine what substances, including precursors to the acid, might do the best job of producing aerosols of the ideal size for reflecting away sunlight—and how best to prevent the materials from simply clumping together with existing particles and falling out of the stratosphere.
Wang, whom Keith refers to as a “young star,” has arrived at a novel solution to this problem, though he’s not ready to share the full details yet. He and his team are feeding the findings from their experiments into computer simulations of stratospheric plumes that they’ve developed. These, in turn, can be plugged into large-scale climate models to improve their simulation of smaller-scale effects—and thus enhance our understanding of stratospheric chemistry.
Wang says that it’s important to do this detailed research because until now, climate models simply assumed you’d wind up with the right aerosols of the right size.
“Scientifically, we may understand it reasonably well, but on the engineering perspective—do we really know how to do it right?” he asks. “That’s a big question.”
What’s next
As I began reporting on CSEi, I assumed that some of the engineering and design work would lead to new proposals for stratospheric experiments, picking up from where SCoPEx left off.
Keith, though, insists he has no interest in reliving that experience, given the weight the experiment took on as the focal point for a broader societal debate over solar geoengineering. He doesn’t see any of the other “practical engineering” work at the initiative leading toward field experiments either, at least at this stage.
Much of the work, in fact, is focused on a step beyond that: exploring what it would take to start a geoengineering campaign, if a nation or group of them eventually decides to. Franke notes that we already have balloons and other aircraft that could get to the lower bounds of the stratosphere to release an experimental amount of, say, sulfur dioxide.
“We’re thinking of it right now as: We’re trying to develop, we think, the tools should someone want to start doing SAI,” he says.
He and Keith are quick to stress that the research group does not intend to actually build the physical hardware that would be needed to deploy solar geoengineering—not even the aircraft that Langford’s company is designing.
Indeed, most of the researchers at the University of Chicago stress that they are not advocating for use of geoengineering; they’re doing the research to inform the public and policymakers about its benefits and risks.
But after decades closely studying the topic, Keith, at least, has evolved in his thinking on this point, and his public comments reflect that.
“As a scientist, I think the evidence [indicates] that early deployment—careful, hemispherically balanced, slow, monitored early deployment—would have benefits that are higher than the risks,” he says. “I think that evidence is very strong.”
Keith adds that if there were somehow a global referendum on whether to start, he would vote yes.
“I think that this field needs to stop being so ashamed of using the ‘deployment’ word,” he says.
AI forecast models offer some clear benefits over traditional physical models, but they are ill-equipped to handle the increasing volatility of a warming climate.
On November 12, 1970, the Bhola cyclone slammed into the coast of what was then East Pakistan. The storm brought maximum sustained wind speeds of 130 miles per hour (205 kilometers per hour) and a 35-foot (10.5-meter) storm surge, killing an estimated 300,000 to 500,000 people.
Today, the Bhola cyclone remains the deadliest tropical storm on record. But if it had struck a decade later, it might not have been so devastating. Weather forecasting changed dramatically in the 1970s as meteorologists adopted physics-based computer models that improved storm prediction. With the rise of AI, forecasting is evolving again—but this time, experts worry the new models may be less reliable when it comes to predicting unprecedented weather events.
Researchers are calling this the “gray swan” problem. Gray swan weather extremes are physically plausible but so rare that they are poorly represented in training datasets. The trouble is, climate change is leading to more first-of-their-kind weather extremes. Think: the 2021 Pacific Northwest heatwave. This event was so severe that it would have been virtually impossible without climate change.
Physical forecast models can simulate gray swan events like the Pacific Northwest heatwave, though they are labeled extremely rare. They can do that because they are built on the laws of physics. AI models are trained on past weather data, wherein gray swans are practically nonexistent.
“They fail on gray swans,” Pedram Hassanzadeh, an associate professor of geophysical sciences at the University of Chicago, told Gizmodo. He and his colleagues published a study last April that removed all Category 3 through 5 hurricanes from an AI model’s training dataset, then tested it on Category 5 storms. The results showed that AI models cannot accurately forecast previously unseen events, as this would require extrapolation.
“The concern isn’t occasional misses. It’s that AI models can miss silently, producing confident forecasts of unremarkable weather while a record-breaking event is unfolding,” Rose Yu, an associate professor of computer science and engineering at the University of California San Diego, told Gizmodo in an email.
“Other risks matter too,” she said. “AI models can violate conservation laws in subtle ways that don’t show up in standard metrics. When they bust a forecast, diagnosing why is harder. They depend on stable observing systems, which is a real concern given current pressure on satellite programs. And institutionally, if we consolidate around AI too quickly and let physics-based infrastructure atrophy, we lose the redundancy that currently catches AI’s failures.”
The case for AI forecasting
Despite these pitfalls, meteorologists are rapidly adopting AI forecast models, and it’s actually easy to understand why. They’re faster, cheaper, and require far less computational infrastructure than physical models. When it comes to predicting typical weather patterns and events (not gray swans), their accuracy is comparable and improving rapidly.
“The typical rate of progress for most state-of-the-art physical models has been something like a day more accurate per decade, which doesn’t sound like a lot, but that’s consequential,” Andrew Charlton-Perez, a professor of meteorology and head of the School of Mathematical, Physical, and Computational Sciences at the University of Reading, told Gizmodo.
“The rate of accuracy growth for machine learning models has vastly exceeded that,” he said. “They are now competitive, and two-three years ago, they were not even in the same ballpark.”
During the 2025 Atlantic hurricane season, for example, Google DeepMind’s model outperformed nearly every physical model on storm track and intensity. In fact, since 2023, leading AI models such as GraphCast, Pangu-Weather, and the ECMWF’s AIFS have matched or outperformed the best physical models on medium-range forecasting metrics, according to Yu.
AI models are proving especially valuable in parts of the world that lack traditional forecasting resources—regions that are often on the frontlines of climate change. Hassanzadeh co-directed an initiative that provided 38 million farmers across India with AI-based monsoon forecasts, giving them up to four weeks’ advance notice of the rainy season’s onset.
“A lot of countries were left behind in that first revolution of weather forecasting, because [traditional] weather forecasting requires a supercomputer, hundreds of millions of dollars, various fields, workforce, and experts,” Hassanzadeh explained. AI models, by comparison, are far more accessible to lower-income countries.
Filling the knowledge gaps
Still, rapidly adopting these models without addressing the risks would be dangerous, especially in parts of the world highly vulnerable to the impacts of climate change. Shruti Nath, a postdoctoral research associate at the University of Oxford, recently co-authored an editorial calling for more rigorous testing of AI forecast models before public agencies widely adopt them.
“There is still a lot of work to be done in understanding the limits of these models, alongside where they could supplement physical models and why,” she told Gizmodo in an email.
Nath’s editorial outlines a framework for testing AI forecast models that would deliberately withhold a designated set of “iconic” extreme events (like the Pacific Northwest heat wave, for example) from the training dataset. These events would be reserved solely for testing in order to assess the models’ ability to extrapolate unprecedented weather extremes, or gray swans.
Actually implementing this AI Retraining Without Iconic Events (AIRWIE) protocol “would require the meteorological community to agree on which high-impact events constitute a rigorous benchmark,” the editorial states. This would be a great undertaking, but Nath believes most researchers agree that there is an urgent need for this kind of testing.
“We need to be a bit more organized, however, in ensuring that proper protocols can be followed and that robust safeguards are put in place and maintained by the community,” Nath said. “This is difficult when things are in such a hype phase and no one wants to miss out on the bandwagon.”
Other researchers, like Hassanzadeh, are developing ways to teach AI forecast models to predict gray swans. He and his colleagues are investigating whether combining AI systems with “relevant sampling” methods—which allow them to generate samples of gray swan events—can improve the models’ ability to extrapolate unprecedented extremes.
Efforts to understand and address the limitations of AI forecasting will be critical, because there’s no turning back now. AI is already reshaping the way we predict the weather, and as the climate becomes increasingly volatile, meteorologists will need every tool in their arsenal to be sharp and reliable. Despite their current limitations, there is much to gain from continuing to push these systems forward and figuring out how to best integrate them with physical forecasting.
“The research agenda is about making AI models physically consistent, well-calibrated, and robust to distribution shift,” Yu said. “Abandoning this approach because of the gray swan problem means giving up the biggest improvement in forecasting in a generation.”
The climate emulator invites you to explore the controversial climate intervention. I gave it a whirl.
August 23, 2024
James Temple
AI pioneer Andrew Ng has released a simple online tool that allows anyone to tinker with the dials of a solar geoengineering model, exploring what might happen if nations attempt to counteract climate change by spraying reflective particles into the atmosphere.
The concept of solar geoengineering was born from the realization that the planet has cooled in the months following massive volcanic eruptions, including one that occurred in 1991, when Mt. Pinatubo blasted some 20 million tons of sulfur dioxide into the stratosphere. But critics fear that deliberately releasing such materials could harm certain regions of the world, discourage efforts to cut greenhouse-gas emissions, or spark conflicts between nations, among other counterproductive consequences.
The goal of Ng’s emulator, called Planet Parasol, is to invite more people to think about solar geoengineering, explore the potential trade-offs involved in such interventions, and use the results to discuss and debate our options for climate action. The tool, developed in partnership with researchers at Cornell, the University of California, San Diego, and other institutions, also highlights how AI could help advance our understanding of solar geoengineering.
The current version is bare-bones. It allows users to select different emissions scenarios and various quantities of particles that would be released each year, from 25% of a Pinatubo eruption to 125%.
Planet Parasol then displays a pair of diverging lines that represent warming levels globally through 2100. One shows the steady rise in temperatures that would occur without solar geoengineering, and the other indicates how much warming could be reduced under your selected scenario. The model can also highlight regional temperature differences on heat maps.
You can also scribble your own rising, falling, or squiggling line representing different levels of intervention across the decades to see what might happen as reflective aerosols are released.
I tried to simulate what’s known as the “termination shock” scenario, exploring how much temperatures would rise if, for some reason, the world had to suddenly halt or cut back on solar geoengineering after using it at high levels. The sudden surge of warming that could occur afterward is often cited as a risk of geoengineering. The model projects that global temperatures would quickly rise over the following years, though they might take several decades to fully rebound to the curve they would have been on if the nations in this simulation hadn’t conducted such an intervention in the first place.
To be clear, this is an exaggerated scenario, in which I maxed out the warming and the geoengineering. No one is proposing anything like this. I was playing around to see what would happen because, well, that’s what an emulator lets you do.
Emulators are effectively stripped-down climate models. They’re not as precise, since they don’t simulate as many of the planet’s complex, interconnected processes. But they don’t require nearly as much time and computing power to run.
International negotiators and policymakers often use climate emulators, like En-ROADS, to get a quick, rough sense of the impact that potential rules or commitments on greenhouse-gas emissions could have.
The Parasol team wanted to develop a similar tool specifically to allow people to evaluate the potential effects of various solar geoengineering scenarios, says Daniele Visioni, a climate scientist focused on solar geoengineering at Cornell, who contributed to Planet Parasol (as well as an earlier emulator).
Climate models are steadily becoming more powerful, simulating more Earth system processes at higher resolutions, and spitting out more and more information as they do. AI is well suited to help draw meaning and understanding from that data. It’s getting ever better at spotting patterns within huge data sets and predicting outcomes based on them.
But he says he’s been spending more and more of his time exploring the potential of solar geoengineering (sometimes referred to as solar radiation management, or SRM), given the threat of climate change and the role that AI can play in advancing the research field.
There are “many things one can do—and that society broadly should work on—to help address climate change, first and foremost decarbonization,” he wrote in an email. “And SRM is where I’m focusing most of my climate-related efforts right now, given that this is one of the places where engineers and researchers can make a big difference (in addition to decarbonization).”
In a 2022 piece, Ng noted that AI could play several important roles in geoengineering research, including “autonomously piloting high-altitude drones” that would disperse reflective particles, modeling effects of geoengineering across specific regions, and optimizing techniques.
Planet Parasol itself is built on top of another climate emulator, developed by researchers at the University of Leeds and the University of Oxford, that relies on the rules of physics to project global average temperatures under various scenarios. Ng’s team then harnessed machine learning to estimate the local cooling effects that could result from varying levels of solar geoengineering, says Jeremy Irvin, a grad student in his research group at Stanford.
One of the clearest limits of the current version of the tool, however, is that the results look dazzling. In the scenarios I tested, solar geoengineering cleanly cuts off the predicted rise in temperatures over the coming decades, which it may well do.
That might lead the casual user of such a tool to conclude: Cool, let’s do it!
But even if solar geoengineering does help the world on average, it could still have negative effects, such as harming the protective ozone layer, disturbing regional rainfall patterns, undermining agriculture productivity, and changing the distribution of infectious diseases.
None of that is incorporated in the results as yet. Plus, a climate emulator isn’t equipped to address deeply complex societal concerns. For instance, does researching such possibilities ease pressure to address the root causes of climate change? Can a tool that works at the scale of the planet ever be managed in a globally equitable way? Planet Parasol won’t be able to answer either of those questions.
Holly Buck, an environmental social scientist at the University at Buffalo and author of After Geoengineering, questioned the broader value of such a tool along similar lines.
In focus groups that she has conducted on the topic of solar geoengineering, she’s found that people easily grok the concept that it can curb warming, even without seeing the results plotted out in a model.
“They want to hear about what can go wrong, the impact on precipitation and extreme weather, who will control it, what it means existentially to fail to deal with the root of the problem, and so on,” she said in an email. “So it is hard to imagine who would actually use this and how.”
Visioni explained that the group did make a point of highlighting major challenges and concerns at the top of the page. He added that they intend to improve the tool over time in ways that will provide a fuller sense of the uncertainties, trade-offs, and regional impacts.
“This is hard, and I struggled a lot with your same observation,” Visioni wrote in an email. “But at the same time … I came to the conclusion it’s worth putting something down and work[ing] to improve it with user feedback, rather than wait until we have the perfect, nuanced version.”
As to the value of the tool, Irvin added that seeing the temperature reduction laid out clearly can make a “stronger, lasting impression.”
“We are calling for more research to push the science forward about other areas of concern prior to potential implementation, and we hope the tool helps people understand the capabilities of SAI and support future research on it,” he said.
A different ‘Big One’ is approaching. Climate change is hastening its arrival.
Aug. 12, 2022
California, where earthquakes, droughts and wildfires have shaped life for generations, also faces the growing threat of another kind of calamity, one whose fury would be felt across the entire state.
This one will come from the sky.
According to new research, it will very likely take shape one winter in the Pacific, near Hawaii. No one knows exactly when, but from the vast expanse of tropical air around the Equator, atmospheric currents will pluck out a long tendril of water vapor and funnel it toward the West Coast.
This vapor plume will be enormous, hundreds of miles wide and more than 1,200 miles long, and seething with ferocious winds. It will be carrying so much water that if you converted it all to liquid, its flow would be about 26 times what the Mississippi River discharges into the Gulf of Mexico at any given moment.
When this torpedo of moisture reaches California, it will crash into the mountains and be forced upward. This will cool its payload of vapor and kick off weeks and waves of rain and snow.
The coming superstorm — really, a rapid procession of what scientists call atmospheric rivers — will be the ultimate test of the dams, levees and bypasses California has built to impound nature’s might.
But in a state where scarcity of water has long been the central fact of existence, global warming is not only worsening droughts and wildfires. Because warmer air can hold more moisture, atmospheric rivers can carry bigger cargoes of precipitation. The infrastructure design standards, hazard maps and disaster response plans that protected California from flooding in the past might soon be out of date.
As humans burn fossil fuels and heat up the planet, we have already increased the chances each year that California will experience a monthlong, statewide megastorm of this severity to roughly 1 in 50, according to a new study published Friday. (The hypothetical storm visualized here is based on computer modeling from this study.)
In the coming decades, if global average temperatures climb by another 1.8 degrees Fahrenheit, or 1 degree Celsius — and current trends suggest they might — then the likelihood of such storms will go up further, to nearly 1 in 30.
At the same time, the risk of megastorms that are rarer but even stronger, with much fiercer downpours, will rise as well.
These are alarming possibilities. But geological evidence suggests the West has been struck by cataclysmic floods several times over the past millennium, and the new study provides the most advanced look yet at how this threat is evolving in the age of human-caused global warming.
The researchers specifically considered hypothetical storms that are extreme but realistic, and which would probably strain California’s flood preparations. According to their findings, powerful storms that once would not have been expected to occur in an average human lifetime are fast becoming ones with significant risks of happening during the span of a home mortgage.
“We got kind of lucky to avoid it in the 20th century,” said Daniel L. Swain, a climate scientist at the University of California, Los Angeles, who prepared the new study with Xingying Huang of the National Center for Atmospheric Research in Boulder, Colo. “I would be very surprised to avoid it occurring in the 21st.”
Unlike a giant earthquake, the other “Big One” threatening California, an atmospheric river superstorm will not sneak up on the state. Forecasters can now spot incoming atmospheric rivers five days to a week in advance, though they don’t always know exactly where they’ll hit or how intense they’ll be.
Using Dr. Huang and Dr. Swain’s findings, California hopes to be ready even earlier. Aided by supercomputers, state officials plan to map out how all that precipitation will work its way through rivers and over land. They will hunt for gaps in evacuation plans and emergency services.
The last time government agencies studied a hypothetical California megaflood, more than a decade ago, they estimated it could cause $725 billion in property damage and economic disruption. That was three times the projected fallout from a severe San Andreas Fault earthquake, and five times the economic damage from Hurricane Katrina, which left much of New Orleans underwater for weeks in 2005.
Dr. Swain and Dr. Huang have handed California a new script for what could be one of its most challenging months in history. Now begin the dress rehearsals.
“Mother Nature has no obligation to wait for us,” said Michael Anderson, California’s state climatologist.
In fact, nature has not been wasting any time testing California’s defenses. And when it comes to risks to the water system, carbon dioxide in the atmosphere is hardly the state’s only foe.
THE ULTIMATE CURVEBALL
On Feb. 12, 2017, almost 190,000 people living north of Sacramento received an urgent order: Get out. Now. Part of the tallest dam in America was verging on collapse.
That day, Ronald Stork was in another part of the state, where he was worrying about precisely this kind of disaster — at a different dam.
Standing with binoculars near California’s New Exchequer Dam, he dreaded what might happen if large amounts of water were ever sent through the dam’s spillways. Mr. Stork, a policy expert with the conservation group Friends of the River, had seen on a previous visit to Exchequer that the nearby earth was fractured and could be easily eroded. If enough water rushed through, it might cause major erosion and destabilize the spillways.
He only learned later that his fears were playing out in real time, 150 miles north. At the Oroville Dam, a 770-foot-tall facility built in the 1960s, water from atmospheric rivers was washing away the soil and rock beneath the dam’s emergency spillway, which is essentially a hillside next to the main chute that acts like an overflow drain in a bathtub. The top of the emergency spillway looked like it might buckle, which would send a wall of water cascading toward the cities below.
Mr. Stork had no idea this was happening until he got home to Sacramento and found his neighbor in a panic. The neighbor’s mother lived downriver from Oroville. She didn’t drive anymore. How was he going to get her out?
Mr. Stork had filed motions and written letters to officials, starting in 2001, about vulnerabilities at Oroville. People were now in danger because nobody had listened. “It was nearly soul crushing,” he said.
“With flood hazard, it’s never the fastball that hits you,” said Nicholas Pinter, an earth scientist at the University of California, Davis. “It’s the curveball that comes from a direction you don’t anticipate. And Oroville was one of those.”
Ronald Stork in his office at Friends of the River in Sacramento.
The spillway of the New Exchequer Dam.
Such perils had lurked at Oroville for so long because California’s Department of Water Resources had been “overconfident and complacent” about its infrastructure, tending to react to problems rather than pre-empt them, independent investigators later wrote in a report. It is not clear this culture is changing, even as the 21st-century climate threatens to test the state’s aging dams in new ways. One recent study estimated that climate change had boosted precipitation from the 2017 storms at Oroville by up to 15 percent.
A year and a half after the crisis, crews were busy rebuilding Oroville’s emergency spillway when the federal hydropower regulator wrote to the state with some unsettling news: The reconstructed emergency spillway will not be big enough to safely handle the “probable maximum flood,” or the largest amount of water that might ever fall there.
Sources: Global Historical Climatology Network, Huang and Swain (2022) Measurements taken from the Oroville weather station and the nearest modeled data point
This is the standard most major hydroelectric projects in the United States have to meet. The idea is that spillways should basically never fail because of excessive rain.
Today, scientists say they believe climate change might be increasing “probable maximum” precipitation levels at many dams. When the Oroville evacuation was ordered in 2017, nowhere near that much water had been flowing through the dam’s emergency spillway.
Yet California officials have downplayed these concerns about the capacity of Oroville’s emergency spillway, which were raised by the Federal Energy Regulatory Commission. Such extreme flows are a “remote” possibility, they argued in a letter last year. Therefore, further upgrades at Oroville aren’t urgently needed.
In a curt reply last month, the commission said this position was “not acceptable.” It gave the state until mid-September to submit a plan for addressing the issue.
The Department of Water Resources told The Times it would continue studying the matter. The Federal Energy Regulatory Commission declined to comment.
“People could die,” Mr. Stork said. “And it bothers the hell out of me.”
WETTER WET YEARS
Donald G. Sullivan was lying in bed one night, early in his career as a scientist, when he realized his data might hold a startling secret.
For his master’s research at the University of California, Berkeley, he had sampled the sediment beneath a remote lake in the Sacramento Valley and was hoping to study the history of vegetation in the area. But a lot of the pollen in his sediment cores didn’t seem to be from nearby. How had it gotten there?
When he X-rayed the cores, he found layers where the sediment was denser. Maybe, he surmised, these layers were filled with sand and silt that had washed in during floods.
It was only late that night that he tried to estimate the ages of the layers. They lined up neatly with other records of West Coast megafloods.
“That’s when it clicked,” said Dr. Sullivan, who is now at the University of Denver.
His findings, from 1982, showed that major floods hadn’t been exceptionally rare occurrences over the past eight centuries. They took place every 100 to 200 years. And in the decades since, advancements in modeling have helped scientists evaluate how quickly the risks are rising because of climate change.
For their new study, which was published in the journal Science Advances, Dr. Huang and Dr. Swain replayed portions of the 20th and 21st centuries using 40 simulations of the global climate. Extreme weather events, by definition, don’t occur very often. So by using computer models to create realistic alternate histories of the past, present and future climate, scientists can study a longer record of events than the real world offers.
Dr. Swain and Dr. Huang looked at all the monthlong California storms that took place during two time segments in the simulations, one in the recent past and the other in a future with high global warming, and chose one of the most intense events from each period. They then used a weather model to produce detailed play-by-plays of where and when the storms dump their water.
Those details matter. There are “so many different factors” that make an atmospheric river deadly or benign, Dr. Huang said.
Xingying Huang of the National Center for Atmospheric Research in Boulder, Colo. Rachel Woolf for The New York Times
The New Don Pedro Dam spillway.
Wes Monier, a hydrologist, with a 1997 photo of water rushing through the New Don Pedro Reservoir spillway.
In the high Sierras, for example, atmospheric rivers today largely bring snow. But higher temperatures are shifting the balance toward rain. Some of this rain can fall on snowpack that accumulated earlier, melting it and sending even more water toward towns and cities below.
Climate change might be affecting atmospheric rivers in other ways, too, said F. Martin Ralph of the Scripps Institution of Oceanography at the University of California, San Diego. How strong their winds are, for instance. Or how long they last: Some storms stall, barraging an area for days on end, while others blow through quickly.
Scientists are also working to improve atmospheric river forecasts, which is no easy task as the West experiences increasingly sharp shifts from very dry conditions to very wet and back again. In October, strong storms broke records in Sacramento and other places. Yet this January through March was the driest in the Sierra Nevada in more than a century.
“My scientific gut says there’s change happening,” Dr. Ralph said. “And we just haven’t quite pinned down how to detect it adequately.”
Better forecasting is already helping California run some of its reservoirs more efficiently, a crucial step toward coping with wetter wet years and drier dry ones.
On the last day of 2016, Wes Monier was looking at forecasts on his iPad and getting a sinking feeling.
Mr. Monier is chief hydrologist for the Turlock Irrigation District, which operates the New Don Pedro Reservoir near Modesto. The Tuolumne River, where the Don Pedro sits, was coming out of its driest four years in a millennium. Now, some terrifying rainfall projections were rolling in.
First, 23.2 inches over the next 16 days. A day later: 28.8 inches. Then 37.1 inches, roughly what the area normally received in a full year.
If Mr. Monier started releasing Don Pedro’s water too quickly, homes and farms downstream would flood. Release too much and he would be accused of squandering water that would be precious come summer.
But the forecasts helped him time his flood releases precisely enough that, after weeks of rain, the water in the dam ended up just shy of capacity. Barely a drop was wasted, although some orchards were flooded, and growers took a financial hit.
The next storm might be even bigger, though. And even the best data and forecasts might not allow Mr. Monier to stop it from causing destruction. “There’s a point there where I can’t do anything,” he said.
KATRINA 2.0
How do you protect a place as vast as California from a storm as colossal as that? Two ways, said David Peterson, a veteran engineer. Change where the water goes, or change where the people are. Ideally, both. But neither is easy.
Firebaugh is a quiet, mostly Hispanic city of 8,100 people, one of many small communities that power the Central Valley’s prodigious agricultural economy. Many residents work at nearby facilities that process almonds, pistachios, garlic and tomatoes.
Firebaugh also sits right on the San Joaquin River.
For a sleepless stretch of early 2017, Ben Gallegos, Firebaugh’s city manager, did little but watch the river rise and debate whether to evacuate half the town. Water from winter storms had already turned the town’s cherished rodeo grounds into a swamp. Now it was threatening homes, schools, churches and the wastewater treatment plant. If that flooded, people would be unable to flush their toilets. Raw sewage would flow down the San Joaquin.
Luckily, the river stopped rising. Still, the experience led Mr. Gallegos to apply for tens of millions in funding for new and improved levees around Firebaugh.
Levees change where the water goes, giving rivers more room to swell before they inundate the land. Levee failures in New Orleans were what turned Katrina into an epochal catastrophe, and after that storm, California toughened levee standards in urbanized areas of the Sacramento and San Joaquin Valleys, two major river basins of the Central Valley.
The idea is to keep people out of places where the levees don’t protect against 200-year storms, or those with a 0.5 percent chance of occurring in any year. To account for rising seas and the shifting climate, California requires that levees be recertified as providing this level of defense at least every 20 years.
Firebaugh, Calif., on the San Joaquin River, is home to 8,100 people and helps power the Central Valley’s agricultural economy.
Ben Gallegos, the Firebaugh city manager.
A 6-year-old’s birthday celebration in Firebaugh.
The problem is that once levees are strengthened, the areas behind them often become particularly attractive for development: fancier homes, bigger buildings, more people. The likelihood of a disaster is reduced, but the consequences, should one strike, are increased.
Federal agencies try to stop this by not funding infrastructure projects that induce growth in flood zones. But “it’s almost impossible to generate the local funds to raise that levee if you don’t facilitate some sort of growth behind the levee,” Mr. Peterson said. “You need that economic activity to pay for the project,” he said. “It puts you in a Catch-22.”
A project to provide 200-year protection to the Mossdale Tract, a large area south of Stockton, one of the San Joaquin Valley’s major cities, has been on pause for years because the Army Corps of Engineers fears it would spur growth, said Chris Elias, executive director of the San Joaquin Area Flood Control Agency, which is leading the project. City planners have agreed to freeze development across thousands of acres, but the Corps still hasn’t given its final blessing.
The Corps and state and local agencies will begin studying how best to protect the area this fall, said Tyler M. Stalker, a spokesman for the Corps’s Sacramento District.
The plodding pace of work in the San Joaquin Valley has set people on edge. At a recent public hearing in Stockton on flood risk, Mr. Elias stood up and highlighted some troubling math.
The Department of Water Resources says up to $30 billion in investment is needed over the next 30 years to keep the Central Valley safe. Yet over the past 15 years, the state managed to spend only $3.5 billion.
“We have to find ways to get ahead of the curve,” Mr. Elias said. “We don’t want to have a Katrina 2.0 play out right here in the heart of Stockton.”
As Mr. Elias waits for projects to be approved and budgets to come through, heat and moisture will continue to churn over the Pacific. Government agencies, battling the forces of inertia, indifference and delay, will make plans and update policies. And Stockton and the Central Valley, which runs through the heart of California, will count down the days and years until the inevitable storm.
The Sacramento-San Joaquin Delta near Stockton, Calif.
Sources
The megastorm simulation is based on the “ARkHist” storm modeled by Huang and Swain, Science Advances (2022), a hypothetical statewide, 30-day atmospheric river storm sequence over California with an approximately 2 percent likelihood of occurring each year in the present climate. Data was generated using the Weather Research and Forecasting model and global climate simulations from the Community Earth System Model Large Ensemble.
The chart of precipitation at Oroville compares cumulative rainfall at the Oroville weather station before the 2017 crisis with cumulative rainfall at the closest data point in ARkHist.
The rainfall visualization compares observed hourly rainfall in December 2016 from the Los Angeles Downtown weather station with rainfall at the closest data point in a hypothetical future megastorm, the ARkFuture scenario in Huang and Swain (2022). This storm would be a rare but plausible event in the second half of the 21st century if nations continue on a path of high greenhouse-gas emissions.
Additional credits
The 3D rainfall visualization and augmented reality effect by Nia Adurogbola, Jeffrey Gray, Evan Grothjan, Lydia Jessup, Max Lauter, Daniel Mangosing, Noah Pisner, James Surdam and Raymond Zhong.
Photo editing by Matt McCann.
Produced by Sarah Graham, Claire O’Neill, Jesse Pesta and Nadja Popovich.
Summary: Drawing on 70 years of historic wind and solar-power data, researchers built an AI model to predict the probability of a network-scale ‘drought,’ when daily production of renewables fell below a target threshold. Under a threshold set at the 30th percentile, when roughly a third of all days are low-production days, the researchers found that Texas could face a daily energy drought for up to four months straight. Batteries would be unable to compensate for a drought of this length, and if the system relied on solar energy alone, the drought could be expected to last twice as long — for eight months.
Renewable energy prices have fallen by more than 70 percent in the last decade, driving more Americans to abandon fossil fuels for greener, less-polluting energy sources. But as wind and solar power continue to make inroads, grid operators may have to plan for large swings in availability.
The warning comes from Upmanu Lall, a professor at Columbia Engineering and the Columbia Climate School who has recently turned his sights from sustainable water use to sustainable renewables in the push toward net-zero carbon emissions.
“Designers of renewable energy systems will need to pay attention to changing wind and solar patterns over weeks, months, and years, the way water managers do,” he said. “You won’t be able to manage variability like this with batteries. You’ll need more capacity.”
In a new modeling study in the journal Patterns, Lall and Columbia PhD student Yash Amonkar, show that solar and wind potential vary widely over days and weeks, not to mention months to years. They focused on Texas, which leads the country in generating electricity from wind power and is the fifth-largest solar producer. Texas also boasts a self-contained grid that’s as big as many countries’, said Lall, making it an ideal laboratory for charting the promise and peril of renewable energy systems.
Drawing on 70 years of historic wind and solar-power data, the researchers built an AI model to predict the probability of a network-scale “drought,” when daily production of renewables fell below a target threshold. Under a threshold set at the 30th percentile, when roughly a third of all days are low-production days, the researchers found that Texas could face a daily energy drought for up to four months straight.
Batteries would be unable to compensate for a drought of this length, said Lall, and if the system relied on solar energy alone, the drought could be expected to last twice as long — for eight months. “These findings suggest that energy planners will have to consider alternate ways of storing or generating electricity, or dramatically increasing the capacity of their renewable systems,” he said.
Anticipating Future ‘Energy’ Droughts — in Texas, and Across the Continental United States
The research began six years ago, when Lall and a former graduate student, David Farnham, examined wind and solar variability at eight U.S. airports, where weather records tend to be longer and more detailed. They wanted to see how much variation could be expected under a hypothetical 100% renewable-energy grid.
The results, which Farnham published in his PhD thesis, weren’t a surprise. Farnham and Lall found that solar and wind potential, like rainfall, is highly variable based on the time of year and the place where wind turbines and solar panels have been sited. Across eight cities, they found that renewable energy potential rose and fell from the long-term average by as much as a third in some seasons.
“We coined the term ‘energy’ droughts since a 10-year cycle with this much variation from the long-term average would be seen as a major drought,” said Lall. “That was the beginning of the energy drought work.”
In the current study, Lall chose to zoom in on Texas, a state well-endowed with both sun and wind. Lall and Amonkar found that persistent renewable energy droughts could last as long as a year even if solar and wind generators were spread across the entire state. The conclusion, Lall said, is that renewables face a storage problem that can only realistically be solved by adding additional capacity or sources of energy.
“In a fully renewable world, we would need to develop nuclear fuel or hydrogen fuel, or carbon recycling, or add much more capacity for generating renewables, if we want to avoid burning fossil fuels,” he said.
In times of low rainfall, water managers keep fresh water flowing through the spigot by tapping municipal reservoirs or underground aquifers. Solar and wind energy systems have no equivalent backup. The batteries used to store excess solar and wind power on exceptionally bright and gusty days hold a charge for only a few hours, and at most, a few days. Hydropower plants provide a potential buffer, said Lall, but not for long enough to carry the system through an extended dry spell of intermittent sun and wind.
“We won’t solve the problem by building a larger network,” he said. “Electric grid operators have a target of 99.99% reliability while water managers strive for 90 percent reliability. You can see what a challenging game this will be for the energy industry, and just how valuable seasonal and longer forecasts could be.”
In the next phase of research, Lall will work with Columbia Engineering professors Vijay Modi and Bolun Xu to see if they can predict both energy droughts and “floods,” when the system generates a surplus of renewables. Armed with these projections, they hope to predict the rise and fall of energy prices.
Journal Reference:
Yash Amonkar, David J. Farnham, Upmanu Lall. A k-nearest neighbor space-time simulator with applications to large-scale wind and solar power modeling. Patterns, 2022; 3 (3): 100454 DOI: 10.1016/j.patter.2022.100454
We can reduce global temperatures faster than we once thought — if we act now
One of the biggest obstacles to avoiding global climate breakdown is that so many people think there’s nothing we can do about it.
They point out that record-breaking heat waves, fires and storms are already devastating communities and economies throughout the world. And they’ve long been told that temperatures will keep rising for decades to come, no matter how many solar panels replace oil derricks or how many meat-eaters go vegetarian. No wonder they think we’re doomed.
But climate science actually doesn’t say this. To the contrary, the best climate science you’ve probably never heard of suggests that humanity can still limit the damage to a fraction of the worst projections if — and, we admit, this is a big if — governments, businesses and all of us take strong action starting now.
For many years, the scientific rule of thumb was that a sizable amount of temperature rise was locked into the Earth’s climate system. Scientists believed — and told policymakers and journalists, who in turn told the public — that even if humanity hypothetically halted all heat-trapping emissions overnight, carbon dioxide’s long lifetime in the atmosphere, combined with the sluggish thermal properties of the oceans, would nevertheless keep global temperatures rising for 30 to 40 more years. Since shifting to a zero-carbon global economy would take at least a decade or two, temperatures were bound to keep rising for at least another half-century.
But guided by subsequent research, scientists dramatically revised that lag time estimate down to as little as three to five years. That is an enormous difference that carries paradigm-shifting and broadly hopeful implications for how people, especially young people, think and feel about the climate emergency and how societies can respond to it.
This revised science means that if humanity slashes emissions to zero, global temperatures will stop rising almost immediately. To be clear, this is not a get-out-of-jail-free card. Global temperatures will not fall if emissions go to zero, so the planet’s ice will keep melting and sea levels will keep rising. But global temperatures will stop their relentless climb, buying humanity time to devise ways to deal with such unavoidable impacts. In short, we are not irrevocably doomed — or at least we don’t have to be, if we take bold, rapid action.
The science we’re referencing was included — but buried — in the United Nations Intergovernmental Panel on Climate Change’s most recent report, issued in August. Indeed, it was first featured in the IPCC’s landmark 2018 report, “Global warming of 1.5 C.”That report’s key finding — that global emissions must fall by 45 percent by 2030 to avoid catastrophic climate disruption — generated headlines declaring that we had “12 years to save the planet.” That 12-year timeline, and the related concept of a “carbon budget” — the amount of carbon that can be burned while still limiting temperature rise to 1.5 degrees Celsius above preindustrial levels — were both rooted in this revised science. Meanwhile, the public and policy worlds have largely neglected the revised science that enabled these very estimates.
Nonscientists can reasonably ask: What made scientists change their minds? Why should we believe their new estimate of a three-to-five-year lag time if their previous estimate of 30 to 40 years is now known to be incorrect? And does this mean the world still must cut emissions in half by 2030 to avoid climate catastrophe?
The short answer to the last question is yes. Remember, temperatures only stop rising once global emissions fall to zero. Currently, emissions are not falling. Instead, humanity continues to pump approximately 36 billion tons of carbon dioxide a year into the atmosphere. The longer it takes to cut those 36 billion tons to zero, the more temperature rise humanity eventually will face. And as the IPCC’s 2018 report made hauntingly clear, pushing temperatures above 1.5 degrees C would cause unspeakable amounts of human suffering, economic loss and social breakdown — and perhaps trigger genuinely irreversible impacts.
Scientists changed their minds about how much warming is locked in because additional research gave them a much better understanding of how the climate system works. Their initial 30-to-40-year estimates were based on relatively simple computer models that treated the concentration of carbon dioxide in the atmosphere as a “control knob” that determines temperature levels. The long lag in the warming impact is due to the oceans, which continue to warm long after the control knob is turned up. More recent climate models account for the more dynamic nature of carbon emissions. Yes, CO2 pushes temperatures higher, but carbon “sinks,” including forests and in particular the oceans, absorb almost half of the CO2 that is emitted, causing atmospheric CO2 levels to drop, offsetting the delayed warming effect.
Knowing that 30 more years of rising temperatures are not necessarily locked in can be a game-changer for how people, governments and businesses respond to the climate crisis. Understanding that we can still save our civilization if we take strong, fast action can banish the psychological despair that paralyzes people and instead motivate them to get involved. Lifestyle changes can help, but that involvement must also include political engagement. Slashing emissions in half by 2030 demands the fastest possible transition away from today’s fossil-fueled economies in favor of wind, solar and other non-carbon alternatives. That can happen only if governments enact dramatically different policies. If citizens understand that things aren’t hopeless, they can better push elected officials to make such changes.
As important as minimizing temperature rise is to the United States, where last year’s record wildfires in California and the Pacific Northwest illustrated just how deadly climate change can be, it matters most in the highly climate-vulnerable communities throughout the global South. Countless people in Bangladesh, the Philippines, Madagascar, Africa’s Sahel nations, Brazil, Honduras and other low-income countries have already been suffering from climate disasters for decades because their communities tend to be more exposed to climate impacts and have less financial capacity to protect themselves. For millions of people in such countries, limiting temperature rise to 1.5 degrees C is not a scientific abstraction.
The IPCC’s next report, due for release Feb. 28, will address how societies can adapt to the temperature rise now underway and the fires, storms and rising seas it unleashes. If we want a livable future for today’s young people, temperature rise must be kept as close as possible to 1.5 C. The best climate science most people have never heard of says that goal remains within reach. The question is whether enough of us will act on that knowledge in time.
With global warming no longer just a threat but a full-blown crisis, Columbia experts are on the frontlines, documenting the dangers and developing solutions.
1. More scientists are investigating ways to help people adapt
Over the past half century, thousands of scientists around the world have dedicated their careers to documenting the link between climate change and human activity. A remarkable amount of this work has been done at Columbia’s Lamont-Doherty Earth Observatory, in Palisades, New York. Indeed, one of the founders of modern climate science, the late Columbia geochemist Wally Broecker ’53CC, ’58GSAS, popularized the term “global warming” and first alerted the broader scientific community to the emerging climate crisis in a landmark 1975 paper. He and other Columbia researchers then set about demonstrating that rising global temperatures could not be explained by the earth’s natural long-term climate cycles. For evidence, they relied heavily on Columbia’s world-class collections of tree-ring samples and deep-sea sediment cores, which together provide a unique window into the earth’s climate history.
Today, experts say, the field of climate science is in transition. Having settled the question of whether humans are causing climate change — the evidence is “unequivocal,” according to the UN’s Intergovernmental Panel on Climate Change (IPCC) — many scientists have been branching out into new areas, investigating the myriad ways that global warming is affecting our lives. Columbia scholars from fields as diverse as public health, agriculture, economics, law, political science, urban planning, finance, and engineering are now teaming up with climate scientists to learn how communities can adapt to the immense challenges they are likely to confront.
The University is taking bold steps to support such interdisciplinary thinking. Its new Columbia Climate School, established last year, is designed to serve as a hub for research and education on climate sustainability. Here a new generation of students will be trained to find creative solutions to the climate crisis. Its scholars are asking questions such as: How can communities best protect themselves from rising sea levels and intensifying storm surges, droughts, and heat waves? When extreme weather occurs, what segments of society are most vulnerable? And what types of public policies and ethical principles are needed to ensure fair and equitable adaptation strategies? At the same time, Columbia engineers, physicists, chemists, data scientists, and others are working with entrepreneurs to develop the new technologies that are urgently needed to scale up renewable-energy systems and curb emissions.
“The challenges that we’re facing with climate change are so huge, and so incredibly complex, that we need to bring people together from across the entire University to tackle them,” says Alex Halliday, the founding dean of the Columbia Climate School and the director of the Earth Institute. “Success will mean bringing the resources, knowledge, and capacity of Columbia to the rest of the world and guiding society toward a more sustainable future.”
For climate scientists who have been at the forefront of efforts to document the effects of fossil-fuel emissions on our planet, the shift toward helping people adapt to climate change presents new scientific challenges, as well as the opportunity to translate years of basic research into practical, real-world solutions.
“A lot of climate research has traditionally looked at how the earth’s climate system operates at a global scale and predicted how a given amount of greenhouse-gas emissions will affect global temperatures,” says Adam Sobel, a Columbia applied physicist, mathematician, and climate scientist. “The more urgent questions we face now involve how climate hazards vary across the planet, at local or regional scales, and how those variations translate into specific risks to human society. We also need to learn to communicate climate risks in ways that can facilitate actions to reduce them. This is where climate scientists need to focus more of our energy now, if we’re to maximize the social value of our work.”
A firefighter battles the Caldor Fire in Grizzly Flats, California, last summer. (Fred Greaves / Reuters)
2. Big data will enable us to predict extreme weather
Just a few years ago, scientists couldn’t say with any confidence how climate change was affecting storms, floods, droughts, and other extreme weather around the world. But now, armed with unprecedented amounts of real-time and historical weather data, powerful new supercomputers, and a rapidly evolving understanding of how different parts of our climate system interact, researchers are routinely spotting the fingerprints of global warming on our weather.
“Of course, no individual weather event can be attributed solely to climate change, because weather systems are highly dynamic and subject to natural variability,” says Sobel, who studies global warming’s impact on extreme weather. “But data analysis clearly shows that global warming is tilting the scales of nature in a way that is increasing both the frequency and intensity of certain types of events, including heat waves, droughts, and floods.”
According to the World Meteorological Organization, the total number of major weather-related disasters to hit the world annually has increased five-fold since the 1970s. In 2021, the US alone endured eighteen weather-related disasters that caused at least $1 billion in damages. Those included Hurricanes Ida and Nicholas; tropical storms Fred and Elsa; a series of thunderstorms that devastated broad swaths of the Midwest; floods that overwhelmed the coasts of Texas and Louisiana; and a patchwork of wildfires that destroyed parts of California, Oregon, Washington, Idaho, Montana, and Arizona. In 2020, twenty-two $1 billion events struck this country — the most ever.
“The pace and magnitude of the weather disasters we’ve seen over the past couple of years are just bonkers,” says Sobel, who studies the atmospheric dynamics behind hurricanes. (He notes that while hurricanes are growing stronger as a result of climate change, scientists are not yet sure if they are becoming more common.) “Everybody I know who studies this stuff is absolutely stunned by it. When non-scientists ask me what I think about the weather these days, I say, ‘If it makes you worried for the future, it should, because the long-term trend is terrifying.’”
The increasing ferocity of our weather, scientists say, is partly attributable to the fact that warmer air can hold more moisture. This means that more water is evaporating off oceans, lakes, and rivers and accumulating in the sky, resulting in heavier rainstorms. And since hot air also wicks moisture out of soil and vegetation, regions that tend to receive less rainfall, like the American West, North Africa, the Middle East, and Central Asia, are increasingly prone to drought and all its attendant risks. “Climate change is generally making wet areas wetter and dry regions drier,” Sobel says.
Flooding killed at least three hundred people in China’s Henan Province in July. (Cai Yang / Xinhua via Getty Images)
But global warming is also altering the earth’s climate system in more profound ways. Columbia glaciologist Marco Tedesco, among others, has found evidence that rising temperatures in the Arctic are weakening the North Atlantic jet stream, a band of westerly winds that influence much of the Northern Hemisphere’s weather. These winds are produced when cold air from the Arctic clashes with warm air coming up from the tropics. But because the Arctic is warming much faster than the rest of the world, the temperature differential between these air flows is diminishing and causing the jet stream to slow down and follow a more wobbly path. As a result, scientists have discovered, storm systems and pockets of hot or cold air that would ordinarily be pushed along quickly by the jet stream are now sometimes hovering over particular locations for days, amplifying their impact. Experts say that the jet stream’s new snail-like pace may explain why a heavy rainstorm parked itself over Zhengzhou, China, for three days last July, dumping an entire year’s worth of precipitation, and why a heat wave that same month brought 120-degree temperatures and killed an estimated 1,400 people in the northwestern US and western Canada.
Many Columbia scientists are pursuing research projects aimed at helping communities prepare for floods, droughts, heat waves, and other threats. Sobel and his colleagues, for example, have been using their knowledge of hurricane dynamics to develop an open-source computer-based risk-assessment model that could help policymakers in coastal cities from New Orleans to Mumbai assess their vulnerability to cyclones as sea levels rise and storms grow stronger. “The goal is to create analytic tools that will reveal how much wind and flood damage would likely occur under different future climate scenarios, as well as the human and economic toll,” says Sobel, whose team has sought input from public-health researchers, urban planners, disaster-management specialists, and civil engineers and is currently collaborating with insurance companies as well as the World Bank, the International Red Cross, and the UN Capital Development Fund. “Few coastal cities have high-quality information of this type, which is necessary for making rational adaptation decisions.”
Radley Horton ’07GSAS, another Columbia climatologist who studies weather extremes; Christian Braneon, a Columbia civil engineer and climate scientist; and Kim Knowlton ’05PH and Thomas Matte, Columbia public-health researchers, are members of the New York City Panel on Climate Change, a scientific advisory body that is helping local officials prepare for increased flooding, temperature spikes, and other climate hazards. New York City has acted decisively to mitigate and adapt to climate change, in part by drawing on the expertise of scientists from Columbia and other local institutions, and its city council recently passed a law requiring municipal agencies to develop a comprehensive long-term plan to protect all neighborhoods against climate threats. The legislation encourages the use of natural measures, like wetland restoration and expansion, to defend against rising sea levels. “There’s a growing emphasis on attending to issues of racial justice as the city develops its adaptation strategies,” says Horton. “In part, that means identifying communities that are most vulnerable to climate impacts because of where they’re located or because they lack resources. We want to make sure that everybody is a part of the resilience conversation and has input about what their neighborhoods need.”
Horton is also conducting basic research that he hopes will inform the development of more geographically targeted climate models. For example, in a series of recent papers on the atmospheric and geographic factors that influence heat waves, he and his team discovered that warm regions located near large bodies of water have become susceptible to heat waves of surprising intensity, accompanied by dangerous humidity. His team has previously shown that in some notoriously hot parts of the world — like northern India, Bangladesh, and the Persian Gulf — the cumulative physiological impact of heat and humidity can approach the upper limits of human tolerance. “We’re talking about conditions in which a perfectly healthy person could actually die of the heat, simply by being outside for several hours, even if they’re resting and drinking plenty of water,” says Horton, explaining that when it is extremely humid, the body loses its ability to sufficiently perspire, which is how it cools itself. Now his team suspects that similarly perilous conditions could in the foreseeable future affect people who live near the Mediterranean, the Black Sea, the Caspian Sea, or even the Great Lakes. “Conditions in these places probably won’t be quite as dangerous as what we’re seeing now in South Asia or the Middle East, but people who are old, sick, or working outside will certainly be at far greater risk than they are today,” Horton says. “And communities will be unprepared, which increases the danger.”
How much worse could the weather get? Over the long term, that will depend on us and how decisively we act to reduce our fossil-fuel emissions. But conditions are likely to continue to deteriorate over the next two to three decades no matter what we do, since the greenhouse gases that we have already added to the atmosphere will take years to dissipate. And the latest IPCC report states that every additional increment of warming will have a larger, more destabilizing impact. Of particular concern, the report cautions, is that in the coming years we are bound to experience many more “compound events,” such as when heat waves and droughts combine to fuel forest fires, or when coastal communities get hit by tropical storms and flooding rivers simultaneously.
“A lot of the extreme weather events that we’ve been experiencing lately are so different from anything we’ve seen that nobody saw them coming,” says Horton, who points out that climate models, which remain our best tool for projecting future climate risks, must constantly be updated with new data as real-world conditions change. “What’s happening now is that the conditions are evolving so rapidly that we’re having to work faster, with larger and more detailed data sets, to keep pace.”
Soybean yields in many parts of the world are expected to drop as temperatures rise. (Rory Doyle / Bloomberg via Getty Images)
3. The world’s food supply is under threat
“A warmer world could also be a hungry one, even in the rich countries,” writes the Columbia environmental economist Geoffrey Heal in his latest book, Endangered Economies: How the Neglect of Nature Threatens Our Prosperity. “A small temperature rise and a small increase in CO2 concentrations may be good for crops, but beyond a point that we will reach quickly, the productivity of our present crops will drop, possibly sharply.”
Indeed, a number of studies, including several by Columbia scientists, have found that staple crops like corn, rice, wheat, and soybeans are becoming more difficult to cultivate as the planet warms. Wolfram Schlenker, a Columbia economist who studies the impact of climate change on agriculture, has found that corn and soybean plants exposed to temperatures of 90°F or higher for just a few consecutive days will generate much less yield. Consequently, he has estimated that US output of corn and soybeans could decline by 30 to 80 percent this century, depending on how high average temperatures climb.
“This will reduce food availability and push up prices worldwide, since the US is the largest producer and exporter of these commodities,” Schlenker says.
There is also evidence that climate change is reducing the nutritional value of our food. Lewis Ziska, a Columbia professor of environmental health sciences and an expert on plant physiology, has found that as CO2 levels rise, rice plants are producing grains that contain less protein and fewer vitamins and minerals. “Plant biology is all about balance, and when crops suddenly have access to more CO2 but the same amount of soil nutrients, their chemical composition changes,” he says. “The plants look the same, and they may even grow a little bit faster, but they’re not as good for you. They’re carbon-rich and nutrient-poor.” Ziska says that the molecular changes in rice that he has observed are fairly subtle, but he expects that as CO2 levels continue to rise over the next two to three decades, the changes will become more pronounced and have a significant impact on human health. “Wheat, barley, potatoes, and carrots are also losing some of their nutritional value,” he says. “This is going to affect everybody — but especially people in developing countries who depend on grains like wheat and rice for most of their calories.”
Experts also worry that droughts, heat waves, and floods driven by climate change could destroy harvests across entire regions, causing widespread food shortages. A major UN report coauthored by Columbia climate scientist Cynthia Rosenzweig in 2019 described the growing threat of climate-induced hunger, identifying Africa, South America, and Asia as the areas of greatest susceptibility, in part because global warming is accelerating desertification there. Already, some eight hundred million people around the world are chronically undernourished, and that number could grow by 20 percent as a result of climate change in the coming decades, the report found.
In hopes of reversing this trend, Columbia scientists are now spearheading ambitious efforts to improve the food security of some of the world’s most vulnerable populations. For example, at the International Research Institute for Climate and Society (IRI), which is part of the Earth Institute, multidisciplinary teams of climatologists and social scientists are working in Ethiopia, Senegal, Colombia, Guatemala, Bangladesh, and Vietnam to minimize the types of crop losses that often occur when climate change brings more sporadic rainfall. The IRI experts, whose work is supported by Columbia World Projects, are training local meteorologists, agricultural officials, and farmers to use short-term climate-prediction systems to anticipate when an upcoming season’s growing conditions necessitate using drought-resistant or flood-resistant seeds. They can also suggest more favorable planting schedules. To date, they have helped boost crop yields in dozens of small agricultural communities.
“This is a versatile approach that we’re modeling in six nations, with the hope of rolling it out to many others,” says IRI director John Furlow. “Agriculture still dominates the economies of most developing countries, and in order to succeed despite increasingly erratic weather, farmers need to be able to integrate science into their decision-making.”
South Sudanese refugees gather at a camp in Uganda. (Dan Kitwood / Getty Images)
4. We need to prepare for massive waves of human migration
For thousands of years,the vast majority of the human population has lived in a surprisingly narrow environmental niche, on lands that are fairly close to the equator and offer warm temperatures, ample fresh water, and fertile soils.
But now, suddenly, the environment is changing. The sun’s rays burn hotter, and rainfall is erratic. Some areas are threatened by rising sea levels, and in others the land is turning to dust, forests to kindling. What will people do in the coming years? Will they tough it out and try to adapt, or will they migrate in search of more hospitable territory?
Alex de Sherbinin, a Columbia geographer, is among the first scientists attempting to answer this question empirically. In a series of groundbreaking studies conducted with colleagues at the World Bank, the Potsdam Institute for Climate Impact Research, New York University, Baruch College, and other institutions, he has concluded that enormous waves of human migration will likely occur this century unless governments act quickly to shift their economies away from fossil fuels and thereby slow the pace of global warming. His team’s latest report, published this fall and based on a comprehensive analysis of climatic, demographic, agricultural, and water-use data, predicts that up to 215 million people from Asia, Eastern Europe, Africa, and Latin America — mostly members of agricultural communities, but also some city dwellers on shorelines — will permanently abandon their homes as a result of droughts, crop failures, and sea-level rise by 2050.
“And that’s a conservative estimate,” says de Sherbinin, a senior research scientist at Columbia’s Center for International Earth Science Information Network. “We’re only looking at migration that will occur as the result of the gradual environmental changes occurring where people live, not massive one-time relocations that might be prompted by natural disasters like typhoons or wildfires.”
De Sherbinin and his colleagues do not predict how many climate migrants will ultimately cross international borders in search of greener pastures. Their work to date has focused on anticipating population movements within resource-poor countries in order to help governments develop strategies for preventing exoduses of their own citizens, such as by providing struggling farmers with irrigation systems or crop insurance. They also identify cities that are likely to receive large numbers of new residents from the surrounding countryside, so that local governments can prepare to accommodate them. Among the regions that will see large-scale population movements, the researchers predict, is East Africa, where millions of smallholder farmers will abandon drought-stricken lands and flock to cities like Kampala, Nairobi, and Lilongwe. Similarly, agricultural communities across Latin America, devastated by plummeting corn, bean, and coffee yields, will leave their fields and depart for urban centers. And in Southeast Asia, rice farmers and fishing families in increasingly flood-prone coastal zones like Vietnam’s Mekong Delta, home to twenty-one million people, will retreat inland.
But these migrations, if they do occur, do not necessarily need to be tragic or chaotic affairs, according to de Sherbinin. In fact, he says that with proper planning, and with input from those who are considering moving, it is even possible that large-scale relocations could be organized in ways that ultimately benefit everybody involved, offering families of subsistence farmers who would otherwise face climate-induced food shortages a new start in more fertile locations or in municipalities that offer more education, job training, health care, and other public services.
“Of course, wealthy nations should be doing more to stop climate change and to help people in developing countries adapt to environmental changes, so they have a better chance of thriving where they are,” he says. “But the international community also needs to help poorer countries prepare for these migrations. If and when large numbers of people do find that their lands are no longer habitable, there should be systems in place to help them relocate in ways that work for them, so that they’re not spontaneously fleeing droughts or floods as refugees but are choosing to safely move somewhere they want to go, to a place that’s ready to receive them.”
Temperatures have become especially dangerous in inner cities as a result of the “urban heat island” effect. (Nina Westervelt / Bloomberg via Getty Images)
5. Rising temperatures are already making people sick
One of the deadliest results of climate change, and also one of the most insidious and overlooked, experts say, is the public-health threat posed by rising temperatures and extreme heat.
“Hot weather can trigger changes in the body that have both acute and chronic health consequences,” says Cecilia Sorensen, a Columbia emergency-room physician and public-health researcher. “It actually alters your blood chemistry in ways that make it prone to clotting, which can lead to heart attacks or strokes, and it promotes inflammation, which can contribute to a host of other problems.”
Exposure to severe heat, Sorensen says, has been shown to exacerbate cardiovascular disease, asthma, chronic obstructive pulmonary disease, arthritis, migraines, depression, and anxiety, among other conditions. “So if you live in a hot climate and lack access to air conditioning, or work outdoors, you’re more likely to get sick.”
By destabilizing the natural environment and our relationship to it, climate change is endangering human health in numerous ways. Researchers at Columbia’s Mailman School of Public Health, which launched its innovative Climate and Health Program in 2010, have shown that rising temperatures are making air pollution worse, in part because smog forms faster in warmer weather and because wildfires are spewing enormous amounts of particulate matter into the atmosphere. Global warming is also contributing to food and drinking-water shortages, especially in developing countries. And it is expected to fuel transmission of dengue fever, Lyme disease, West Nile virus, and other diseases by expanding the ranges of mosquitoes and ticks. But experts say that exposure to extreme heat is one of the least understood and fastest growing threats.
“Health-care professionals often fail to notice when heat stress is behind a patient’s chief complaint,” says Sorensen, who directs the Mailman School’s Global Consortium on Climate and Health Education, an initiative launched in 2017 to encourage other schools of public health and medicine to train practitioners to recognize when environmental factors are driving patients’ health problems. “If I’m seeing someone in the ER with neurological symptoms in the middle of a heat wave, for example, I need to quickly figure out whether they’re having a cerebral stroke or a heat stroke, which itself can be fatal if you don’t cool the body down quickly. And then I need to check to see if they’re taking any medications that can cause dehydration or interfere with the body’s ability to cool itself. But these steps aren’t always taken.”
Sorensen says there is evidence to suggest that climate change, in addition to aggravating existing medical conditions, is causing new types of heat-related illnesses to emerge. She points out that tens of thousands of agricultural workers in Central America have died of an enigmatic new kidney ailment that has been dubbed Mesoamerican nephropathy or chronic kidney disease of unknown origin (CKDu), which appears to be the result of persistent heat-induced inflammation. Since CKDu was first observed among sugarcane workers in El Salvador in the 1990s, Sorensen says, it has become endemic in those parts of Central America where heat waves have grown the most ferocious.
“It’s also been spotted among rice farmers in Sri Lanka and laborers in India and Egypt,” says Sorensen, who is collaborating with physicians in Guatemala to develop an occupational-health surveillance system to spot workers who are at risk of developing CKDu. “In total, we think that at least fifty thousand people have died of this condition worldwide.”
Heat waves are now also killing hundreds of Americans each year. Particularly at risk, experts say, are people who live in dense urban neighborhoods that lack trees, open space, reflective rooftops, and other infrastructure that can help dissipate the heat absorbed by asphalt, concrete, and brick. Research has shown that temperatures in such areas can get up to 15°F hotter than in surrounding neighborhoods on summer days. The fact that these so-called “urban heat islands” are inhabited largely by Black and Latino people is now seen as a glaring racial inequity that should be redressed by investing in public-infrastructure projects that would make the neighborhoods cooler and safer.
“It isn’t a coincidence that racially segregated neighborhoods in US cities are much hotter, on average, than adjacent neighborhoods,” says Joan Casey, a Columbia epidemiologist who studies how our natural and built environments influence human health. In fact, in one recent study, Casey and several colleagues showed that urban neighborhoods that lack green space are by and large the same as those that in the 1930s and 1940s were subject to the racist practice known as redlining, in which banks and municipalities designated minority neighborhoods as off-limits for private lending and public investment. “There’s a clear link between that history of institutionalized racism and the subpar public infrastructure we see in these neighborhoods today,” she says.
Extreme heat is hardly the only environmental health hazard faced by residents of historically segregated neighborhoods. Research by Columbia scientists and others has shown that people in these areas are often exposed to dirty air, partly as a result of the large numbers of trucks and buses routed through their streets, and to toxins emanating from industrial sites. But skyrocketing temperatures are exacerbating all of these other health risks, according to Sorensen.
“A big push now among climate scientists and public-health researchers is to gather more street-by-street climate data in major cities so that we know exactly where people are at the greatest risk of heat stress and can more effectively advocate for major infrastructure upgrades in those places,” she says. “In the meantime, there are relatively small things that cities can do now to save lives in the summer — like providing people free air conditioners, opening community cooling centers, and installing more water fountains.”
Workers install solar panels on the roof of a fish-processing plant in Zhoushan, China. (Yao Feng / VCG via Getty Images)
6. We’re curbing emissions but need to act faster
Since the beginning ofthe industrial revolution, humans have caused the planet to warm 1.1°C (or about 2°F), mainly by burning coal, oil, and gas for energy. Current policies put the world on pace to increase global temperatures by about 2.6°C over pre-industrial levels by the end of the century. But to avoid the most catastrophic consequences of climate change, we must try to limit the warming to 1.5°C, scientists say. This will require that we retool our energy systems, dramatically expanding the use of renewable resources and eliminating nearly all greenhouse-gas emissions by mid-century.
“We’ll have to build the equivalent of the world’s largest solar park every day for the next thirty years to get to net zero by 2050,” says Jason Bordoff, co-dean of the Columbia Climate School. A leading energy-policy expert, Bordoff served on the National Security Council of President Barack Obama ’83CC. “We’ll also have to ramp up global investments in clean energy R&D from about $2 trillion to $5 trillion per year,” he adds, citing research from the International Energy Agency. “The challenge is enormous.”
Over the past few years, momentum for a clean-energy transition has been accelerating. In the early 2000s, global emissions were increasing 3 percent each year. Now they are rising just 1 percent annually, on average, with some projections indicating that they will peak in the mid-2020s and then start to decline. This is the result of a variety of policies that countries have taken to wean themselves off fossil fuels. European nations, for example, have set strict limits on industrial emissions. South Africa, Chile, New Zealand, and Canada have taken significant steps to phase out coal-fired power plants. And the US and China have enacted fuel-efficiency standards and invested in the development of renewable solar, wind, and geothermal energy — which, along with hydropower, account for nearly 30 percent of all electricity production in the world.
“It’s remarkable how efficient renewables have become over the past decade,” says Bordoff, noting that the costs of solar and wind power have dropped by roughly 90 percent and 70 percent, respectively, in that time. “They’re now competing quite favorably against fossil fuels in many places, even without government subsidies.”
But in the race to create a carbon-neutral global economy, Bordoff says, the biggest hurdles are ahead of us. He points out that we currently have no affordable ways to decarbonize industries like shipping, trucking, air travel, and cement and steel production, which require immense amounts of energy that renewables cannot yet provide. “About half of all the emission reductions that we’ll need to achieve between now and 2050 must come from technologies that aren’t yet available at commercial scale,” says Bordoff.
In order to fulfill the potential of solar and wind energy, we must also improve the capacity of electrical grids to store power. “We need new types of batteries capable of storing energy for longer durations, so that it’s available even on days when it isn’t sunny or windy,” he says.
Perhaps the biggest challenge, Bordoff says, will be scaling up renewable technologies quickly enough to meet the growing demand for electricity in developing nations, which may otherwise choose to build more coal- and gas-fueled power plants. “There are large numbers of people around the world today who have almost no access to electricity, and who in the coming years are going to want to enjoy some of the basic conveniences that we often take for granted, like refrigeration, Internet access, and air conditioning,” he says. “Finding sustainable ways to meet their energy needs is a matter of equity and justice.”
Bordoff, who is co-leading the new Climate School alongside geochemist Alex Halliday, environmental geographer Ruth DeFries, and marine geologist Maureen Raymo ’89GSAS, is also the founding director of SIPA’s Center on Global Energy Policy, which supports research aimed at identifying evidence-based, actionable solutions to the world’s energy needs. With more than fifty affiliate scholars, the center has, since its creation in 2013, established itself as an intellectual powerhouse in the field of energy policy, publishing a steady stream of definitive reports on topics such as the future of coal; the potential for newer, safer forms of nuclear energy to help combat climate change; and the geopolitical ramifications of the shift away from fossil fuels. One of the center’s more influential publications, Energizing America, from 2020, provides a detailed roadmap for how the US can assert itself as an international leader in clean-energy systems by injecting more federal money into the development of technologies that could help decarbonize industries like construction, transportation, agriculture, and manufacturing. President Joe Biden’s $1 trillion Infrastructure Investment and Jobs Act, signed into law in November, incorporates many of the report’s recommendations, earmarking tens of billions of dollars for scientific research in these areas.
“When we sat down to work on that project, my colleagues and I asked ourselves: If an incoming administration wanted to go really big on climate, what would it do? How much money would you need, and where exactly would you put it?” Bordoff says. “I think that’s one of our successes.”
Which isn’t to say that Bordoff considers the climate initiatives currently being pursued by the Biden administration to be sufficient to combat global warming. The vast majority of the climate-mitigation measures contained in the administration’s first two major legislative packages — the infrastructure plan and the more ambitious Build Back Better social-spending bill, which was still being debated in Congress when this magazine went to press — are designed to reward businesses and consumers for making more sustainable choices, like switching to renewable energy sources and purchasing electric vehicles. A truly transformative climate initiative, Bordoff says, would also discourage excessive use of fossil fuels. “Ideally, you’d want to put a price on emissions, such as with a carbon tax or a gasoline tax, so that the biggest emitters are forced to internalize the social costs they’re imposing on everyone else,” he says.
Bordoff is a pragmatist, though, and ever mindful of the fact that public policy is only as durable as it is popular. “I think the American people are more divided on this than we sometimes appreciate,” he says. “Support for climate action is growing in the US, but we have to be cognizant of how policy affects everyday people. There would be concern, maybe even outrage, if electric or gas bills suddenly increased. And that would make it much, much harder to gain and keep support during this transition.”
Today, researchers from across the entire University are working together to pursue a multitude of strategies that may help alleviate the climate crisis. Some are developing nanomaterials for use in ultra-efficient solar cells. Others are inventing methods to suck CO2 out of the air and pump it underground, where it will eventually turn into chalk. Bordoff gets particularly excited when describing the work of engineers at the Columbia Electrochemical Energy Center who are designing powerful new batteries to store solar and wind power. “This is a team of more than a dozen people who are the top battery experts in the world,” he says. “Not only are they developing technologies to create long-duration batteries, but they’re looking for ways to produce them without having to rely on critical minerals like cobalt and lithium, which are in short supply.”
In his own work, Bordoff has recently been exploring the geopolitical ramifications of the energy transition, with an eye toward helping policymakers navigate the shifting international power dynamics that are likely to occur as attention tilts away from fossil fuels in favor of other natural resources.
But he believes the best ideas will come from the next generation of young people, who, like the students in the Climate School’s inaugural class this year, are demanding a better future. “When I see the growing sense of urgency around the world, especially among the younger demographics, it gives me hope,” he says. “The pressure for change is building. Our climate policies don’t go far enough yet, so something is eventually going to have to give — and I don’t think it’s going to be the will and determination of the young people. Sooner or later, they’re going to help push through the more stringent policies that we need. The question is whether it will be in time.”
In the Salinas Valley, America’s “Salad Bowl,” startups selling machine learning and remote sensing are finding customers.
Rowan Moore Gerety – Dec. 18, 2020
As a machine operator for the robotics startup FarmWise, Diego Alcántar spends each day walking behind a hulking robot that resembles a driverless Zamboni, helping it learn to do the work of a 30-person weeding crew.
On a Tuesday morning in September, I met Alcántar in a gigantic cauliflower field in the hills outside Santa Maria, at the southern end of the vast checkerboard of vegetable farms that line California’s central coast, running from Oxnard north to Salinas and Watsonville. Cooled by coastal mists rolling off the Pacific, the Salinas valley is sometimes called America’s Salad Bowl. Together with two adjacent counties to the south, the area around Salinas produces the vast majority of lettuce grown in the US during the summer months, along with most of the cauliflower, celery, and broccoli, and a good share of the berries.
It was the kind of Goldilocks weather that the central coast is known for—warm but not hot, dry but not parched, with a gentle breeze gliding in from the coast. Nearby, a harvest crew in straw hats and long sleeves was making quick work of an inconceivable quantity of iceberg lettuce, stacking boxes 10 high on the backs of tractor-trailers lining a dirt road.
In another three months, the same scene would unfold in the cauliflower field where Alcántar now stood, surrounded by tens of thousands of two- and three-leaf seedlings. First, though, it had to be weeded.
The robot straddled a planted bed three rows wide with its wheels in adjacent furrows. Alcántar followed a few paces back, holding an iPad with touch-screen controls like a joystick’s. Under the hood, the robot’s cameras flashed constantly. Bursts of air, like the pistons in a whack-a-mole arcade game, guided sets of L-shaped blades in precise, short strokes between the cauliflower seedlings, scraping the soil to uproot tiny weeds and then parting every 12 inches so that only the cauliflower remained, unscathed.
Periodically, Alcántar stopped the machine and kneeled in the furrow, bending to examine a “kill”—spots where the robot’s array of cameras and blades had gone ever so slightly out of alignment and uprooted the seedling itself. Alcántar was averaging about an acre an hour, and only one kill out of every thousand plants. The kills often came in sets of twos and threes, marking spots where one wheel had crept out of the furrow and onto the bed itself, or where the blades had parted a fraction of a second too late.
Taking an iPhone out of his pocket, Alcántar pulled up a Slack channel called #field-de-bugging and sent a note to a colleague 150 miles away about five kills in a row, with a hypothesis about the cause (latency between camera and blade) and a time stamp so he could find the images and see what had gone wrong.
In this field, and many others like it, the ground had been prepared by a machine, the seedlings transplanted by a machine, and the pesticides and fertilizers applied by a machine. Irrigation crews still laid sprinkler pipe manually, and farmworkers would harvest this cauliflower crop when the time came, but it isn’t a stretch to think that one day, no person will ever lay a hand to the ground around these seedlings.
Technology’s race to disrupt one of the planet’s oldest and largest occupations centers on the effort to imitate, and ultimately outdo, the extraordinary powers of two human body parts: the hand, able to use tweezers or hold a baby, catch or throw a football, cut lettuce or pluck a ripe strawberry with its calyx intact; and the eye, which is increasingly being challenged by a potent combination of cloud computing, digital imagery, and machine learning.
The term “ag tech” was coined at a conference in Salinas almost 15 years ago; boosters have been promising a surge of gadgets and software that would remake the farming industry for at least that long. And although ag tech startups have tended to have an easier time finding investors than customers, the boosters may finally be on to something.
Ag tech boosters have been promising a surge of gadgets and software that would remake the farming industry for at least 15 years. They may finally be on to something.
Silicon Valley is just over the hill from Salinas. But by the standards of the Grain Belt, the Salad Bowl is a relative backwater—worth about $10 billion a year, versus nearly $100 billion for commodity crops in the Midwest. Nobody trades lettuce futures like soybean futures; behemoths like Cargill and Conagra mostly stay away. But that’s why the “specialty crop” industry seemed to me like the best place to chart the evolution of precision farming: if tech’s tools can work along California’s central coast, on small plots with short growing cycles, then perhaps they really are ready to stage a broader takeover.
Alcántar, who is 28, was born in Mexico and came to the US as a five-year-old in 1997, walking across the Sonoran Desert into Arizona with his uncle and his younger sister. His parents, who are from the central Mexican state of Michoacán, were busily setting up the ingredients for a new life as farmworkers in Salinas, sleeping in a relative’s walk-in closet before renting a converted garage apartment. Alcántar spent the first year at home, watching TV and looking after his sister while his parents worked: there was a woman living in the main house who checked on them and kept them fed during the day, but no one who could drive them to elementary school.
Workers harvest broccoli as part of a joint project between NASA and the University of California.
In high school, Alcántar often worked as a field hand on the farm where his father had become a foreman. He cut and weeded lettuce, stacked strawberry boxes after the harvest, drove a forklift in the warehouse. But when he turned 22 and saw friends he’d grown up with getting their first jobs after college, he decided he needed a plan to move on from manual labor. He got a commercial driver’s license and went to work for a robotics startup.
During this first stint, Alcántar recalls, relatives sometimes chided him for helping to accelerate a machine takeover in the fields, where stooped, sweaty work had cleared a path for his family’s upward mobility. “You’re taking our jobs away!” they’d say.
Five years later, Alcántar says, the conversation has shifted completely. Even FarmWise has struggled to find people willing to “walk behind the machine,” he says. “People would rather work at a fast food restaurant. In-N-Out is paying $17.50 an hour.”
II
Even up close, all kinds of things can foul the “vision” of the computers that power automated systems like the ones FarmWise uses. It’s hard for a computer to tell, for instance, whether a contiguous splotch of green lettuce leaves represents a single healthy seedling or a “double,” where two seeds germinated next to one another and will therefore stunt each other’s growth. Agricultural fields are bright, hot, and dusty: hardly ideal conditions for keeping computers running smoothly. A wheel gets stuck in the mud and temporarily upends the algorithm’s sense of distance: the left tires have now spun a quarter-turn more than the right tires.
Other ways of digital seeing have their own challenges. For satellites, there’s cloud cover to contend with; for drones and planes, wind and vibration from the engines that keep them aloft. For all three, image-recognition software must take into account the shifting appearance of the same fields at different times of day as the sun moves across the sky. And there’s always a trade-off between resolution and price. Farmers have to pay for drones, planes, or any field machinery. Satellite imagery, which has historically been produced, paid for, and shared freely by public space agencies, has been limited to infrequent images with coarse resolution.
NASA launched the first satellite for agricultural imagery, known as Landsat, in 1972. Clouds and slow download speeds conspired to limit coverage of most of the world’s farmland to a handful of images a year of any given site, with pixels from 30 to 120 meters per side.
A half-dozen more iterations of Landsat followed through the 1980s and ’90s, but it was only in 1999, with the Moderate Resolution Imaging Spectroradiometer, or MODIS, that a satellite could send farmers daily observations over most of the world’s land surface, albeit with a 250-meter pixel. As cameras and computing have improved side by side over the past 20 years, a parade of tech companies have become convinced there’s money to be made in providing insights derived from satellite and aircraft imagery, says Andy French, an expert in water conservation at the USDA’s Arid-Land Agricultural Research Center in Arizona. “They haven’t been successful,” he says. But as the frequency and resolution of satellite images both continue to increase, that could now change very quickly, he believes: “We’ve gone from Landsat going over our head every 16 days to having near-daily, one- to four-meter resolution.”
“We’ve gone from Landsat going over our head every 16 days to having near-daily, one- to four-meter resolution.”
Andy French
In 2014, Monsanto acquired a startup called the Climate Corporation, which billed itself as a “digital farming” company, for a billion dollars. “It was a bunch of Google guys who were experts in satellite imagery, saying ‘Can we make this useful to farmers?’” says Thad Simons, a longtime commodities executive who cofounded a venture capital firm called the Yield Lab. “That got everybody’s attention.”
In the years since, Silicon Valley has sent forth a burst of venture-funded startups whose analytic and forecasting services rely on tools that can gather and process information autonomously or at a distance: not only imagery, but also things like soil sensors and moisture probes. “Once you see the conferences making more money than people actually doing work,” Simons says with a chuckle, “‘you know it’s a hot area.’’
A subset of these companies, like FarmWise, are working on something akin to hand-eye coordination, chasing the perennial goal of automating the most labor-intensive stages of fruit and vegetable farming—weeding and, above all, harvesting—against a backdrop of chronic farm labor shortages. But many others are focused exclusively on giving farmers better information.
One way to understand farming is as a neverending hedge against the uncertainties that affect the bottom line: weather, disease, the optimal dose and timing of fertilizer, pesticides, and irrigation, and huge fluctuations in price. Each one of these factors drives thousands of incremental decisions over the course of a season—decisions based on long years of trial and error, intuition, and hard-won expertise. So the tech question on farmers’ lips everywhere, as Andy French told me, is: “What are you telling us that we didn’t already know?”
III
Josh Ruiz, the vice president of ag operations for Church Brothers, which grows greens for the food service industry, manages more than a thousand separate blocks of farmland covering more than 20,000 acres. Affable, heavy-set, and easy to talk to, Ruiz is known across the industry as an early adopter who’s not afraid to experiment with new technology. Over the last few years, he has become a regular stop on the circuit that brings curious tech executives in Teslas down from San Francisco and Mountain View to stand in a lettuce field and ask questions about the farming business. “Trimble, Bosch, Amazon, Microsoft, Google—you name it, they’re all calling me,” Ruiz says. “You can get my attention real fast if you solve a problem for me, but what happens nine times out of 10 is the tech companies come to me and they solve a problem that wasn’t a problem.”
What everyone wants, in a word, is foresight. For more than a generation, the federal government has sheltered growers of corn, wheat, soybeans, and other commodities from the financial impact of pests and bad weather by offering subsidies to offset the cost of crop insurance and, in times of bountiful harvests, setting an artificial “floor” price at which the government steps in as a buyer of last resort. Fruits and vegetables do not enjoy the same protection: they account for less than 1% of the $25 billion the federal government spends on farm subsidies. As a result, the vegetable market is subject to wild variations based on weather and other only vaguely predictable factors.
Josh Ruiz, the vice president of ag operations at Church Brothers, a greens-growing concern, with “Big Red,” an automated broccoli harvester of his design.
When I visited Salinas, in September, the lettuce industry was in the midst of a banner week price-wise, with whole heads of iceberg and romaine earning shippers as much as $30 a box, or roughly $30,000 an acre. “Right now, you have the chance to lose a fortune and make it back,” Ruiz said as we stood at the edge of a field. The swings can be dramatic: a few weeks earlier, he explained, iceberg was selling for a fraction of that amount—$5 a box, about half what it costs to produce and harvest.
In the next field over, rows of young iceberg lettuce seedlings were ribbed with streaks of tawny brown—the mark of the impatiens necrotic spot virus, or INSV, which has been wreaking havoc on Salinas lettuce since the mid-aughts. These were the early signs. Come back after a couple more weeks, Ruiz said, and half the plants will be dead: it won’t be worthwhile to harvest at all. As it was, that outcome would represent a $5,000 loss, based on the costs of land, plowing, planting, and inputs. If they decided to weed and harvest, that loss could easily double. Ruiz said he wouldn’t have known he was wasting $5,000 if he hadn’t decided to take me on a drive that day. Multiply that across more than 20,000 acres. Assuming a firm could reliably deliver that kind of advance knowledge about INSV, how much would it be worth to him?
One firm trying to find out is an imagery and analytics startup called GeoVisual Analytics, based in Colorado, which is working to refine algorithms that can project likely yields a few weeks ahead of time. It’s a hard thing to model well. A head of lettuce typically sees more than half its growth in the last three weeks before harvest; if it stays in the field just a couple of days longer, it could be too tough or spindly to sell. Any model the company builds has to account for factors like that and more. A ball of iceberg watered at the wrong time swells to a loose bouquet. Supermarket carrots are starved of water to make them longer.
When GeoVisual first got to Salinas, in 2017, “we came in promising the future, and then we didn’t deliver,” says Charles McGregor, its 27-year-old general manager. Ruiz, less charitably, calls their first season an “epic fail.” But he gives McGregor credit for sticking around. “They listened and they fixed it,” he says. He’s just not sure what he’s willing to pay for it.
“We came in promising the future, and then we didn’t deliver.”
Charles McGregor
As it stands, the way field men arrive at yield forecasts is decidedly analog. Some count out heads of lettuce pace by pace and then extrapolate by measuring their boots. Others use a 30-foot section of sprinkler pipe. There’s no way methods like these can match the scale of what a drone or an airplane might capture, but the results have the virtue of a format growers can easily process, and they’re usually off by no more than 25 to 50 boxes an acre, or about 3% to 5%. They’re also part of a farming operation’s baseline expenses: if the same employee spots a broken irrigation valve or an empty fertilizer tank and makes sure the weeding crew starts on time, then asking him to deliver a decent harvest forecast isn’t necessarily an extra cost. By contrast, the pricing of tech-driven forecasts tends to be uneven. Tech salespeople lowball the cost of service in order to get new customers and then, eventually, have to figure out how to make money on what they sell.
“At 10 bucks an acre, I’ll tell [GeoVisual] to fly the whole thing, but at $50 an acre, I have to worry about it,” Ruiz told me. “If it costs me a hundred thousand dollars a year for two years, and then I have that aha! moment, am I gonna get my two hundred thousand dollars back?”
IV
All digital sensing for agriculture is a form of measurement by proxy: a way to translate slices of the electromagnetic spectrum into understanding of biological processes that affect plants. Thermal infrared reflectance correlates with land surface temperature, which correlates with soil moisture and, therefore, the amount of water available to plants’ roots. Measuring reflected waves of green, red, and near-infrared light is one way to estimate canopy cover, which helps researchers track evapotranspiration—that is, how much water evaporates through a plant’s leaves, a process with clear links to plant health.
Improving these chains of extrapolation is a call and response between data generated by new generations of sensors and the software models that help us understand them. Before the launch of the EU’s first Sentinel satellite in 2014, for instance, researchers had some understanding of what synthetic aperture radar, which builds high-resolution images by simulating large antennas, could reveal about plant biomass, but they lacked enough real-world data to validate their models. In the American West, there’s abundant imagery to track the movement of water over irrigated fields, but no crop model sufficiently advanced to reliably help farmers decide when to “order” irrigation water from the Colorado River, which is usually done days ahead of time.
As with any Big Data frontier, part of what’s driving the explosion of interest in ag tech is simply the availability of unprecedented quantities of data. For the first time, technology can deliver snapshots of every individual broccoli crown on a 1,000-acre parcel and show which fields are most likely to see incursions from the deer and wild boars that live in the hills above the Salinas Valley.
The problem is that turning such a firehose of 1s and 0s into any kind of useful insight—producing, say, a text alert about the top five fields with signs of drought stress—requires a more sophisticated understanding of the farming business than many startups seem to have. As Paul Fleming, a longtime farming consultant in Salinas, put it, “We only want to know about the things that didn’t go the way they’re supposed to.”
“We only want to know about the things that didn’t go the way they’re supposed to.”
Paul Fleming
And that’s just the beginning. Retail shippers get paid for each head of cauliflower or bundle of kale they produce; processors, who sell pre-cut broccoli crowns or bags of salad mix, are typically paid by weight. Contract farmers, hired to grow a crop for someone else for a per-acre fee, might never learn whether a given harvest was a “good” or a “bad” one, representing a profit or a loss for the shipper that hired them. It’s often in a shipper’s interest to keep individual farmers in the dark about where they stand relative to their nearby competitors.
In Salinas, the challenge of making big data relevant to farm managers is also about consolidating the universe of information farms already collect—or, perhaps, don’t. Aaron Magenheim, who grew up in his family’s irrigation business and now runs a consultancy focused on farm technology, says the particulars of irrigation, fertilizer, crop rotations, or any number of variables that can influence harvest tend to get lost in the hubbub of the season, if they’re ever captured at all. “Everyone thinks farmers know how they grow, but the reality is they’re pulling it out of the air. They don’t track that down to the lot level,” he told me, using an industry term for an individual tract of farmland. As many as 40 or 50 lots might share the same well and fertilizer tank, with no precise way of accounting for the details. “When you’re applying fertilizer, the reality is it’s a guy opening a valve on a tank and running it for 10 minutes, and saying, ‘Well that looks okay.’ Did Juan block number 6 or number 2 because of a broken pipe? Did they write it down?” Magenheim says. “No! Because they have too many things to do.”
Then there are the maps. Compared with corn and soybean operations, where the same crops get planted year after year, or vineyards and orchards, where plantings may not change for more than a generation, growers of specialty crops deal with a never-ending jigsaw puzzle of romaine following celery following broccoli, with plantings that change size and shape according to the market, and cycles as short as 30 days from seed to harvest.
For many companies in Salinas, the man standing astride the gap between what happens in the field and the record-keeping needs of a modern farming business is a 50-year-old technology consultant named Paul Mariottini. Mariottini—who planned to become a general contractor until he got a computer at age 18 and, as he puts it, “immediately stopped sleeping”—runs a one-man operation out of his home in Hollister, with a flip phone and a suite of bespoke templates and plug-ins he writes for Microsoft Access and Excel. When I asked the growers I met how they handled this part of the business, the reply, to a person, was: “Oh, we use Paul.”
Mariottini’s clients include some of the largest produce companies in the world, but only one uses tablets so that field supervisors can record the acreage and variety of each planting, the type and date of fertilizer and pesticide applications, and other basic facts about the work they supervise while it’s taking place. The rest take notes on paper, or enter the information from memory at the end of the day.
When I asked Mariottini whether anyone used software to link paper maps to the spreadsheets showing what got planted where, he chuckled and said, “I’ve been doing this for 20 years trying to make that happen.” He once programmed a PalmPilot; he calls one of his plug-ins “Close-Enough GPS.” “The tech industry would probably laugh at it, but the thing that the tech industry doesn’t understand is the people you’re working with,” he said.
V
The goal of automation in farming is best understood as all encompassing. The brief weeks of harvest consume a disproportionate share of the overall budget—as much as half the cost of growing some crops. But there are also efforts to optimize and minimize labor throughout the growing cycle. Strawberries are being grown with spray-on, biodegradable weed barriers that could eliminate the need to spread plastic sheeting over every bed. Automated tractors will soon be able to plow vegetable fields to a smoother surface than a human driver could, improving germination rates. Even as analytics companies race to deliver platforms that can track the health of an individual head of lettuce from seed to supermarket and optimize the order in which fields get harvested, other startups are developing new “tapered” varieties of lettuce—similar to romaine—with a compact silhouette and leaves that rest higher off the ground, in order that they might be more easily “seen” and cut by a robot.
Overall, though, the problems with the American food system aren’t about technology so much as law and politics. We’ve known for a long time that the herbicide Roundup is tied to increased cancer rates, yet it remains widely used. We’ve known for more than 100 years that the West is short on water, yet we continue to grow alfalfa in the desert, and use increasingly sophisticated drilling techniques in a kind of water arms race. These are not problems caused by a lack of technology.
On my last day in Salinas, I met a grower named Mark Mason just off Highway 101, which cuts the valley in two, and followed him to a nine-acre block of celery featuring a tidy tower of meteorological equipment in the center. The equipment is owned by NASA, part of a joint project with the University of California’s Agriculture and Natural Resources cooperative extension office, or UCANR.
Eight years ago, amid news of droughts and forest fires across the West, Mason felt a gnawing sense that he ought to be a more careful steward of the groundwater he uses to irrigate, even if the economics suggested otherwise. That led him to contact Michael Cahn, a researcher at UCANR.
Historically, water in Salinas has always been cheap and abundant: the downside of under-irrigating, or of using too little fertilizer, has always been far larger than the potential savings. “Growers want to sell product; efficient use is secondary. They won’t cut it close and risk quality,” Cahn said. The risk might even extend to losing a crop.
Of late, though, nitrate contamination of drinking water, caused by heavy fertilizer use and linked to thyroid disease and some types of cancer, has become a major political issue in Salinas. The local water quality control board is currently developing a new standard that will limit the amount of nitrogen fertilizer growers can apply to their fields, and it’s expected to be finalized in 2021. As Cahn explained, “You can’t control nitrogen without controlling your irrigation water.” In the meantime, Mason and a handful of other growers are working with UCANR on a software platform called Crop Manage, designed to ingest weather and soil data and deliver customized recommendations on irrigation and fertilizer use for each crop.
Michael Cahn, a researcher at the University of California who’s developing software to optimize water and fertilizer use, at a water trial for artichokes.
Cahn says he expects technological advances in water management to follow a course similar to the one being set by the threat of tighter regulations on nitrogen fertilizer. In both cases, the business argument for a fix and the technology required to get there lie somewhere downstream of politics. Outrage over lack of access to clean groundwater brought forth a new regulatory mechanism, which unlocked the funding to figure out how to measure it, and which will, in turn, inform the management approaches farmers use.
In the end, then, it’s political pressure that has created the conditions for science and technology to advance. For now, venture capital and federal research grants continue to provide an artificial boost for ag tech while its potential buyers—such as lettuce growers—continue to treat it with a degree of caution.
But just as new regulations can reshape the cost-benefit analysis around nitrogen or water use from one day to the next, so too can a product that brings clear returns on investment. All the growers I spoke to spend precious time keeping tabs on the startup world: taking phone calls, buying and testing tech-powered services on a sliver of their farms, making suggestions on how to target analytics or tweak a farm-facing app. Why? To have a say in how the future unfolds, or at least to get close enough to see it coming. One day soon, someone will make a lot of money following a computer’s advice about how high to price lettuce, or when to spray for a novel pest, or which fields to harvest and which ones to abandon. When that happens, these farmers want to be the first to know.
Nontraditional hardware could help neural networks operate faster and more efficiently than computer chips
Matthew Hutson – 26 Jan 2022 11:00 AM
The computational layers inside a neural network could be powered by any number of physical systems, researchers say. Philipp Jordan
Imagine using any object around you—a frying pan, a glass paperweight—as the central processor in a neural network, a type of artificial intelligence that loosely mimics the brain to perform complex tasks. That’s the promise of new research that, in theory, could be used to recognize images or speech faster and more efficiently than computer programs that rely on silicon microchips.
“Everything can be a computer,” says Logan Wright, a physicist at Cornell University who co-led the study. “We’re just finding a way to make the hardware physics do what we want.”
Current neural networks usually operate on graphical processing chips. The largest ones perform millions or billions of calculations just to, say, make a chess move or compose a word of prose. Even on specialized chips, that can take lots of time and electricity. But Wright and his colleagues realized physical objects also compute in a passive way, merely by responding to stimuli. Canyons, for example, add echoes to voices without the use of soundboards.
To demonstrate the concept, the researchers built neural networks in three types of physical systems, which each contained up to five processing layers. In each layer of a mechanical system, they used a speaker to vibrate a small metal plate and recorded its output using a microphone. In an optical system, they passed light through crystals. And in an analog-electronic system, they ran current through tiny circuits.
In each case, the researchers encoded input data, such as unlabeled images, in sound, light, or voltage. For each processing layer, they also encoded numerical parameters telling the physical system how to manipulate the data. To train the system, they adjusted the parameters to reduce errors between the system’s predicted image labels and the actual labels.
In one task, they trained the systems, which they call physical neural networks (PNNs), to recognize handwritten digits. In another, the PNNs recognized seven vowel sounds. Accuracy on these tasks ranged from 87% to 97%, they report in this week’s issue of Nature. In the future, Wright says, researchers might tune a system not by digitally tweaking its input parameters, but by adjusting the physical objects—warping the metal plate, say.
Lenka Zdeborová, a physicist and computer scientist at the Swiss Federal Institute of Technology Lausanne who was not involved in the work, says the study is “exciting,” although she would like to see demonstrations on more difficult tasks.
“They did a good job of demonstrating the idea in different contexts,” adds Damien Querlioz, a physicist at CNRS, the French national research agency. “I think it’s going to be quite influential.”
Wright is most excited about PNNs’ potential as smart sensors that can perform computation on the fly. A microscope’s optics might help detect cancerous cells before the light even hits a digital sensor, or a smartphone’s microphone membrane might listen for wake words. These “are applications in which you really don’t think about them as performing a machine-learning computation,” he says, but instead as being “functional machines.”
Climate change is already killing people, but countries don’t have an easy way to count those deaths. A new project might change that.
Climate change can kill people in all kinds of ways. There are the obvious ones—wildfires, storms, and floods—yet rising temperatures may also lead to the increased spread of deadly diseases, make food harder to come by, and increase the risk of conflict.
Although we know about these wide-ranging but equally terrifying risks, attempts to pinpoint the number of deaths caused by climate change have been piecemeal. One recent study estimated that climate change was to blame for 37 percent of heat-related deaths over the past three decades. In 2021, Daniel Bressler, a PhD student at Columbia University in New York, estimated that every additional 4,400 metric tons of carbon dioxide emitted will cause one heat-related death later this century. He called this number the “mortality cost of carbon.”
Putting a number on climate deaths isn’t just an academic exercise. People are already dying because of extreme temperature and weather events, and we can expect this to become more common as the planet continues to heat up. If governments want to put in place policies to prevent these deaths, they need a way of accurately measuring the deaths and ill health linked to warming. The search is on for the true mortality cost of carbon.
As part of this search, the UK government has made its first attempt at putting a number on climate change deaths. The UK Office for National Statistics (ONS)—an independent government agency responsible for producing official data—has for the first time reported climate-related deaths and hospital admissions in England and Wales. The report covers the years 2001 to 2020, but future reports will be released annually, revealing for the first time detailed information about the impact that climate change is having on health in the two nations. (Statistics for Scotland and Northern Ireland are recorded separately.)
The main finding from this investigation is counterintuitive. The report found that the number of deaths associated with warm or cold temperatures actually decreased between 2001 and 2020. On average, 27,755 fewer people were dying each year due to unusually warm or cold temperatures. In other words, climate change might have actually prevented over half a million deaths in England and Wales over this period. In 2001 there were 993 climate-related deaths per 100,000 people in England and Wales. By 2019 that figure had fallen to 771.
But let’s not get ahead of ourselves. There are a number of reasons why the net number of temperature-related deaths appeared to decline over this period, says Myer Glickman, head of the epidemiological, climate, and global health team at the ONS. For a start, statisticians took a relatively narrow definition of climate-related deaths. They only included deaths from conditions where scientists had previously found a clear link between temperature and disease outcome, and they also excluded any health condition where their own analysis showed no link between temperature and outcome. This means that the mortality data doesn’t include deaths from violence or natural forces (such as storms, landslides, or flooding).
The analysis also excluded deaths from air pollution, which Public Health England estimates is equivalent to between 28,000 and 36,000 deaths each year in the UK. Glickman says that there is no accepted way to separate out the effect that temperature increases have on air pollution. Add all these caveats together and it’s likely that the ONS analysis is a little on the conservative side.
Then there is the big reason why climate change has not led to more deaths in England and Wales: the very mild climate. Although average temperatures in the UK have increased by 0.9 degrees compared to the period from 1961 to 1990, its residents are not some of the 3 billion people who face unlivable conditions if greenhouse gas emissions increase rapidly. And while deaths linked to cold weather were down in England and Wales, on warmer days there was a net increase in hospital admissions linked to warmer weather. This was particularly true when it comes to injuries, which may be because more people do outdoor activities when it’s warmer or might be linked to the increases in violence and mental health problems that are associated with warmer temperatures.
The lower rate of deaths might also be a sign that our attempts to fight back against cold weather are working. Widespread flu vaccinations, support for people to pay their heating bills, and increases in home insulation mean that the coldest days didn’t hit as hard as they might have without these mitigations in place, Glickman says. And warmer homes might be a good thing now, but as summers in the UK get hotter and air-conditioning remains rare, it may start to become a problem.
The ONS will now release this data on a yearly basis, but Glickman’s next project is to look more closely at how temperature changes affected different areas. “We’re going to drill down to a local level temperature,” he says. “That’s going to give us a lot more resolution on what’s happening and who it’s happening to.” The impact of climate change might depend on how wealthy an area is, for example, or whether its residents have easy access to health care or community support.
Glickman also wants to explore indirect impacts of climate on health. “What will be a big interest in the coming years is the lower-level health impacts of things like flooding,” he says. If someone’s home is flooded, it might increase their vulnerability to respiratory disease or worsen their mental health. Researchers from the UK have already found that people with mental illnesses are more at risk of death during hot weather. We don’t know why that is exactly, but researchers think it might be because people with mental illnesses are more likely to be socially isolated or already have poorer health, which makes them more vulnerable when temperatures rise.
The team behind the ONS report are also part of a wider effort to create a global system to count climate-related health impacts. “What we don’t have is a robust set of statistics to categorize the impact of climate on health,” says Bilal Mateen, a senior manager of digital technology at Wellcome Trust, the health charity funding the new climate change health impact initiative.
The first year of the project will be spent identifying countries to partner with before developing and testing different ways of measuring climate change deaths that work for specific countries, says Mateen. The idea is to use this data to help countries devise policies that lessen the health impact of climate change. “We can begin to tease out what works, what doesn’t, and what adaptation and mitigation interventions we should be supporting,” Mateen says.
If it’s true that warmer homes and flu vaccines helped reduce climate change deaths in England and Wales, it’s a sign that populations that are healthier on the whole might be better at surviving the ravages of a heating world. Other countries may want to take note. “All policies are health policies,” says Mateen. “There is a clear need to support job stability, to address fuel poverty and every other policy that’s outside of the mandate of the health minister, because we know that those social determinants of health have downstream impact.”
Researchers are exploring whether building massive berms or unfurling underwater curtains could hold back the warm waters degrading ice sheets.
January 14, 2022
James Temple
In December, researchers reported that huge and growing cracks have formed in the eastern ice shelf of the Thwaites Glacier, a Florida-size mass of ice that stretches 75 miles across western Antarctica.
They warned that the floating tongue of the glacier—which acts as a brace to prop up the Thwaites—could snap off into the ocean in as little as five years. That could trigger a chain reaction as more and more towering cliffs of ice are exposed and then fracture and collapse.
A complete loss of the so-called doomsday glacier could raise ocean levels by two feet—or as much as 10 feet if the collapse drags down surrounding glaciers with it, according to scientists with the International Thwaites Glacier Collaboration. Either way, it would flood coastal cities around the world, threatening tens of millions of people.
All of which raises an urgent question: Is there anything we could do to stop it?
Even if the world immediately halted the greenhouse-gas emissions driving climate change and warming the waters beneath the ice shelf, that wouldn’t do anything to thicken and restabilize the Thwaites’s critical buttress, says John Moore, a glaciologist and professor at the Arctic Centre at the University of Lapland in Finland.
“So the only way of preventing the collapse … is to physically stabilize the ice sheets,” he says.
That will require what is variously described as active conservation, radical adaptation, or glacier geoengineering.
Moore and others have laid out several ways that people could intervene to preserve key glaciers. Some of the schemes involve building artificial braces through polar megaprojects, or installing other structures that would nudge nature to restore existing ones. The basic idea is that a handful of engineering efforts at the source of the problem could significantly reduce the property damage and flooding dangers that basically every coastal city and low-lying island nation will face, as well as the costs of the adaptation projects required to minimize them.
If it works, it could potentially preserve crucial ice sheets for a few more centuries, buying time to cut emissions and stabilize the climate, the researchers say.
But there would be massive logistical, engineering, legal, and financial challenges. And it’s not yet clear how effective the interventions would be, or whether they could be done before some of the largest glaciers are lost.
Redirecting warming waters
In articles and papers published in 2018, Moore, Michael Wolovick of Princeton, and others laid out the possibility of preserving critical glaciers, including the Thwaites, through massive earth-moving projects. These would involve shipping in or dredging up large amounts of material to build up berms or artificial islands around or beneath key glaciers. The structures would support glaciers and ice shelves, block the warm, dense water layers at the bottom of the ocean that are melting them from below, or both.
More recently, they and researchers affiliated with the University of British Columbia have explored a more technical concept: constructing what they’ve dubbed “seabed anchored curtains.” These would be buoyant flexible sheets, made from geotextile material, that could hold back and redirect warm water.
The hope is that this proposal would be cheaper than the earlier ones, and that these curtains would stand up to iceberg collisions and could be removed if there were negative side effects. The researchers have modeled the use of these structures around three glaciers in Greenland, as well as the Thwaites and nearby Pine Island glaciers.
If the curtains redirected enough warm water, the eastern ice shelf of the Thwaites could begin to thicken again and firmly reattach itself to the underwater formations that have supported it for millennia, Moore says.
“The idea is to return the system to its state around the early 20th century, when we know that warm water could not access the ice shelf as much as today,” he wrote in an email.
They’ve explored the costs and effects of strategically placing these structures in key channels where most of the warm water flows in, and of establishing a wider curtain farther out in the bay. The latter approach would cost on the order of $50 billion. That’s a big number, but it’s not even half what one proposed seawall around New York City would cost.
Researchers have floated other potential approaches as well, including placing reflective or insulating material over portions of glaciers; building fencing to retain snow that would otherwise blow into the ocean; and applying various techniques to dry up the bed beneath glaciers, eliminating water that acts as lubricant and thus slowing the glaciers’ movement.
Will it work?
Some scientists have criticized these ideas. Seven researchers submitted a response in Nature to Moore’s 2018 proposals, arguing that the concepts would be partial solutions at best, could in some cases inadvertently accelerate ice loss, and could pull attention and resources from efforts to eliminate the root of the problem: greenhouse-gas emissions.
The lead author, Twila Moon, a scientist at the National Snow and Ice Data Center at the University of Colorado, Boulder, says the efforts would be akin to plugging a couple of holes in a garden hose riddled with them.
And that’s if they worked at all. She argues that the field doesn’t understand ice dynamics and other relevant factors well enough to be confident that these things will work, and the logistical challenges strike her as extreme given the difficulty of getting a single research vessel to Antarctica.
“Addressing the source of the problem means turning off that hose, and that is something that we understand,” she says. “We understand climate change; we understand the sources, and we understand how to reduce emissions.”
There would also be significant governance and legal obstacles, as Charles Corbett and Edward Parson, legal scholars at University of California, Los Angeles, School of Law, noted in a forthcoming essay in Ecology Law Quarterly.
Notably, Antarctica is governed by a consortium of nations under the Antarctic Treaty System, and any one of the 29 voting members could veto such proposals. In addition, the Madrid Protocol strictly limits certain activities on and around Antarctica, including projects that would have major physical or environmental impacts.
Corbett and Parson stress that the obstacles aren’t insurmountable and that the issue could inspire needed updates to how these regions are governed amid the rising threat of climate change. But they also note: “It all raises the question of whether a country or coalition could drive the project forward with sufficient determination.”
Getting started
Moore and others have noted in earlier work that a “handful of ice streams and large glaciers” are expected to produce nearly all the sea-level rise over the next few centuries, so a few successful interventions could have a significant impact.
But Moore readily acknowledges that such efforts will face vast challenges. Much more work needs to be done to closely evaluate how the flow of warm water will be affected, how well the curtains will hold up over time, what sorts of environmental side effects could occur, and how the public will respond. And installing the curtains under the frigid, turbulent conditions near Antarctica would likely require high-powered icebreakers and the sorts of submersible equipment used for deep-sea oil and gas platforms.
As a next step, Moore hopes to begin conversations with communities in Greenland to seek their input on such ideas well ahead of any field research proposals. But the basic idea would be to start with small-scale tests in regions where it will be relatively easy to work, like Greenland or Alaska. The hope is the lessons and experience gained there would make it possible to move on to harder projects in harsher areas.
The Thwaites would be at the top rung of this “ladder of difficulty.” And the researchers have been operating on the assumption that it could take three decades to build the public support, raise the needed financing, sort out the governance challenges, and build up the skills necessary to undertake such a project there.
There’s a clear problem with that timeline, however: the latest research suggests that the critical eastern buttress may not even be there by the end of this decade.
Source: Potsdam Institute for Climate Impact Research (PIK)
Summary: Economic growth goes down when the number of wet days and days with extreme rainfall go up, a team of scientists finds. The data analysis of more than 1,500 regions over the past 40 years shows a clear connection and suggests that intensified daily rainfall driven by climate-change from burning oil and coal will harm the global economy.
Economic growth goes down when the number of wet days and days with extreme rainfall go up, a team of Potsdam scientists finds. Rich countries are most severely affected and herein the manufacturing and service sectors, according to their study now published as cover story in the journal Nature. The data analysis of more than 1,500 regions over the past 40 years shows a clear connection and suggests that intensified daily rainfall driven by climate-change from burning oil and coal will harm the global economy.
“This is about prosperity, and ultimately about people’s jobs. Economies across the world are slowed down by more wet days and extreme daily rainfall — an important insight that adds to our growing understanding of the true costs of climate change,” says Leonie Wenz from the Potsdam Institute for Climate Impact Research (PIK) and the Mercator Research Institute on Global Commons and Climate Change (MCC) who led the study.
“Macro-economic assessments of climate impacts have so far focused mostly on temperature and considered — if at all — changes in rainfall only across longer time scales such as years or months, thus missing the complete picture,” explains Wenz. “While more annual rainfall is generally good for economies, especially agriculturally dependent ones, the question is also how the rain is distributed across the days of the year. Intensified daily rainfall turns out to be bad, especially for wealthy, industrialized countries like the US, Japan, or Germany.”
A first-of-its-kind global analysis of subnational rainfall effects
“We identify a number of distinct effects on economic production, yet the most important one really is from extreme daily rainfall,” says Maximilian Kotz, first author of the study and also at the Potsdam Institute. “This is because rainfall extremes are where we can already see the influence of climate change most clearly, and because they are intensifying almost everywhere across the world.”
The analysis statistically evaluates data of sub-national economic output for 1554 regions worldwide in the period 1979-2019, collected and made publicly available by MCC and PIK. The scientists combine these with high resolution rainfall data. The combination of ever increasing detail in climatic and economic data is of particular importance in the context of rain, a highly local phenomenon, and revealed the new insights.
“It’s the daily rainfall that poses the threat“
By loading the Earth’s atmosphere with greenhouse gases from fossil power plants and cars, humanity is heating the planet. Warming air can hold more water vapour that eventually becomes rain. Although atmospheric dynamics make regional changes in annual averages more complicated, daily rainfall extremes are increasing globally due to this water vapour effect.
“Our study reveals that it’s precisely the fingerprint of global warming in daily rainfall which have hefty economic effects that have not yet been accounted for but are highly relevant,” says co-author Anders Levermann, Head of the Potsdam Institute’s Complexity Science domain, professor at Potsdam University and researcher at Columbia University’s Lamont Doherty Earth Observatory, New York. “Taking a closer look at short time scales instead of annual averages helps to understand what is going on: it’s the daily rainfall which poses the threat. It’s rather the climate shocks from weather extremes that threaten our way of life than the gradual changes. By destabilizing our climate we harm our economies. We have to make sure that our burning of fossil fuels does not destabilize our societies, too.”
Journal Reference:
Maximilian Kotz, Anders Levermann, Leonie Wenz. The effect of rainfall changes on economic production. Nature, 2022; 601 (7892): 223 DOI: 10.1038/s41586-021-04283-8
IS IT NEARLY over? In 2021 people have been yearning for something like stability. Even those who accepted that they would never get their old lives back hoped for a new normal. Yet as 2022 draws near, it is time to face the world’s predictable unpredictability. The pattern for the rest of the 2020s is not the familiar routine of the pre-covid years, but the turmoil and bewilderment of the pandemic era. The new normal is already here.
Remember how the terrorist attacks of September 11th 2001 began to transform air travel in waves. In the years that followed each fresh plot exposed an unforeseen weakness that required a new rule. First came locked cockpit doors, more armed air marshals and bans on sharp objects. Later, suspicion fell on bottles of liquid, shoes and laptops. Flying did not return to normal, nor did it establish a new routine. Instead, everything was permanently up for revision.
The world is similarly unpredictable today and the pandemic is part of the reason. For almost two years people have lived with shifting regimes of mask-wearing, tests, lockdowns, travel bans, vaccination certificates and other paperwork. As outbreaks of new cases and variants ebb and flow, so these regimes can also be expected to come and go. That is the price of living with a disease that has not yet settled into its endemic state.
And covid-19 may not be the only such infection. Although a century elapsed between the ravages of Spanish flu and the coronavirus, the next planet-conquering pathogen could strike much sooner. Germs thrive in an age of global travel and crowded cities. The proximity of people and animals will lead to the incubation of new human diseases. Such zoonoses, which tend to emerge every few years, used to be a minority interest. For the next decade, at least, you can expect each new outbreak to trigger paroxysms of precaution.
Covid has also helped bring about today’s unpredictable world indirectly, by accelerating change that was incipient. The pandemic has shown how industries can be suddenly upended by technological shifts. Remote shopping, working from home and the Zoom boom were once the future. In the time of covid they rapidly became as much of a chore as picking up the groceries or the daily commute.
Big technological shifts are nothing new. But instead of taking centuries or decades to spread around the world, as did the printing press and telegraph, new technologies become routine in a matter of years. Just 15 years ago, modern smartphones did not exist. Today more than half of the people on the planet carry one. Any boss who thinks their industry is immune to such wild dynamism is unlikely to last long.
The pandemic may also have ended the era of low global inflation that began in the 1990s and was ingrained by economic weakness after the financial crisis of 2007-09. Having failed to achieve a quick recovery then, governments spent nearly $11trn trying to ensure that the harm caused by the virus was transient.
They broadly succeeded, but fiscal stimulus and bunged-up supply chains have raised global inflation above 5%. The apparent potency of deficit spending will change how recessions are fought. As they raise interest rates to deal with inflation, central banks may find themselves in conflict with indebted governments. Amid a burst of innovation around cryptocoins, central-bank digital currencies and fintech, many outcomes are possible. A return to the comfortable macroeconomic orthodoxies of the 1990s is one of the least likely.
The pandemic has also soured relations between the world’s two great powers. America blames China’s secretive Communist Party for failing to contain the virus that emerged from Wuhan at the end of 2019. Some claim that it came from a Chinese laboratory there—an idea China has allowed to fester through its self-defeating resistance to open investigations. For its part, China, which has recorded fewer than 6,000 deaths, no longer bothers to hide its disdain for America, with its huge death toll. In mid-December this officially passed 800,000 (The Economist estimates the full total to be almost 1m). The contempt China and America feel for each other will heighten tensions over Taiwan, the South China Sea, human rights in Xinjiang and the control of strategic technologies.
In the case of climate change, the pandemic has served as an emblem of interdependence. Despite the best efforts to contain them, virus particles cross frontiers almost as easily as molecules of methane and carbon dioxide. Scientists from around the world showed how vaccines and medicines can save hundreds of millions of lives. However, hesitancy and the failure to share doses frustrated their plans. Likewise, in a world that is grappling with global warming, countries that have everything to gain from working together continually fall short. Even under the most optimistic scenarios, the accumulation of long-lasting greenhouse gases in the atmosphere means that extreme and unprecedented weather of the kind seen during 2021 is here to stay.
The desire to return to a more stable, predictable world may help explain a 1990s revival. You can understand the appeal of going back to a decade in which superpower competition had abruptly ended, liberal democracy was triumphant, suits were oversized, work ended when people left the office, and the internet was not yet disrupting cosy, established industries or stoking the outrage machine that has supplanted public discourse.
Events, dear boy, events
That desire is too nostalgic. It is worth notching up some of the benefits that come with today’s predictable unpredictability. Many people like to work from home. Remote services can be cheaper and more accessible. The rapid dissemination of technology could bring unimagined advances in medicine and the mitigation of global warming.
Even so, beneath it lies the unsettling idea that once a system has crossed some threshold, every nudge tends to shift it further from the old equilibrium. Many of the institutions and attitudes that brought stability in the old world look ill-suited to the new. The pandemic is like a doorway. Once you pass through, there is no going back. ■
This article appeared in the Leaders section of the print edition under the headline “The new normal”
In Discriminating Data: Correlation, Neighborhoods, and the New Politics of Recognition, Wendy Hui Kyong Chun explores how technological developments around data are amplifying and automating discrimination and prejudice. Through conceptual innovation and historical details, this book offers engaging and revealing insights into how data exacerbates discrimination in powerful ways, writes David Beer.
Discriminating Data: Correlation, Neighborhoods, and the New Politics of Recognition. Wendy Hui Kyong Chun (mathematical illustrations by Alex Barnett). MIT Press. 2021.
Going back a couple of decades, there was a fair amount of discussion of ‘the digital divide’. Uneven access to networked computers meant that a line was drawn between those who were able to switch-on and those who were not. At the time there was a pressing concern about the disadvantages of a lack of access. With the massive escalation of connectivity since, the notion of a digital divide still has some relevance, but it has become a fairly blunt tool for understanding today’s extensively mediated social constellations. The divides now are not so much a product of access; they are instead a consequence of what happens to the data produced through that access.
With the escalation of data and the establishment of all sorts of analytic and algorithmic processes, the problem of uneven, unjust and harmful treatment is now the focal point for an animated and urgent debate. Wendy Hui Kyong Chun’s vibrant new book Discriminating Data: Correlation, Neighborhoods, and the New Politics of Recognitionmakes a telling intervention. At its centre is the idea that these technological developments around data ‘are amplifying and automating – rather than acknowledging and repairing – the mistakes of a discriminatory past’ (2). Essentially this is the codification and automation of prejudice. Any ideas about the liberating aspects of technology are deflated. Rooted in a longer history of statistics and biometrics, existing ruptures are being torn open by the differential targeting that big data brings.
This is not just about bits of data. Chun suggests that ‘we need […] to understand how machine learning and other algorithms have been embedded with human prejudice and discrimination, not simply at the level of data, but also at the levels of procedure, prediction, and logic’ (16). It is not, then, just about prejudice being in the data itself; it is also how segregation and discrimination are embedded in the way this data is used. Given the scale of these issues, Chun narrows things down further by focusing on four ‘foundational concepts’, with correlation, homophily, authenticity and recognition providing the focal points for interrogating the discriminations of data.
It is the concept of correlation that does much of the gluing work within the study. The centrality of correlation is a subtext in Chun’s own overview of the book, which suggests that ‘Discriminating Data reveals how correlation and eugenic understandings of nature seek to close off the future by operationalizing probabilities; how homophily naturalizes segregation; and how authenticity and recognition foster deviation in order to create agitated clusters of comforting rage’ (27). As well as developing these lines of argument, the use of the concept of correlation also allows Chun to think in deeply historical terms about the trajectory and politics of association and patterning.
For Chun the role of correlation is both complex and performative. It is argued, for instance, that correlations ‘do not simply predict certain actions; they also form them’. This is an established position in the field of critical data studies, with data prescribing and producing the outcomes they are used to anticipate. However, Chun manages to reanimate this position through an exploration of how correlation fits into a wider set of discriminatory data practices. The other performative issue here is the way that people are made-up and grouped through the use of data. Correlations, Chun writes, ‘that lump people into categories based on their being “like” one another amplify the effects of historical inequalities’ (58). Inequalities are reinforced as categories become more obdurate, with data lending them a sense of apparent stability and a veneer of objectivity. Hence the pointed claim that ‘correlation contains within it the seeds of manipulation, segregation and misrepresentation’ (59).
Given this use of data to categorise, it is easy to see why Discriminating Data makes a conceptual link between correlation and homophily – with homophily, as Chun puts it, being the ‘principle that similarity breeds connection’ and can therefore lead to swarming and clustering. The acts of grouping within these data structures mean, for Chun, that ‘homophily not only eases conflict; it also naturalizes discrimination’ (103). Using data correlations to group informs a type of homophily that not only misrepresents and segregates; it also makes these divides seem natural and therefore fixed.
Chun anticipates that there may be some remaining remnants of faith in the seeming democratic properties of these platforms, arguing that ‘homophily reveals and creates boundaries within theoretically flat and diffuse social networks; it distinguishes and discriminates between supposedly equal nodes; it is a tool for discovering bias and inequality and for perpetuating them in the name of “comfort,” predictability, and common sense’ (85). As individuals are moved into categories or groups assumed to be like them, based upon the correlations within their data, so discrimination can readily occur. One of the key observations made by Chun is that data homophily can feel comfortable, especially when encased in predictions, yet this can distract from the actual damages of the underpinning discriminations they contain. Instead, these data ‘proxies can serve to buttress – and justify – discrimination’ (121). For Chun there is a ‘proxy politics’ unfolding in which data not only exacerbates but can also be used to lend legitimacy to discriminatory acts.
As with correlation and homophily, Chun, in a particularly novel twist, also explores how authenticity is itself becoming automated within these data structures. In stark terms, it is argued that ‘authenticity has become so central to our times because it has become algorithmic’ (144). Chun is able to show how a wider cultural push towards notions of the authentic, embodied in things like reality TV, becomes a part of data systems. A broader cultural trend is translated into something renderable in data. Chun explains that the ‘term “algorithmic authenticity” reveals the ways in which users are validated and authenticated by network algorithms’ (144). A system of validation occurs in these spaces, where actions and practices are algorithmically judged and authenticated. Algorithmic authenticity ‘trains them to be transparent’ (241). It pushes a form of openness upon us in which an ‘operationalized authenticity’ develops, especially within social media.
This emphasis upon the authentic draws people into certain types of interaction with these systems. It shows, Chun compellingly puts it, ‘how users have become characters in a drama called “big data”’ (145). The notion of a drama is, of course, not to diminish what is happening but to try to get at its vibrant and role-based nature. It also adds a strong sense of how performance plays out in relation to the broader ideas of data judgment that the book is exploring.
These roles are not something that Chun wants us to accept, arguing instead that ‘if we think through our roles as performers and characters in the drama called “big data,” we do not have to accept the current terms of our deployment’ (170). Examining the artifice of the drama is a means of transformation and challenge. Exposing the drama is to expose the roles and scripts that are in place, enabling them to be questioned and possibly undone. This is not fatalistic or absent of agency; rather, Chun’s point is that ‘we are characters, rather than marionettes’ (248).
There are some powerful cross-currents working through the discussions of the book’s four foundational concepts. The suggestion that big data brings a reversal of hegemony is a particularly telling argument. Chun explains that: ‘Power can now operate through reverse hegemony: if hegemony once meant the creation of a majority by various minorities accepting a dominant worldview […], now hegemonic majorities can emerge when angry minorities, clustered around a shared stigma, are strung together through their mutual opposition to so-called mainstream culture’ (34). This line of argument is echoed in similar terms in the book’s conclusion, clarifying further that ‘this is hegemony in reverse: if hegemony once entailed creating a majority by various minorities accepting – and identifying with – a dominant worldview, majorities now emerge by consolidating angry minorities – each attached to a particular stigma – through their opposition to “mainstream” culture’ (243). In this formulation it would seem that big data may not only be disciplinary but may also somehow gain power by upending any semblance of a dominant ideology. Data doesn’t lead to shared ideas but to the splitting of the sharing of ideas into group-based networks. It does seem plausible that the practices of targeting and patterning through data are unlikely to facilitate hegemony. Yet, it is not just that data affords power beyond hegemony but that it actually seeks to reverse it.
The reader may be caught slightly off-guard by this position. Chun generally seems to picture power as emerging and solidifying through a genealogy of the technologies that have formed into contemporary data infrastructures. In this account power seems to be associated with established structures and operates through correlations, calls for authenticity and the means of recognition. These positions on power – with infrastructures on one side and reverse hegemony on the other – are not necessarily incompatible, yet the discussion of reverse hegemony perhaps stands a little outside of that other vision of power. I was left wondering if this reverse hegemony is a consequence of these more processional operations of power or, maybe, it is a kind of facilitator of them.
Chun’s book looks to bring out the deep divisions that data-informed discrimination has already created and will continue to create. The conceptual innovation and the historical details, particularly on statistics and eugenics, lend the book a deep sense of context that feeds into a range of genuinely engaging and revealing insights and ideas. Through its careful examination of the way that data exacerbates discrimination in very powerful ways, this is perhaps the most telling book yet on the topic. The digital divide may no longer be a particularly useful term but, as Chun’s book makes clear, the role data performs in animating discrimination means that the technological facilitation of divisions has never been more pertinent.
O que o surgimento da internet, os ataques de 11 de setembro de 2001 e a crise econômica de 2008 têm em comum?
Foram eventos extremamente raros e surpreendentes que tiveram um forte impacto na história.
Acontecimentos deste tipo costumam ser chamados de “cisnes negros”.
Alguns argumentam que a recente pandemia de covid-19 também pode ser considerada um deles, mas nem todo mundo concorda.
A “teoria do cisne negro” foi desenvolvida pelo professor, escritor e ex-operador da bolsa libanês-americano Nassim Taleb em 2007.
E possui três componentes, como o próprio Taleb explicou em um artigo no jornal americano The New York Times no mesmo ano:
– Em primeiro lugar, é algo atípico, já que está fora do âmbito das expectativas habituais, porque nada no passado pode apontar de forma convincente para sua possibilidade.
– Em segundo lugar, tem um impacto extremo.
– Em terceiro lugar, apesar de seu status atípico, a natureza humana nos faz inventar explicações para sua ocorrência após o fato em si, tornando-o explicável e previsível.
A tese de Taleb está geralmente associada à economia, mas se aplica a qualquer área.
E uma vez que as consequências costumam ser catastróficas, é importante aceitar que a ocorrência de um evento”cisne negro” é possível — e por isso é necessário ter um plano para lidar com o mesmo.
Em suma, o “cisne negro” representa uma metáfora para algo imprevisível e muito estranho, mas não impossível.
Por que são chamados assim?
No fim do século 17, navios europeus embarcaram na aventura de explorar a Austrália.
Em 1697, enquanto navegava nas águas de um rio desconhecido no sudoeste da Austrália Ocidental, o capitão holandês Willem de Vlamingh avistou vários cisnes negros, sendo possivelmente o primeiro europeu a observá-los.
Como consequência, Vlamingh deu ao rio o nome de Zwaanenrivier (Rio dos Cisnes, em holandês) por causa do grande número de cisnes negros que havia ali.
Tratava-se de um acontecimento inesperado e novo. Até aquele momento, a ciência só havia registrado cisnes brancos.
A primeira referência conhecida ao termo “cisne negro” associado ao significado de raridade vem de uma frase do poeta romano Décimo Júnio Juvenal (60-128).
Desesperado para encontrar uma esposa com todas as “qualidades certas” da época, ele escreveu em latim que esta mulher era rara avis in terris, nigroque simillima cygno (“uma ave rara nestas terras, como um cisne negro”), detalha o dicionário de Oxford.
Porque naquela época e até cerca de 1,6 mil anos depois, para os europeus, não existiam cisnes negros.
Prevendo os ‘cisnes negros’
Um grupo de cientistas da Universidade de Stanford, nos Estados Unidos, está trabalhando para prever o imprevisível.
Ou seja, para se antecipar aos “cisnes negros” — não às aves, mas aos estranhos eventos que acontecem na história.
Embora sua análise primária tenha sido baseada em três ambientes diferentes na natureza, o método computacional que eles criaram pode ser aplicado a qualquer área, incluindo economia e política.
“Ao analisar dados de longo prazo de três ecossistemas, pudemos demonstrar que as flutuações que ocorrem em diferentes espécies biológicas são estatisticamente iguais em diferentes ecossistemas”, afirmou Samuel Bray, assistente de pesquisa no laboratório de Bo Wang, professor de bioengenharia na Universidade de Stanford.
“Isso sugere que existem certos processos universais que podemos utilizar para prever esse tipo de comportamento extremo”, acrescentou Bray, conforme publicado no site da universidade.
Para desenvolver o método de previsão, os pesquisadores procuraram sistemas biológicos que vivenciaram eventos “cisne negro” e como foram os contextos em que ocorreram.
Eles se basearam então em ecossistemas monitorados de perto por muitos anos.
Os exemplos incluíram: um estudo de oito anos do plâncton do Mar Báltico com níveis de espécies medidos duas vezes por semana; medições de carbono de um bosque da Universidade de Harvard, nos EUA, que foram coletadas a cada 30 minutos desde 1991; e medições de cracas (mariscos), algas e mexilhões na costa da Nova Zelândia, feitas mensalmente por mais de 20 anos, detalha o estudo publicado na revista científica Plos Computational Biology.
Os pesquisadores aplicaram a estas bases de dados a teoria física por trás de avalanches e terremotos que, assim como os “cisnes negros”, mostram um comportamento extremo, repentino e de curto prazo.
A partir desta análise, os especialistas desenvolveram um método para prever eventos “cisne negro” que fosse flexível entre espécies e períodos de tempo e também capaz de trabalhar com dados muito menos detalhados e mais complexos.
Posteriormente, conseguiram prever com precisão eventos extremos que ocorreram nesses sistemas.
Até agora, “os métodos se baseavam no que vimos para prever o que pode acontecer no futuro, e é por isso que não costumam identificar os eventos ‘cisne negro'”, diz Wang.
Mas este novo mecanismo é diferente, segundo o professor de Stanford, “porque parte do pressuposto de que estamos vendo apenas parte do mundo”.
“Extrapola um pouco do que falta e ajuda enormemente em termos de previsão”, acrescenta.
Então, os “cisnes negros” poderiam ser detectados em outras áreas, como finanças ou economia?
“Aplicamos nosso método às flutuações do mercado de ações e funcionou muito bem”, disse Wang à BBC News Mundo, serviço de notícias em espanhol da BBC, por e-mail.
Os pesquisadores analisaram os índices Nasdaq, Dow Jones Industrial Average e S&P 500.
“Embora a principal tendência do mercado seja o crescimento exponencial de longo prazo, as flutuações em torno dessa tendência seguem as mesmas trajetórias e escalas médias que vimos nos sistemas ecológicos”, explica.
Mas “embora as semelhanças entre as variações na bolsa e ecológicas sejam interessantes, nosso método de previsão é mais útil nos casos em que os dados são escassos e as flutuações geralmente vão além dos registros históricos (o que não é o caso do mercado de ações)”, adverte Wang.
Por isso, temos que continuar atentos para saber se o próximo “cisne negro” vai nos pegar de surpresa… ou talvez não.
“Humans have impacted the ocean in a more dramatic fashion than merely capturing fish,” explained marine ecologist Ryan Heneghan from the Queensland University of Technology.
“It seems that we have broken the size spectrum – one of the largest power law distributions known in nature.”
The power law can be used to describe many things in biology, from patterns of cascading neural activity to the foraging journeys of various species. It’s when two quantities, whatever their initial starting point be, change in proportion relative to each other.
In the case of a particular type of power law, first described in a paper led by Raymond W. Sheldon in 1972 and now known as the ‘Sheldon spectrum’, the two quantities are the body size of an organism, scaled in proportion to its abundance. So, the larger they get, there tend to be consistently fewer individuals within a set species size group.
For example, while krill are 12 orders of magnitudes (about a billion) times smaller than tuna, they’re also 12 orders of magnitudes more abundant than tuna. So hypothetically, all the tuna flesh in the world combined (tuna biomass) is roughly the same amount (to within the same order of magnitude at least) as all the krill biomass in the world.
Since it was first proposed in 1972, scientists had only tested for this natural scaling pattern within limited groups of species in aquatic environments, at relatively small scales. From marine plankton, to fish in freshwater this pattern held true – the biomass of larger less abundant species was roughly equivalent to the biomass of the smaller yet more abundant species.
Now, Max Planck Institute ecologist Ian Hatton and colleagues have looked to see if this law also reflects what’s happening on a global scale.
“One of the biggest challenges to comparing organisms spanning bacteria to whales is the enormous differences in scale,” says Hatton.
“The ratio of their masses is equivalent to that between a human being and the entire Earth. We estimated organisms at the small end of the scale from more than 200,000 water samples collected globally, but larger marine life required completely different methods.”
Using historical data, the team confirmed the Sheldon spectrum fit this relationship globally for pre-industrial oceanic conditions (before 1850). Across 12 groups of sea life, including bacteria, algae, zooplankton, fish and mammals, over 33,000 grid points of the global ocean, roughly equal amounts of biomass occurred in each size category of organism.
“We were amazed to see that each order of magnitude size class contains approximately 1 gigaton of biomass globally,” says McGill University geoscientist Eric Galbraith.
(Ian Hatton et al, Science Advances, 2021)
Hatton and team discussed possible explanations for this, including limitations set by factors such as predator-prey interactions, metabolism, growth rates, reproduction and mortality. Many of these factors also scale with an organism’s size. But they’re all speculation at this point.
“The fact that marine life is evenly distributed across sizes is remarkable,” said Galbraith. “We don’t understand why it would need to be this way – why couldn’t there be much more small things than large things? Or an ideal size that lies in the middle? In that sense, the results highlight how much we don’t understand about the ecosystem.”
There were two exceptions to the rule however, at both extremes of the size scale examined. Bacteria were more abundant than the law predicted, and whales far less. Again, why is a complete mystery.
The researchers then compared these findings to the same analysis applied to present day samples and data. While the power law still mostly applied, there was a stark disruption to its pattern evident with larger organisms.
“Human impacts appear to have significantly truncated the upper one-third of the spectrum,” the team wrote in their paper. “Humans have not merely replaced the ocean’s top predators but have instead, through the cumulative impact of the past two centuries, fundamentally altered the flow of energy through the ecosystem.”
(Ian Hatton et al, Science Advances, 2021)
While fishes compose less than 3 percent of annual human food consumption, the team found we’ve reduced fish and marine mammal biomass by 60 percent since the 1800s. It’s even worse for Earth’s most giant living animals – historical hunting has left us with a 90 percent reduction of whales.
This really highlights the inefficiency of industrial fishing, Galbraith notes. Our current strategies are wasting magnitudes more biomass and the energy it holds, than we actually consume. Nor have we replaced the role that biomass once played, despite now being one of the largest vertebrate species by biomass.
Around 2.7 gigatonnes have been lost from the largest species groups in the oceans, whereas humans make up around 0.4 gigatonnes. Further work is needed to understand how this massive loss in biomass affects the oceans, the team wrote.
“The good news is that we can reverse the imbalance we’ve created, by reducing the number of active fishing vessels around the world,” Galbraith says. “Reducing overfishing will also help make fisheries more profitable and sustainable – it’s a potential win-win, if we can get our act together.”
DOES ANYONE really understand what is going on in the world economy? The pandemic has made plenty of observers look clueless. Few predicted $80 oil, let alone fleets of container ships waiting outside Californian and Chinese ports. As covid-19 let rip in 2020, forecasters overestimated how high unemployment would be by the end of the year. Today prices are rising faster than expected and nobody is sure if inflation and wages will spiral upward. For all their equations and theories, economists are often fumbling in the dark, with too little information to pick the policies that would maximise jobs and growth.
Yet, as we report this week, the age of bewilderment is starting to give way to greater enlightenment. The world is on the brink of a real-time revolution in economics, as the quality and timeliness of information are transformed. Big firms from Amazon to Netflix already use instant data to monitor grocery deliveries and how many people are glued to “Squid Game”. The pandemic has led governments and central banks to experiment, from monitoring restaurant bookings to tracking card payments. The results are still rudimentary, but as digital devices, sensors and fast payments become ubiquitous, the ability to observe the economy accurately and speedily will improve. That holds open the promise of better public-sector decision-making—as well as the temptation for governments to meddle.
The desire for better economic data is hardly new. America’s GNP estimates date to 1934 and initially came with a 13-month time lag. In the 1950s a young Alan Greenspan monitored freight-car traffic to arrive at early estimates of steel production. Ever since Walmart pioneered supply-chain management in the 1980s private-sector bosses have seen timely data as a source of competitive advantage. But the public sector has been slow to reform how it works. The official figures that economists track—think of GDP or employment—come with lags of weeks or months and are often revised dramatically. Productivity takes years to calculate accurately. It is only a slight exaggeration to say that central banks are flying blind.
Bad and late data can lead to policy errors that cost millions of jobs and trillions of dollars in lost output. The financial crisis would have been a lot less harmful had the Federal Reserve cut interest rates to near zero in December 2007, when America entered recession, rather than in December 2008, when economists at last saw it in the numbers. Patchy data about a vast informal economy and rotten banks have made it harder for India’s policymakers to end their country’s lost decade of low growth. The European Central Bank wrongly raised interest rates in 2011 amid a temporary burst of inflation, sending the euro area back into recession. The Bank of England may be about to make a similar mistake today.
The pandemic has, however, become a catalyst for change. Without the time to wait for official surveys to reveal the effects of the virus or lockdowns, governments and central banks have experimented, tracking mobile phones, contactless payments and the real-time use of aircraft engines. Instead of locking themselves in their studies for years writing the next “General Theory”, today’s star economists, such as Raj Chetty at Harvard University, run well-staffed labs that crunch numbers. Firms such as JPMorgan Chase have opened up treasure chests of data on bank balances and credit-card bills, helping reveal whether people are spending cash or hoarding it.
These trends will intensify as technology permeates the economy. A larger share of spending is shifting online and transactions are being processed faster. Real-time payments grew by 41% in 2020, according to McKinsey, a consultancy (India registered 25.6bn such transactions). More machines and objects are being fitted with sensors, including individual shipping containers that could make sense of supply-chain blockages. Govcoins, or central-bank digital currencies (CBDCs), which China is already piloting and over 50 other countries are considering, might soon provide a goldmine of real-time detail about how the economy works.
Timely data would cut the risk of policy cock-ups—it would be easier to judge, say, if a dip in activity was becoming a slump. And the levers governments can pull will improve, too. Central bankers reckon it takes 18 months or more for a change in interest rates to take full effect. But Hong Kong is trying out cash handouts in digital wallets that expire if they are not spent quickly. CBDCs might allow interest rates to fall deeply negative. Good data during crises could let support be precisely targeted; imagine loans only for firms with robust balance-sheets but a temporary liquidity problem. Instead of wasteful universal welfare payments made through social-security bureaucracies, the poor could enjoy instant income top-ups if they lost their job, paid into digital wallets without any paperwork.
The real-time revolution promises to make economic decisions more accurate, transparent and rules-based. But it also brings dangers. New indicators may be misinterpreted: is a global recession starting or is Uber just losing market share? They are not as representative or free from bias as the painstaking surveys by statistical agencies. Big firms could hoard data, giving them an undue advantage. Private firms such as Facebook, which launched a digital wallet this week, may one day have more insight into consumer spending than the Fed does.
Know thyself
The biggest danger is hubris. With a panopticon of the economy, it will be tempting for politicians and officials to imagine they can see far into the future, or to mould society according to their preferences and favour particular groups. This is the dream of the Chinese Communist Party, which seeks to engage in a form of digital central planning.
In fact no amount of data can reliably predict the future. Unfathomably complex, dynamic economies rely not on Big Brother but on the spontaneous behaviour of millions of independent firms and consumers. Instant economics isn’t about clairvoyance or omniscience. Instead its promise is prosaic but transformative: better, timelier and more rational decision-making. ■
AS PART OF his plan for socialism in the early 1970s, Salvador Allende created Project Cybersyn. The Chilean president’s idea was to offer bureaucrats unprecedented insight into the country’s economy. Managers would feed information from factories and fields into a central database. In an operations room bureaucrats could see if production was rising in the metals sector but falling on farms, or what was happening to wages in mining. They would quickly be able to analyse the impact of a tweak to regulations or production quotas.
Cybersyn never got off the ground. But something curiously similar has emerged in Salina, a small city in Kansas. Salina311, a local paper, has started publishing a “community dashboard” for the area, with rapid-fire data on local retail prices, the number of job vacancies and more—in effect, an electrocardiogram of the economy.
What is true in Salina is true for a growing number of national governments. When the pandemic started last year bureaucrats began studying dashboards of “high-frequency” data, such as daily airport passengers and hour-by-hour credit-card-spending. In recent weeks they have turned to new high-frequency sources, to get a better sense of where labour shortages are worst or to estimate which commodity price is next in line to soar. Economists have seized on these new data sets, producing a research boom (see chart 1). In the process, they are influencing policy as never before.
This fast-paced economics involves three big changes. First, it draws on data that are not only abundant but also directly relevant to real-world problems. When policymakers are trying to understand what lockdowns do to leisure spending they look at live restaurant reservations; when they want to get a handle on supply-chain bottlenecks they look at day-by-day movements of ships. Troves of timely, granular data are to economics what the microscope was to biology, opening a new way of looking at the world.
Second, the economists using the data are keener on influencing public policy. More of them do quick-and-dirty research in response to new policies. Academics have flocked to Twitter to engage in debate.
And, third, this new type of economics involves little theory. Practitioners claim to let the information speak for itself. Raj Chetty, a Harvard professor and one of the pioneers, has suggested that controversies between economists should be little different from disagreements among doctors about whether coffee is bad for you: a matter purely of evidence. All this is causing controversy among dismal scientists, not least because some, such as Mr Chetty, have done better from the shift than others: a few superstars dominate the field.
Their emerging discipline might be called “third wave” economics. The first wave emerged with Adam Smith and the “Wealth of Nations”, published in 1776. Economics mainly involved books or papers written by one person, focusing on some big theoretical question. Smith sought to tear down the monopolistic habits of 18th-century Europe. In the 20th century John Maynard Keynes wanted people to think differently about the government’s role in managing the economic cycle. Milton Friedman aimed to eliminate many of the responsibilities that politicians, following Keynes’s ideas, had arrogated to themselves.
All three men had a big impact on policies—as late as 1850 Smith was quoted 30 times in Parliament—but in a diffuse way. Data were scarce. Even by the 1970s more than half of economics papers focused on theory alone, suggests a study published in 2012 by Daniel Hamermesh, an economist.
That changed with the second wave of economics. By 2011 purely theoretical papers accounted for only 19% of publications. The growth of official statistics gave wonks more data to work with. More powerful computers made it easier to spot patterns and ascribe causality (this year’s Nobel prize was awarded for the practice of identifying cause and effect). The average number of authors per paper rose, as the complexity of the analysis increased (see chart 2). Economists had greater involvement in policy: rich-world governments began using cost-benefit analysis for infrastructure decisions from the 1950s.
Second-wave economics nonetheless remained constrained by data. Most national statistics are published with lags of months or years. “The traditional government statistics weren’t really all that helpful—by the time they came out, the data were stale,” says Michael Faulkender, an assistant treasury secretary in Washington at the start of the pandemic. The quality of official local economic data is mixed, at best; they do a poor job of covering the housing market and consumer spending. National statistics came into being at a time when the average economy looked more industrial, and less service-based, than it does now. The Standard Industrial Classification, introduced in 1937-38 and still in use with updates, divides manufacturing into 24 subsections, but the entire financial industry into just three.
The mists of time
Especially in times of rapid change, policymakers have operated in a fog. “If you look at the data right now…we are not in what would normally be characterised as a recession,” argued Edward Lazear, then chairman of the White House Council of Economic Advisers, in May 2008. Five months later, after Lehman Brothers had collapsed, the IMF noted that America was “not necessarily” heading for a deep recession. In fact America had entered a recession in December 2007. In 2007-09 there was no surge in economics publications. Economists’ recommendations for policy were mostly based on judgment, theory and a cursory reading of national statistics.
The gap between official data and what is happening in the real economy can still be glaring. Walk around a Walmart in Kansas and many items, from pet food to bottled water, are in short supply. Yet some national statistics fail to show such problems. Dean Baker of the Centre for Economic and Policy Research, using official data, points out that American real inventories, excluding cars and farm products, are barely lower than before the pandemic.
There were hints of an economics third wave before the pandemic. Some economists were finding new, extremely detailed streams of data, such as anonymised tax records and location information from mobile phones. The analysis of these giant data sets requires the creation of what are in effect industrial labs, teams of economists who clean and probe the numbers. Susan Athey, a trailblazer in applying modern computational methods in economics, has 20 or so non-faculty researchers at her Stanford lab (Mr Chetty’s team boasts similar numbers). Of the 20 economists with the most cited new work during the pandemic, three run industrial labs.
More data sprouted from firms. Visa and Square record spending patterns, Apple and Google track movements, and security companies know when people go in and out of buildings. “Computers are in the middle of every economic arrangement, so naturally things are recorded,” says Jon Levin of Stanford’s Graduate School of Business. Jamie Dimon, the boss of JPMorgan Chase, a bank, is an unlikely hero of the emergence of third-wave economics. In 2015 he helped set up an institute at his bank which tapped into data from its network to analyse questions about consumer finances and small businesses.
The Brexit referendum of June 2016 was the first big event when real-time data were put to the test. The British government and investors needed to get a sense of this unusual shock long before Britain’s official GDP numbers came out. They scraped web pages for telltale signs such as restaurant reservations and the number of supermarkets offering discounts—and concluded, correctly, that though the economy was slowing, it was far from the catastrophe that many forecasters had predicted.
Real-time data might have remained a niche pursuit for longer were it not for the pandemic. Chinese firms have long produced granular high-frequency data on everything from cinema visits to the number of glasses of beer that people are drinking daily. Beer-and-movie statistics are a useful cross-check against sometimes dodgy official figures. China-watchers turned to them in January 2020, when lockdowns began in Hubei province. The numbers showed that the world’s second-largest economy was heading for a slump. And they made it clear to economists elsewhere how useful such data could be.
Vast and fast
In the early days of the pandemic Google started releasing anonymised data on people’s physical movements; this has helped researchers produce a day-by-day measure of the severity of lockdowns (see chart 3). OpenTable, a booking platform, started publishing daily information on restaurant reservations. America’s Census Bureau quickly introduced a weekly survey of households, asking them questions ranging from their employment status to whether they could afford to pay the rent.
In May 2020 Jose Maria Barrero, Nick Bloom and Steven Davis, three economists, began a monthly survey of American business practices and work habits. Working-age Americans are paid to answer questions on how often they plan to visit the office, say, or how they would prefer to greet a work colleague. “People often complete a survey during their lunch break,” says Mr Bloom, of Stanford University. “They sit there with a sandwich, answer some questions, and that pays for their lunch.”
Demand for research to understand a confusing economic situation jumped. The first analysis of America’s $600 weekly boost to unemployment insurance, implemented in March 2020, was published in weeks. The British government knew by October 2020 that a scheme to subsidise restaurant attendance in August 2020 had probably boosted covid infections. Many apparently self-evident things about the pandemic—that the economy collapsed in March 2020, that the poor have suffered more than the rich, or that the shift to working from home is turning out better than expected—only seem obvious because of rapid-fire economic research.
It is harder to quantify the policy impact. Some economists scoff at the notion that their research has influenced politicians’ pandemic response. Many studies using real-time data suggested that the Paycheck Protection Programme, an effort to channel money to American small firms, was doing less good than hoped. Yet small-business lobbyists ensured that politicians did not get rid of it for months. Tyler Cowen, of George Mason University, points out that the most significant contribution of economists during the pandemic involved recommending early pledges to buy vaccines—based on older research, not real-time data.
Still, Mr Faulkender says that the special support for restaurants that was included in America’s stimulus was influenced by a weak recovery in the industry seen in the OpenTable data. Research by Mr Chetty in early 2021 found that stimulus cheques sent in December boosted spending by lower-income households, but not much for richer households. He claims this informed the decision to place stronger income limits on the stimulus cheques sent in March.
Shaping the economic conversation
As for the Federal Reserve, in May 2020 the Dallas and New York regional Feds and James Stock, a Harvard economist, created an activity index using data from SafeGraph, a data provider that tracks mobility using mobile-phone pings. The St Louis Fed used data from Homebase to track employment numbers daily. Both showed shortfalls of economic activity in advance of official data. This led the Fed to communicate its doveish policy stance faster.
Speedy data also helped frame debate. Everyone realised the world was in a deep recession much sooner than they had in 2007-09. In the IMF’s overviews of the global economy in 2009, 40% of the papers cited had been published in 2008-09. In the overview published in October 2020, by contrast, over half the citations were for papers published that year.
The third wave of economics has been better for some practitioners than others. As lockdowns began, many male economists found themselves at home with no teaching responsibilities and more time to do research. Female ones often picked up the slack of child care. A paper in Covid Economics, a rapid-fire journal, finds that female authors accounted for 12% of economics working-paper submissions during the pandemic, compared with 20% before. Economists lucky enough to have researched topics before the pandemic which became hot, from home-working to welfare policy, were suddenly in demand.
There are also deeper shifts in the value placed on different sorts of research. The Economist has examined rankings of economists from IDEAS RePEC, a database of research, and citation data from Google Scholar. We divided economists into three groups: “lone wolves” (who publish with less than one unique co-author per paper on average); “collaborators” (those who tend to work with more than one unique co-author per paper, usually two to four people); and “lab leaders” (researchers who run a large team of dedicated assistants). We then looked at the top ten economists for each as measured by RePEC author rankings for the past ten years.
Collaborators performed far ahead of the other two groups during the pandemic (see chart 4). Lone wolves did worst: working with large data sets benefits from a division of labour. Why collaborators did better than lab leaders is less clear. They may have been more nimble in working with those best suited for the problems at hand; lab leaders are stuck with a fixed group of co-authors and assistants.
The most popular types of research highlight another aspect of the third wave: its usefulness for business. Scott Baker, another economist, and Messrs Bloom and Davis—three of the top four authors during the pandemic compared with the year before—are all “collaborators” and use daily newspaper data to study markets. Their uncertainty index has been used by hedge funds to understand the drivers of asset prices. The research by Messrs Bloom and Davis on working from home has also gained attention from businesses seeking insight on the transition to remote work.
But does it work in theory?
Not everyone likes where the discipline is going. When economists say that their fellows are turning into data scientists, it is not meant as a compliment. A kinder interpretation is that the shift to data-heavy work is correcting a historical imbalance. “The most important problem with macro over the past few decades has been that it has been too theoretical,” says Jón Steinsson of the University of California, Berkeley, in an essay published in July. A better balance with data improves theory. Half of the recent Nobel prize went for the application of new empirical methods to labour economics; the other half was for the statistical theory around such methods.
Some critics question the quality of many real-time sources. High-frequency data are less accurate at estimating levels (for example, the total value of GDP) than they are at estimating changes, and in particular turning-points (such as when growth turns into recession). In a recent review of real-time indicators Samuel Tombs of Pantheon Macroeconomics, a consultancy, pointed out that OpenTable data tended to exaggerate the rebound in restaurant attendance last year.
Others have worries about the new incentives facing economists. Researchers now race to post a working paper with America’s National Bureau of Economic Research in order to stake their claim to an area of study or to influence policymakers. The downside is that consumers of fast-food academic research often treat it as if it is as rigorous as the slow-cooked sort—papers which comply with the old-fashioned publication process involving endless seminars and peer review. A number of papers using high-frequency data which generated lots of clicks, including one which claimed that a motorcycle rally in South Dakota had caused a spike in covid cases, have since been called into question.
Whatever the concerns, the pandemic has given economists a new lease of life. During the Chilean coup of 1973 members of the armed forces broke into Cybersyn’s operations room and smashed up the slides of graphs—not only because it was Allende’s creation, but because the idea of an electrocardiogram of the economy just seemed a bit weird. Third-wave economics is still unusual, but ever less odd. ■
A new paper explores how the opinions of an electorate may be reflected in a mathematical model ‘inspired by models of simple magnetic systems’
Date: October 8, 2021
Source: University at Buffalo
Summary: A study leverages concepts from physics to model how campaign strategies influence the opinions of an electorate in a two-party system.
A study in the journal Physica A leverages concepts from physics to model how campaign strategies influence the opinions of an electorate in a two-party system.
Researchers created a numerical model that describes how external influences, modeled as a random field, shift the views of potential voters as they interact with each other in different political environments.
The model accounts for the behavior of conformists (people whose views align with the views of the majority in a social network); contrarians (people whose views oppose the views of the majority); and inflexibles (people who will not change their opinions).
“The interplay between these behaviors allows us to create electorates with diverse behaviors interacting in environments with different levels of dominance by political parties,” says first author Mukesh Tiwari, PhD, associate professor at the Dhirubhai Ambani Institute of Information and Communication Technology.
“We are able to model the behavior and conflicts of democracies, and capture different types of behavior that we see in elections,” says senior author Surajit Sen, PhD, professor of physics in the University at Buffalo College of Arts and Sciences.
Sen and Tiwari conducted the study with Xiguang Yang, a former UB physics student. Jacob Neiheisel, PhD, associate professor of political science at UB, provided feedback to the team, but was not an author of the research. The study was published online in Physica A in July and will appear in the journal’s Nov. 15 volume.
The model described in the paper has broad similarities to the random field Ising model, and “is inspired by models of simple magnetic systems,” Sen says.
The team used this model to explore a variety of scenarios involving different types of political environments and electorates.
Among key findings, as the authors write in the abstract: “In an electorate with only conformist agents, short-duration high-impact campaigns are highly effective. … In electorates with both conformist and contrarian agents and varying level(s) of dominance due to local factors, short-term campaigns are effective only in the case of fragile dominance of a single party. Strong local dominance is relatively difficult to influence and long-term campaigns with strategies aimed to impact local level politics are seen to be more effective.”
“I think it’s exciting that physicists are thinking about social dynamics. I love the big tent,” Neiheisel says, noting that one advantage of modeling is that it could enable researchers to explore how opinions might change over many election cycles — the type of longitudinal data that’s very difficult to collect.
Mathematical modeling has some limitations: “The real world is messy, and I think we should embrace that to the extent that we can, and models don’t capture all of this messiness,” Neiheisel says.
But Neiheisel was excited when the physicists approached him to talk about the new paper. He says the model provides “an interesting window” into processes associated with opinion dynamics and campaign effects, accurately capturing a number of effects in a “neat way.”
“The complex dynamics of strongly interacting, nonlinear and disordered systems have been a topic of interest for a long time,” Tiwari says. “There is a lot of merit in studying social systems through mathematical and computational models. These models provide insight into short- and long-term behavior. However, such endeavors can only be successful when social scientists and physicists come together to collaborate.”
Journal Reference:
Mukesh Tiwari, Xiguang Yang, Surajit Sen. Modeling the nonlinear effects of opinion kinematics in elections: A simple Ising model with random field based study. Physica A: Statistical Mechanics and its Applications, 2021; 582: 126287 DOI: 10.1016/j.physa.2021.126287
From top left: Mariana Mazzucato, Carlota Perez, Kate Raworth, Stephanie Kelton, Esther Duflo. 20-first
Few economists become household names. Last century, it was John Maynard Keynes or Milton Friedman. Today, Thomas Piketty has become the economists’ poster-boy. Yet listen to the buzz, and it is five female economists who deserve our attention. They are revolutionising their field by questioning the meaning of everything from ‘value’ and ‘debt’ to ‘growth’ and ‘GDP.’ Esther Duflo, Stephanie Kelton, Mariana Mazzucato, Carlota Perez and Kate Raworth are united in one thing: their amazement at the way economics has been defined and debated to date. Their incredulity is palpable.
It reminds me of many women I’ve seen emerge into power over the past decade. Like Rebecca Henderson, a Management and Strategy professor at Harvard Business School and author of the new Reimagining Capitalism in a World on Fire. “It’s odd to finally make it to the inner circle,” she says, “and discover just how strangely the world is being run.” When women finally make it to the pinnacle of many professions, they often discover a world more wart-covered frog than handsome prince. Like Dorothy in The Wizard of Oz, when they get a glimpse behind the curtain, they discover the machinery of power can be more bluster than substance. As newcomers to the game, they can often see this more clearly than the long-term players. Henderson cites Tom Toro’s cartoon as her mantra. A group in rags sit around a fire with the ruins of civilisation in the background. “Yes, the planet got destroyed” says a man in a disheveled suit, “but for a beautiful moment in time we created a lot of value for shareholders.”
You get the same sense when you listen to the female economists throwing themselves into the still very male dominated economics field. A kind of collective ‘you’re kidding me, right? These five female economists are letting the secret out – and inviting people to flip the priorities. A growing number are listening – even the Pope (see below).
All question concepts long considered sacrosanct. Here are four messages they share:
Get Over It – Challenge the Orthodoxy
Described as “one of the most forward-thinking economists of our times,” Mariana Mazzucato is foremost among the flame throwers. A professor at University College London and the Founder/Director of the UCL Institute for Innovation and Public Purpose, she asks fundamental questions about how ‘value’ has been defined, who decides what that means, and who gets to measure it. Her TED talk, provocatively titled “What is economic value? And who creates it?” lays down the gauntlet. If some people are value creators,” she asks, what does that make everyone else? “The couch potatoes? The value extractors? The value destroyers?” She wants to make economics explicitly serve the people, rather than explain their servitude.
Stephanie Kelton takes on our approach to debt and spoofs the simplistic metaphors, like comparing national income and expenditure to ‘family budgets’ in an attempt to prove how dangerous debt is. In her upcoming book, The Deficit Myth (June 2020), she argues they are not at all similar; what household can print additional money, or set interest rates? Debt should be rebranded as a strategic investment in the future. Deficits can be used in ways good or bad but are themselves a neutral and powerful policy tool. “They can fund unjust wars that destabilize the world and cost millions their lives,” she writes, “or they can be used to sustain life and build a more just economy that works for the many and not just the few.” Like all the economists profiled here, she’s pointing at the mind and the meaning behind the money.
Get Green Growth – Reshaping Growth Beyond GDP
Kate Raworth, a Senior Research Associate at Oxford University’s Environmental Change Institute, is the author of Doughnut Economics. She challenges our obsession with growth, and its outdated measures. The concept of Gross Domestic Product (GDP), was created in the 1930s and is being applied in the 21st century to an economy ten times larger. GDP’s limited scope (eg. ignoring the value of unpaid labour like housework and parenting or making no distinction between revenues from weapons or water) has kept us “financially, politically and socially addicted to growth” without integrating its costs on people and planet. She is pushing for new visual maps and metaphors to represent sustainable growth that doesn’t compromise future generations. What this means is moving away from the linear, upward moving line of ‘progress’ ingrained in us all, to a “regenerative and distributive” model designed to engage everyone and shaped like … a doughnut (food and babies figure prominently in these women’s metaphors).
Carlota Perez doesn’t want to stop or slow growth, she wants to dematerialize it. “Green won’t spread by guilt and fear, we need aspiration and desire,” she says. Her push is towards a redefinition of the ‘good life’ and the need for “smart green growth” to be fuelled by a desire for new, attractive and aspirational lifestyles. Lives will be built on a circular economy that multiplies services and intangibles which offer limitless (and less environmentally harmful) growth. She points to every technological revolution creating new lifestyles. She says we can see it emerging, as it has in the past, among the educated, the wealthy and the young: more services rather than more things, active and creative work, a focus on health and care, a move to solar power, intense use of the internet, a preference for customisation over conformity, renting vs owning, and recycling over waste. As these new lifestyles become widespread, they offer immense opportunities for innovation and new jobs to service them.
Get Good Government – The Strategic Role of the State
All these economists want the state to play a major role. Women understand viscerally how reliant the underdogs of any system are on the inclusivity of the rules of the game. “It shapes the context to create a positive sum game” for both the public and business, says Perez. You need an active state to “tilt the playing field toward social good.” Perez outlines five technological revolutions, starting with the industrial one. She suggests we’re halfway through the fifth, the age of Tech & Information. Studying the repetitive arcs of each revolution enables us to see the opportunity of the extraordinary moment we are in. It’s the moment to shape the future for centuries to come. But she balances economic sustainability with the need for social sustainability, warning that one without the other is asking for trouble.
Mariana Mazzucato challenges governments to be more ambitious. They gain confidence and public trust by remembering and communicating what they are there to do. In her mind that is ensuring the public good. This takes vision and strategy, two ingredients she says are too often sorely lacking. Especially post-COVID, purpose needs to be the driver determining the ‘directionality’ of focus, investments and public/ private partnerships. Governments should be using their power – both of investment and procurement – to orient efforts towards the big challenges on our horizon, not just the immediate short-term recovery. They should be putting conditions on the massive financial bail outs they are currently handing out. She points to the contrast in imagination and impact between airline bailouts in Austria and the UK. The Austrian airlines are getting government aid on the condition they meet agreed emissions targets. The UK is supporting airlines without any conditionality, a huge missed opportunity to move towards larger, broader goals of building a better and greener economy out of the crisis.
Get Real – Beyond the Formulae and Into the Field
All of these economists also argue for getting out of the theories and into the field. They reject the idea of nerdy theoretical calculations done within the confines of a university tower and challenge economists to experiment and test their formulae in the real world.
Esther Duflo, Professor of Poverty Alleviation and Development Economics at MIT, is the major proponent of bringing what is accepted practice in medicine to the field of economics: field trials with randomised control groups. She rails against the billions poured into aid without any actual understanding or measurement of the returns. She gently accuses us of being no better with our 21st century approaches to problems like immunisation, education or malaria than any medieval doctor, throwing money and solutions at things with no idea of their impact. She and her husband, Abhijit Banerjee, have pioneered randomised control trials across hundreds of locations in different countries of the world, winning a Nobel Prize for Economics in 2019 for the insights.
They test, for example, how to get people to use bed nets against malaria. Nets are a highly effective preventive measure but getting people to acquire and use them has been a hard nut to crack. Duflo set up experiments to answer the conundrums: If people have to pay for nets, will they value them more? If they are free, will they use them? If they get them free once, will this discourage future purchases? As it turns out, based on these comparisons, take-up is best if nets are initially given, “people don’t get used to handouts, they get used to nets,” and will buy them – and use them – once they understand their effectiveness. Hence, she concludes, we can target policy and money towards impact.
Mazzucato is also hands-on with a number of governments around the world, including Denmark, the UK, Austria, South Africa and even the Vatican, where she has just signed up for weekly calls contributing to a post-Covid policy. ‘I believe [her vision] can help to think about the future,’ Pope Francis said after reading her book, The Value of Everything: Making and Taking in the Global Economy. No one can accuse her of being stuck in an ivory tower. Like Duflo, she is elbow-deep in creating new answers to seemingly intractable problems.
She warns that we don’t want to go back to normal after Covid-19. Normal was what got us here. Instead, she invites governments to use the crisis to embed ‘directionality’ towards more equitable public good into their recovery strategies and investments. Her approach is to define ambitious ‘missions’ which can focus minds and bring together broad coalitions of stakeholders to create solutions to support them. The original NASA mission to the moon is an obvious precursor model. Why, anyone listening to her comes away thinking, did we forget purpose in our public spending? And why, when so much commercial innovation and profit has grown out of government basic research spending, don’t a greater share of the fruits of success return to promote the greater good?
Economics has long remained a stubbornly male domain and men continue to dominate mainstream thinking. Yet, over time, ideas once considered without value become increasingly visible. The move from outlandish to acceptable to policy is often accelerated by crisis. Emerging from this crisis, five smart economists are offering an innovative range of new ideas about a greener, healthier and more inclusive way forward. Oh, and they happen to be women.
Large, expensive efforts to map the brain started a decade ago but have largely fallen short. It’s a good reminder of just how complex this organ is.
Emily Mullin
August 25, 2021
In September 2011, a group of neuroscientists and nanoscientists gathered at a picturesque estate in the English countryside for a symposium meant to bring their two fields together.
At the meeting, Columbia University neurobiologist Rafael Yuste and Harvard geneticist George Church made a not-so-modest proposal: to map the activity of the entire human brain at the level of individual neurons and detail how those cells form circuits. That knowledge could be harnessed to treat brain disorders like Alzheimer’s, autism, schizophrenia, depression, and traumatic brain injury. And it would help answer one of the great questions of science: How does the brain bring about consciousness?
Yuste, Church, and their colleagues drafted a proposal that would later be published in the journal Neuron. Their ambition was extreme: “a large-scale, international public effort, the Brain Activity Map Project, aimed at reconstructing the full record of neural activity across complete neural circuits.” Like the Human Genome Project a decade earlier, they wrote, the brain project would lead to “entirely new industries and commercial ventures.”
New technologies would be needed to achieve that goal, and that’s where the nanoscientists came in. At the time, researchers could record activity from just a few hundred neurons at once—but with around 86 billion neurons in the human brain, it was akin to “watching a TV one pixel at a time,” Yuste recalled in 2017. The researchers proposed tools to measure “every spike from every neuron” in an attempt to understand how the firing of these neurons produced complex thoughts.
But it wasn’t the first audacious brain venture. In fact, a few years earlier, Henry Markram, a neuroscientist at the École Polytechnique Fédérale de Lausanne in Switzerland, had set an even loftier goal: to make a computer simulation of a living human brain. Markram wanted to build a fully digital, three-dimensional model at the resolution of the individual cell, tracing all of those cells’ many connections. “We can do it within 10 years,” he boasted during a 2009 TED talk.
In January 2013, a few months before the American project was announced, the EU awarded Markram $1.3 billion to build his brain model. The US and EU projects sparked similar large-scale research efforts in countries including Japan, Australia, Canada, China, South Korea, and Israel. A new era of neuroscience had begun.
An impossible dream?
A decade later, the US project is winding down, and the EU project faces its deadline to build a digital brain. So how did it go? Have we begun to unwrap the secrets of the human brain? Or have we spent a decade and billions of dollars chasing a vision that remains as elusive as ever?
From the beginning, both projects had critics.
EU scientists worried about the costs of the Markram scheme and thought it would squeeze out other neuroscience research. And even at the original 2011 meeting in which Yuste and Church presented their ambitious vision, many of their colleagues argued it simply wasn’t possible to map the complex firings of billions of human neurons. Others said it was feasible but would cost too much money and generate more data than researchers would know what to do with.
In a blistering article appearing in Scientific American in 2013, Partha Mitra, a neuroscientist at the Cold Spring Harbor Laboratory, warned against the “irrational exuberance” behind the Brain Activity Map and questioned whether its overall goal was meaningful.
Even if it were possible to record all spikes from all neurons at once, he argued, a brain doesn’t exist in isolation: in order to properly connect the dots, you’d need to simultaneously record external stimuli that the brain is exposed to, as well as the behavior of the organism. And he reasoned that we need to understand the brain at a macroscopic level before trying to decode what the firings of individual neurons mean.
Others had concerns about the impact of centralizing control over these fields. Cornelia Bargmann, a neuroscientist at Rockefeller University, worried that it would crowd out research spearheaded by individual investigators. (Bargmann was soon tapped to co-lead the BRAIN Initiative’s working group.)
There isn’t a single, agreed-upon theory of how the brain works, and not everyone in the field agreed that building a simulated brain was the best way to study it.
While the US initiative sought input from scientists to guide its direction, the EU project was decidedly more top-down, with Markram at the helm. But as Noah Hutton documents in his 2020 film In Silico, Markram’s grand plans soon unraveled. As an undergraduate studying neuroscience, Hutton had been assigned to read Markram’s papers and was impressed by his proposal to simulate the human brain; when he started making documentary films, he decided to chronicle the effort. He soon realized, however, that the billion-dollar enterprise was characterized more by infighting and shifting goals than by breakthrough science.
In Silico shows Markram as a charismatic leader who needed to make bold claims about the future of neuroscience to attract the funding to carry out his particular vision. But the project was troubled from the outset by a major issue: there isn’t a single, agreed-upon theory of how the brain works, and not everyone in the field agreed that building a simulated brain was the best way to study it. It didn’t take long for those differences to arise in the EU project.
In 2014, hundreds of experts across Europe penned a letter citing concerns about oversight, funding mechanisms, and transparency in the Human Brain Project. The scientists felt Markram’s aim was premature and too narrow and would exclude funding for researchers who sought other ways to study the brain.
“What struck me was, if he was successful and turned it on and the simulated brain worked, what have you learned?” Terry Sejnowski, a computational neuroscientist at the Salk Institute who served on the advisory committee for the BRAIN Initiative, told me. “The simulation is just as complicated as the brain.”
The Human Brain Project’s board of directors voted to change its organization and leadership in early 2015, replacing a three-member executive committee led by Markram with a 22-member governing board. Christoph Ebell, a Swiss entrepreneur with a background in science diplomacy, was appointed executive director. “When I took over, the project was at a crisis point,” he says. “People were openly wondering if the project was going to go forward.”
But a few years later he was out too, after a “strategic disagreement” with the project’s host institution. The project is now focused on providing a new computational research infrastructure to help neuroscientists store, process, and analyze large amounts of data—unsystematic data collection has been an issue for the field—and develop 3D brain atlases and software for creating simulations.
The US BRAIN Initiative, meanwhile, underwent its own changes. Early on, in 2014, responding to the concerns of scientists and acknowledging the limits of what was possible, it evolved into something more pragmatic, focusing on developing technologies to probe the brain.
New day
Those changes have finally started to produce results—even if they weren’t the ones that the founders of each of the large brain projects had originally envisaged.
And earlier this year Alipasha Vaziri, a neuroscientist funded by the BRAIN Initiative, and his team at Rockefeller University reported in a preprint paper that they’d simultaneously recorded the activity of more than a million neurons across the mouse cortex. It’s the largest recording of animal cortical activity yet made, if far from listening to all 86 billion neurons in the human brain as the original Brain Activity Map hoped.
The US effort has also shown some progress in its attempt to build new tools to study the brain. It has speeded the development of optogenetics, an approach that uses light to control neurons, and its funding has led to new high-density silicon electrodes capable of recording from hundreds of neurons simultaneously. And it has arguably accelerated the development of single-cell sequencing. In September, researchers using these advances will publish a detailed classification of cell types in the mouse and human motor cortexes—the biggest single output from the BRAIN Initiative to date.
While these are all important steps forward, though, they’re far from the initial grand ambitions.
Lasting legacy
We are now heading into the last phase of these projects—the EU effort will conclude in 2023, while the US initiative is expected to have funding through 2026. What happens in these next years will determine just how much impact they’ll have on the field of neuroscience.
When I asked Ebell what he sees as the biggest accomplishment of the Human Brain Project, he didn’t name any one scientific achievement. Instead, he pointed to EBRAINS, a platform launched in April of this year to help neuroscientists work with neurological data, perform modeling, and simulate brain function. It offers researchers a wide range of data and connects many of the most advanced European lab facilities, supercomputing centers, clinics, and technology hubs in one system.
“If you ask me ‘Are you happy with how it turned out?’ I would say yes,” Ebell said. “Has it led to the breakthroughs that some have expected in terms of gaining a completely new understanding of the brain? Perhaps not.”
Katrin Amunts, a neuroscientist at the University of Düsseldorf, who has been the Human Brain Project’s scientific research director since 2016, says that while Markram’s dream of simulating the human brain hasn’t been realized yet, it is getting closer. “We will use the last three years to make such simulations happen,” she says. But it won’t be a big, single model—instead, several simulation approaches will be needed to understand the brain in all its complexity.
Meanwhile, the BRAIN Initiative has provided more than 900 grants to researchers so far, totaling around $2 billion. The National Institutes of Health is projected to spend nearly $6 billion on the project by the time it concludes.
For the final phase of the BRAIN Initiative, scientists will attempt to understand how brain circuits work by diagramming connected neurons. But claims for what can be achieved are far more restrained than in the project’s early days. The researchers now realize that understanding the brain will be an ongoing task—it’s not something that can be finalized by a project’s deadline, even if that project meets its specific goals.
“With a brand-new tool or a fabulous new microscope, you know when you’ve got it. If you’re talking about understanding how a piece of the brain works or how the brain actually does a task, it’s much more difficult to know what success is,” says Eve Marder, a neuroscientist at Brandeis University. “And success for one person would be just the beginning of the story for another person.”
Yuste and his colleagues were right that new tools and techniques would be needed to study the brain in a more meaningful way. Now, scientists will have to figure out how to use them. But instead of answering the question of consciousness, developing these methods has, if anything, only opened up more questions about the brain—and shown just how complex it is.
“I have to be honest,” says Yuste. “We had higher hopes.”
Emily Mullin is a freelance journalist based in Pittsburgh who focuses on biotechnology.
The social cost of carbon could guide us toward intellinget policies – only if we knew what it was.
In contrast to the existential angst currently in fashion around climate change, there’s a cold-eyed calculation that its advocates, mostly economists, like to call the most important number you’ve never heard of.
It’s the social cost of carbon. It reflects the global damage of emitting one ton of carbon dioxide into the sky, accounting for its impact in the form of warming temperatures and rising sea levels. Economists, who have squabbled over the right number for a decade, see it as a powerful policy tool that could bring rationality to climate decisions. It’s what we should be willing to pay to avoid emitting that one more ton of carbon.
This story was part of our May 2019 issue
For most of us, it’s a way to grasp how much our carbon emissions will affect the world’s health, agriculture, and economy for the next several hundred years. Maximilian Auffhammer, an economist at the University of California, Berkeley, describes it this way: it’s approximately the damage done by driving from San Francisco to Chicago, assuming that about a ton of carbon dioxide spits out of the tailpipe over those 2,000 miles.
Common estimates of the social cost of that ton are $40 to $50. The cost of the fuel for the journey in an average car is currently around $225. In other words, you’d pay roughly 20% more to take the social cost of the trip into account.
The number is contentious, however. A US federal working group in 2016, convened by President Barack Obama, calculated it at around $40, while the Trump administration has recently put it at $1 to $7. Some academic researchers cite numbers as high as $400 or more.
Why so wide a range? It depends on how you value future damages. And there are uncertainties over how the climate will respond to emissions. But another reason is that we actually have very little insight into just how climate change will affect us over time. Yes, we know there’ll be fiercer storms and deadly wildfires, heat waves, droughts, and floods. We know the glaciers are melting rapidly and fragile ocean ecosystems are being destroyed. But what does that mean for the livelihood or life expectancy of someone in Ames, Iowa, or Bangalore, India, or Chelyabinsk, Russia?
For the first time, vast amounts of data on the economic and social effects of climate change are becoming available, and so is the computational power to make sense of it. Taking this opportunity to compute a precise social cost of carbon could help us decide how much to invest and which problems to tackle first.
“It is the single most important number in the global economy,” says Solomon Hsiang, a climate policy expert at Berkeley. “Getting it right is incredibly important. But right now, we have almost no idea what it is.”
That could soon change.
The cost of death
In the past, calculating the social cost of carbon typically meant estimating how climate change would slow worldwide economic growth. Computer models split the world into at most a dozen or so regions and then averaged the predicted effects of climate change to get the impact on global GDP over time. It was at best a crude number.
Over the last several years, economists, data scientists, and climate scientists have worked together to create far more detailed and localized maps of impacts by examining how temperatures, sea levels, and precipitation patterns have historically affected things like mortality, crop yields, violence, and labor productivity. This data can then be plugged into increasingly sophisticated climate models to see what happens as the planet continues to warm.
The wealth of high-resolution data makes a far more precise number possible—at least in theory. Hsiang is co-director of the Climate Impact Lab, a team of some 35 scientists from institutions including the University of Chicago, Berkeley, Rutgers, and the Rhodium Group, an economic research organization. Their goal is to come up with a number by looking at about 24,000 different regions and adding together the diverse effects that each will experience over the coming hundreds of years in health, human behavior, and economic activity.
It’s a huge technical and computational challenge, and it will take a few years to come up with a single number. But along the way, the efforts to better understand localized damages are creating a nuanced and disturbing picture of our future.
So far, the researchers have found that climate change will kill far more people than once thought. Michael Greenstone, a University of Chicago economist who co-directs the Climate Impact Lab with Hsiang, says that previous mortality estimates had looked at seven wealthy cities, most in relatively cool climates. His group looked at data gleaned from 56% of the world’s population. It found that the social cost of carbon due to increased mortality alone is $30, nearly as high as the Obama administration’s estimate for the social cost of all climate impacts. An additional 9.1 million people will die every year by 2100, the group estimates, if climate change is left unchecked (assuming a global population of 12.7 billion people).
Unfairly Distributed
However, while the Climate Impact Lab’s analysis showed that 76% of the world’s population would suffer from higher mortality rates, it found that warming temperatures would actually save lives in a number of northern regions. That’s consistent with other recent research; the impacts of climate change will be remarkably uneven.
The variations are significant even within some countries. In 2017, Hsiang and his collaborators calculated climate impacts county by county in the United States. They found that every degree of warming would cut the country’s GDP by about 1.2%, but the worst-hit counties could see a drop of around 20%.
If climate change is left to run unchecked through the end of the century, the southern and southwestern US will be devastated by rising rates of mortality and crop failure. Labor productivity will slow, and energy costs (especially due to air-conditioning) will rise. In contrast, the northwestern and parts of the northeastern US will benefit.
“It is a massive restructuring of wealth,” says Hsiang. This is the most important finding of the last several years of climate economics, he adds. By examining ever smaller regions, you can see “the incredible winners and losers.” Many in the climate community have been reluctant to talk about such findings, he says. “But we have to look [the inequality] right in the eye.”
The social cost of carbon is typically calculated as a single global number. That makes sense, since the damage of a ton of carbon emitted in one place is spread throughout the world. But last year Katharine Ricke, a climate scientist at UC San Diego and the Scripps Institution of Oceanography, published the social costs of carbon for specific countries to help parse out regional differences.
India is the big loser. Not only does it have a fast-growing economy that will be slowed, but it’s already a hot country that will suffer greatly from getting even hotter. “India bears a huge share of the global social cost of carbon—more than 20%,” says Ricke. It also stands out for how little it has actually contributed to the world’s carbon emissions. “It’s a serious equity issue,” she says.
Estimating the global social cost of carbon also raises a vexing question: How do you put a value on future damages? We should invest now to help our children and grandchildren avoid suffering, but how much? This is hotly and often angrily debated among economists.
A standard tool in economics is the discount rate, used to calculate how much we should invest now for a payoff years from now. The higher the discount rate, the less you value the future benefit. William Nordhaus, who won the 2018 Nobel Prize in economics for pioneering the use of models to show the macroeconomic effects of climate change, has used a discount rate of around 4%. The relatively high rate suggests we should invest conservatively now. In sharp contrast, a landmark 2006 report by British economist Nicholas Stern used a discount rate of 1.4%, concluding that we should begin investing much more heavily to slow climate change.
There’s an ethical dimension to these calculations. Wealthy countries whose prosperity has been built on fossil fuels have an obligation to help poorer countries. The climate winners can’t abandon the losers. Likewise, we owe future generations more than just financial considerations. What’s the value of a world free from the threat of catastrophic climate events—one with healthy and thriving natural ecosystems?
Outrage
Enter the Green New Deal (GND). It’s the sweeping proposal issued earlier this year by Representative Alexandria Ocasio-Cortez and other US progressives to address everything from climate change to inequality. It cites the dangers of temperature increases beyond the UN goal of 1.5 °C and makes a long list of recommendations. Energy experts immediately began to bicker over its details: Is achieving 100% renewables in the next 12 years really feasible? (Probably not.) Should it include nuclear power, which many climate activists now argue is essential for reducing emissions?
In reality, the GND has little to say about actual policies and there’s barely a hint of how it will attack its grand challenges, from providing a secure retirement for all to fostering family farms to ensuring access to nature. But that’s not the point. The GND is a cry of outrage against what it calls “the twin crises of climate change and worsening income inequality.” It’s a political attempt to make climate change part of the wider discussion about social justice. And, at least from the perspective of climate policy, it’s right in arguing that we can’t tackle global warming without considering broader social and economic issues.
The work of researchers like Ricke, Hsiang, and Greenstone supports that stance. Not only do their findings show that global warming can worsen inequality and other social ills; they provide evidence that aggressive action is worth it. Last year, researchers at Stanford calculated that limiting warming to 1.5 °C would save upwards of $20 trillion worldwide by the end of the century. Again, the impacts were mixed—the GDPs of some countries would be harmed by aggressive climate action. But the conclusion was overwhelming: more than 90% of the world’s population would benefit. Moreover, the cost of keeping temperature increases limited to 1.5 °C would be dwarfed by the long-term savings.
Nevertheless, the investments will take decades to pay for themselves. Renewables and new clean technologies may lead to a boom in manufacturing and a robust economy, but the Green New Deal is wrong to paper over the financial sacrifices we’ll need to make in the near term.
That is why climate remedies are such a hard sell. We need a global policy—but, as we’re always reminded, all politics is local. Adding 20% to the cost of that San Francisco–Chicago trip might not seem like much, but try to convince a truck driver in a poor county in Florida that raising the price of fuel is wise economic policy. A much smaller increase sparked the gilets jaunes riots in France last winter. That is the dilemma, both political and ethical, that we all face with climate change.
As the Intergovernmental Panel on Climate Change (IPCC) released its Sixth Assessment Report, summarized nicely on these pages by Bob Henson, much of the associated media coverage carried a tone of inevitable doom.
These proclamations of unavoidable adverse outcomes center around the fact that in every scenario considered by IPCC, within the next decade average global temperatures will likely breach the aspirational goal set in the Paris climate agreement of limiting global warming to 1.5 degrees Celsius (2.7 degrees Fahrenheit) above pre-industrial temperatures. The report also details a litany of extreme weather events like heatwaves, droughts, wildfires, floods, and hurricanes that will all worsen as long as global temperatures continue to rise.
While United Nations Secretary-General António Guterres rightly called the report a “code red for humanity,” tucked into it are details illustrating that if – BIG IF –top-emitting countries respond to the IPCC’s alarm bells with aggressive efforts to curb carbon pollution, the worst climate outcomes remain avoidable.
The IPCC’s future climate scenarios
In the Marvel film Avengers: Infinity War, the Dr. Strange character goes forward in time to view 14,000,605 alternate futures to see all the possible outcomes of the Avengers’ coming conflict. Lacking the fictional Time Stone used in this gambit, climate scientists instead ran hundreds of simulations of several different future carbon emissions scenarios using a variety of climate models. Like Dr. Strange, climate scientists’ goal is to determine the range of possible outcomes given different actions taken by the protagonists: in this case, various measures to decarbonize the global economy.
The scenarios considered by IPCC are called Shared Socioeconomic Pathways (SSPs). The best-case climate scenario, called SSP1, involves a global shift toward sustainable management of global resources and reduced inequity. The next scenario, SSP2, is more of a business-as-usual path with slow and uneven progress toward sustainable development goals and persisting income inequality and environmental degradation. SSP3 envisions insurgent nationalism around the world with countries focusing on their short-term domestic best interests, resulting in persistent and worsening inequality and environmental degradation. Two more scenarios, SSP4 and SSP5, consider even greater inequalities and fossil fuel extraction, but seem at odds with an international community that has agreed overwhelmingly to aim for the Paris climate targets.
The latest IPCC report’s model runs simulated two SSP1 scenarios that would achieve the Paris targets of limiting global warming to 1.5 and 2°C (2.7 and 3.6°F); one SSP2 scenario in which temperatures approach 3°C (5.4°F) in the year 2100; an SSP3 scenario with about 4°C (7.2°F) global warming by the end of the century; and one SSP5 ‘burn all the fossil fuels possible’ scenario resulting in close to 5°C (9°F), again by 2100.
Projected global average surface temperature change in each of the five SSP scenarios. (Source: IPCC Sixth Assessment Report)
The report’s SSP3-7.0 pathway (the latter number represents the eventual global energy imbalance caused by the increased greenhouse effect, in watts per square meter), is considered by many experts to be a realistic worst-case scenario, with global carbon emissions continuing to rise every year throughout the 21st century. Such an outcome would represent a complete failure of international climate negotiations and policies and would likely result in catastrophic consequences, including widespread species extinctions, food and water shortages, and disastrous extreme weather events.
Scenario SSP2-4.5 is more consistent with government climate policies that are currently in place. It envisions global carbon emissions increasing another 10% over the next decade before reaching a plateau that’s maintained until carbon pollution slowly begins to decline starting in the 2050s. Global carbon emissions approach but do not reach zero by the end of the century. Even in this unambitious scenario, the very worst climate change impacts might be averted, although the resulting climate impacts would be severe.
Most encouragingly, the report’s two SSP1 scenarios illustrate that the Paris targets remain within reach. To stay below the main Paris target of 2°C (3.6°F) warming, global carbon emissions in SSP1-2.6 plateau essentially immediately and begin to decline after 2025 at a modest rate of about 2% per year for the first decade, then accelerating to around 3% per year the next decade, and continuing along a path of consistent year-to-year carbon pollution cuts before reaching zero around 2075. The IPCC concluded that once global carbon emissions reach zero, temperatures will stop rising. Toward the end of the century, emissions in SSP1-2.6 move into negative territory as the IPCC envisions that efforts to remove carbon from the atmosphere via natural and technological methods (like sequestering carbon in agricultural soils and scrubbing it from the atmosphere through direct air capture) outpace overall fossil fuel emissions.
Meeting the aspirational Paris goal of limiting global warming to 1.5°C (2.7°F) in SSP1-1.9 would be extremely challenging, given that global temperatures are expected to breach this level within about a decade. This scenario similarly envisions that global carbon emissions peak immediately and that they decline much faster than in SSP1-2.6, at a rate of about 6% per year from 2025 to 2035 and 9% per year over the following decade, reaching net zero by around the year 2055 and becoming net negative afterwards.
Global carbon dioxide emissions (in billions of tons per year) from 2015 to 2100 in each of the five SSP scenarios. (Source: IPCC Sixth Assessment Report)
For perspective, global carbon emissions fell by about 6-7% in 2020 as a result of restrictions associated with the COVID-19 pandemic and are expected to rebound by a similar amount in 2021. As IPCC report contributor Zeke Hausfather noted, this scenario also relies on large-scale carbon sequestration technologies that currently do not exist, without which global emissions would have to reach zero a decade sooner.
More warming means more risk
The new IPCC report details that, depending on the region, climate change has already worsened extreme heat, drought, fires, floods, and hurricanes, and those will only become more damaging and destructive as temperatures continue to rise. The IPCC’s 2018 “1.5°C Report” had entailed the differences in climate consequences in a 2°C vs. 1.5°C world, as summarized at this site by Bruce Lieberman.
Consider that in the current climate of just over 1°C (2°F) warmer than pre-industrial temperatures, 40 countries this summer alone have experienced extreme flooding, including more than a year’s worth of rain falling within 24 hours in Zhengzhou, China. Many regions have also experienced extreme heat, including the deadly Pacific Northwest heatwave and dangerously hot conditions during the Olympics in Tokyo. Siberia, Greece, Italy, and the US west coast are experiencing explosive wildfires, including the “truly frightening fire behavior” of the Dixie fire, which broke the record as the largest single wildfire on record in California. The IPCC report warned of “compound events” like heat exacerbating drought, which in turn fuels more dangerous wildfires, as is happening in California.
Western North America (WNA) and the Mediterranean (MED) regions are those for which climate scientists have the greatest confidence that human-caused global warming is exacerbating drought by drying out the soil. (Source: IPCC Sixth Assessment Report)The southwestern United States and Mediterranean are also among the regions for which climate scientists have the greatest confidence that climate change will continue to increase drought risk and severity. (Source: IPCC Sixth Assessment Report)
The IPCC report notes that the low-emissions SSP1 scenarios “would lead to substantially smaller changes” in these sorts of climate impact drivers than the higher-emissions scenarios. It also points out that with the world currently at around 1°C of warming, the intensity of extreme weather will be twice as bad compared to today’s conditions if temperatures reach 2°C (1°C hotter than today) than if the warming is limited to 1.5°C (0.5°C hotter than today), and quadruple as bad if global warming reaches 3°C (2°C hotter than today). For example, what was an extreme once-in-50-years heat wave in the late-1800s now occurs once per decade, which would rise to almost twice per decade at 1.5°C, and nearly three times per decade at 2°C global warming.
The increasing frequency and intensity of what used to be 1-in-50-year extreme heat as global temperatures rise. (Source: IPCC Sixth Assessment Report)
Climate’s fate has yet to be written
At the same time, there is no tipping point temperature at which it becomes “too late” to curb climate change and its damaging consequences. Every additional bit of global warming above current temperatures will result in increased risks of worsening extreme weather of the sorts currently being experienced around the world. Achieving the aspirational 1.5°C Paris target may be politically infeasible, but most countries (137 total) have either committed to or are in the process of setting a target for net zero emissions by 2050 (including the United States) or 2060 (including China).
That makes the SSP1 scenarios and limiting global warming to less than 2°C a distinct possibility, depending on how successful countries are at following through with decarbonization plans over the coming three decades. And with its proposed infrastructure bipartisan and budget reconciliation legislative plans – for which final enactment of each remains another big IF – the United States could soon implement some of the bold investments and policies necessary to set the world’s second-largest carbon polluter on a track consistent with the Paris targets.
Again and again, assessment after assessment, the IPCC has already made it clear. Climate change puts at risk every aspect of human life as we know it … We are already starting to experience those risks today; but we know what we need to do to avoid the worst future impacts. The difference between a fossil fuel versus a clean energy future is nothing less than the future of civilization as we know it.
Back to the Avengers: They had only one chance in 14 million to save the day, and they succeeded. Time is running short, but policymakers’ odds of meeting the Paris targets remain much better than that. There are no physical constraints playing the role of Thanos in our story; only political barriers stand between humanity and a prosperous clean energy future, although those can sometimes be the most difficult types of barriers to overcome.
The new IPCC report is “a code red for humanity”, says UN Secretary-General António Guterres.
Established in 1988 by United Nations Environment Programme (UNEP) and the World Meteorological Organisation (WMO), the Intergovernmental Panel on Climate Change (IPCC) assesses climate change science. Its new report is a warning sign for policy makers all over the world.
In this picture taken on 26 October, 2014, Peia Kararaua, 16, swims in the flooded area of Aberao village in Kiribati. Kiribati is one of the countries worst hit by the sea level rise since high tides mean many villages are inundated, making them uninhabitable. Image credit: UNICEF/Sokhin
This was the first time the approval meeting for the report was conducted online. There were 234 authors from the world over who clocked in 186 hours working together to get this report released.
For the first time, the report offers an interactive atlas for people to see what has already happened and what may happen in the future to where they live.
“This report tells us that recent changes in the climate are widespread, rapid and intensifying, unprecedented in thousands of years,” said IPCC Vice-Chair Ko Barrett.
UNEP Executive Director Inger Andersen that scientists have been issuing these messages for more than three decades, but the world hasn’t listened.
Here are the most important takeaways from the report:
Humans are to be blamed
Human activity is the cause of climate change and this is an unequivocal fact. All the warming caused in the pre-industrial times had been generated by the burning of fossil fuels such as coal, oil, wood, and natural gas.
Global temperatures have already risen by 1.1 degrees Celsius since the 19th century. They have reached their highest in over 100,000 years, and only a fraction of that increase has come from natural forces.
Michael Mann told the Independentthe effects of climate change will be felt in all corners of the world and will worsen, especially since “the IPCC has connected the dots on climate change and the increase in severe extreme weather events… considerably more directly than previous assessments.”
We will overshoot the 1.5 C mark
According to the report’s highly optimistic-to-reckless scenarios, even if we do everything right and start reducing emissions now, we will still overshoot the 1.5C mark by 2030. But, we will see a drop in temperatures to around 1.4 C.
Control emissions, Earth will do the rest
According to the report, if we start working to bring our emissions under control, we will be able to decrease warming, even if we overshoot the 1.5C limit.
The changes we are living through are unprecedented; however, they are reversible to a certain extent. And it will take a lot of time for nature to heal. We can do this by reducing our greenhouse gas (GHG) emissions. While we might see some benefits quickly, “it could take 20-30 years to see global temperatures stabilise” says the IPCC.
Sea level rise
Global oceans have risen about 20 centimetres (eight inches) since 1900, and the rate of increase has nearly tripled in the last decade. Crumbling and melting ice sheets atop Antarctica (especially in Greenland) have replaced glacier melt as the main drivers.
If global warming is capped at 2 C, the ocean watermark will go up about half a metre over the 21st century. It will continue rising to nearly two metres by 2300 — twice the amount predicted by the IPCC in 2019.
Because of uncertainty over ice sheets, scientists cannot rule out a total rise of two metres by 2100 in a worst-case emissions scenario.
CO2 is at all-time high
CO2 levels were greater in 2019 than they had been in “at least two million years.” Methane and nitrous oxide levels, the second and third major contributors of warming respectively, were higher in 2019 than at any point in “at least 800,000 years,” reported the Independent.
Control methane
The report includes more data than ever before on methane (CH4), the second most important greenhouse gas after CO2, and warns that failure to curb emissions could undermine Paris Agreement goals.
Human-induced sources are roughly divided between leaks from natural gas production, coal mining and landfills on one side, and livestock and manure handling on the other.
CH4 lingers in the atmosphere only a fraction as long as CO2, but is far more efficient at trapping heat. CH4 levels are their highest in at least 800,000 years.
Natural allies are weakened
Since about 1960, forests, soil and oceans have absorbed 56 percent of all the CO2 humanity has released into the atmosphere — even as those emissions have increased by half. Without nature’s help, Earth would already be a much hotter and less hospitable place.
But these allies in our fight against global heating — known in this role as carbon sinks — are showing signs of saturatation, and the percentage of human-induced carbon they soak up is likely to decline as the century unfolds.
Suck it out
The report suggests that warming could be brought back down via “negative emissions.” We could cool down the planet by sucking out or sequestering the carbon from the atmosphere. While this is a viable suggestion that has been thrown around and there have been small-scale studies that have tried to do this, the technology is not yet perfect. The panel said that could be done starting about halfway through this century but doesn’t explain how, and many scientists are skeptical about its feasibility.
Cities will bear the brunt
Expertswarn that the impact of some elements of climate change, like heat, floods and sea-level rise in coastal areas, may be exacerbated in cities. Furthermore, IPCC experts warn that low-probability scenarios, like an ice sheet collapse or rapid changes in ocean circulation, cannot be ruled out.






































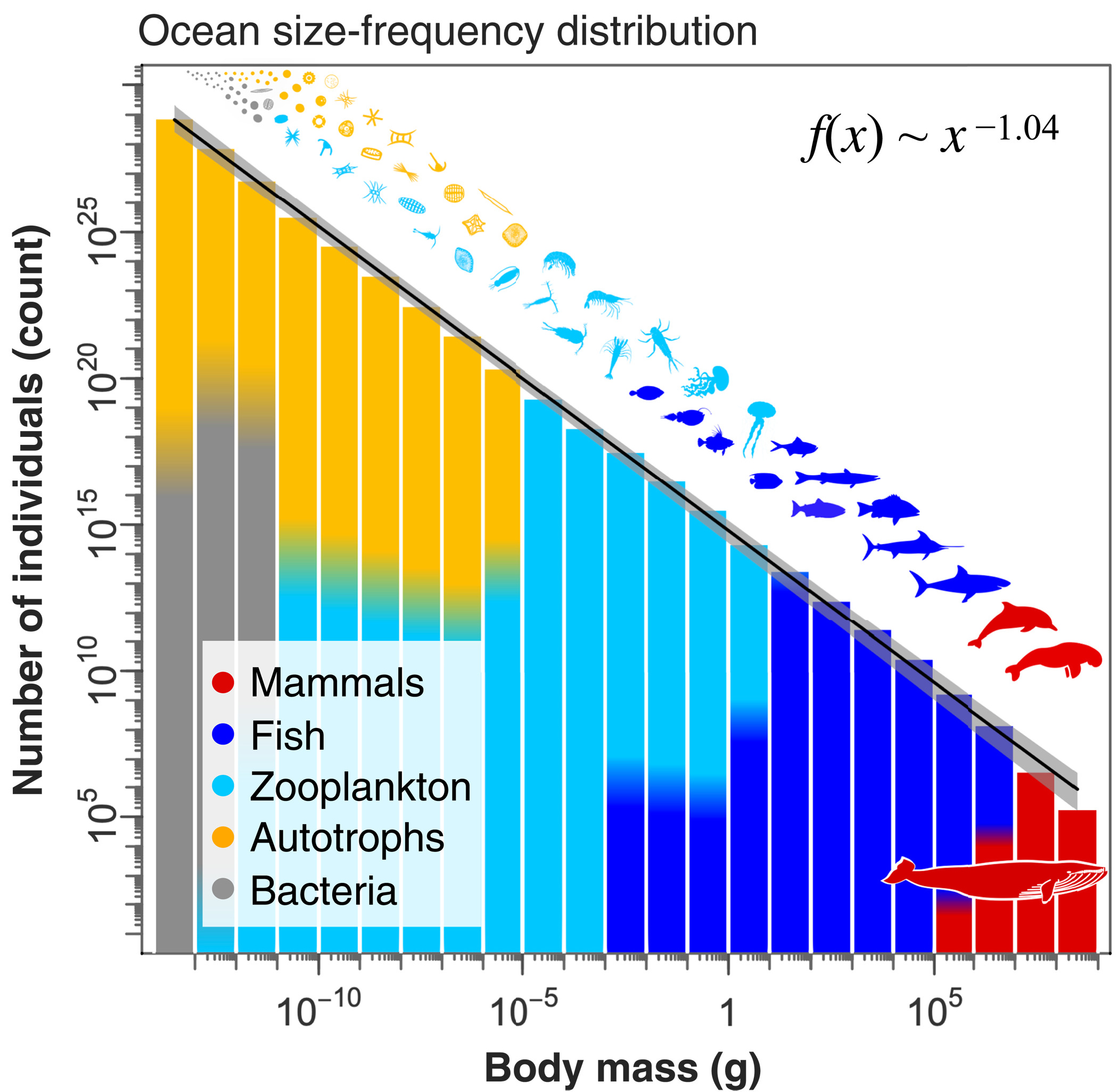 (Ian Hatton et al, Science Advances, 2021)
(Ian Hatton et al, Science Advances, 2021)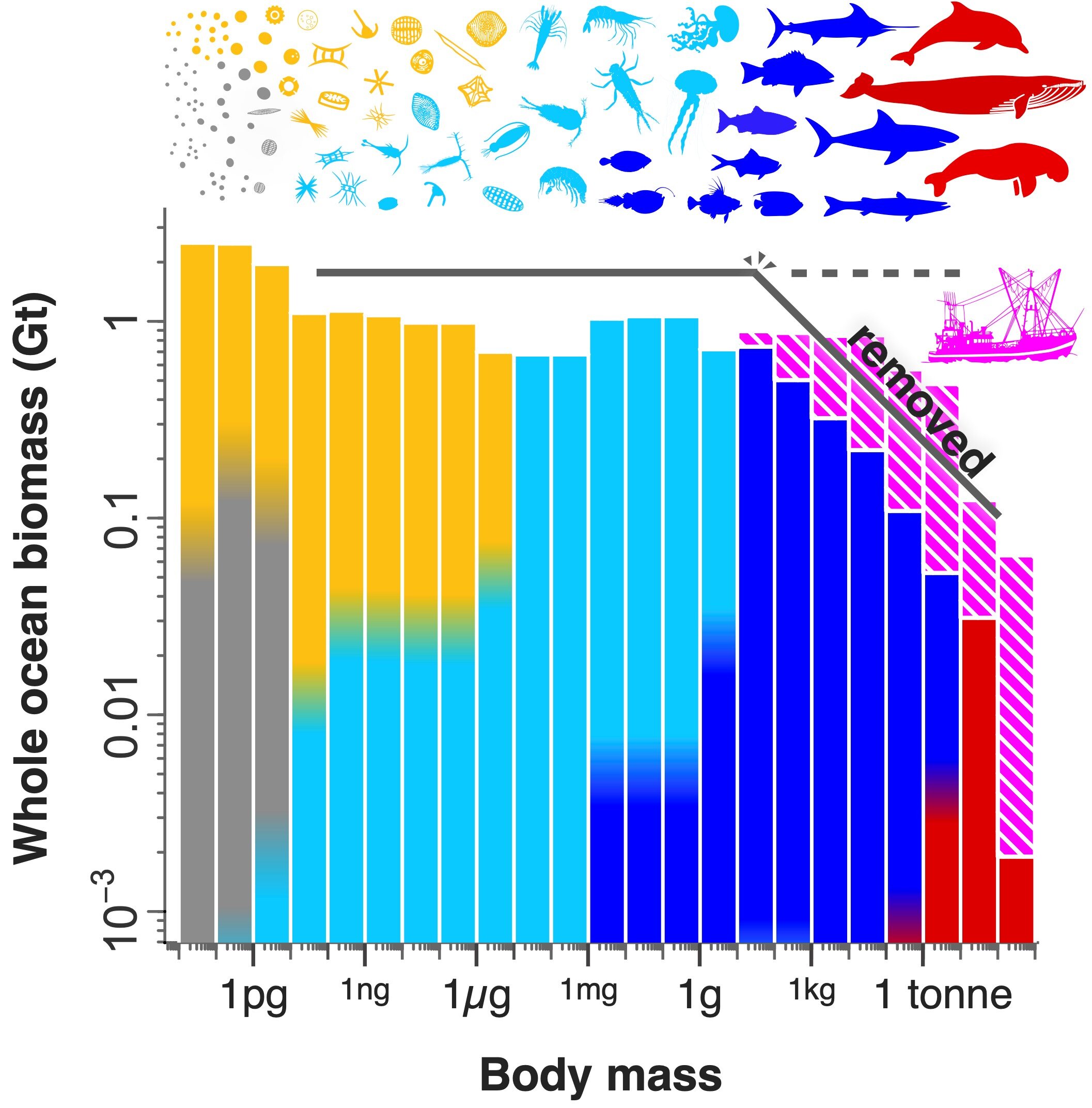 (Ian Hatton et al, Science Advances, 2021)
(Ian Hatton et al, Science Advances, 2021)





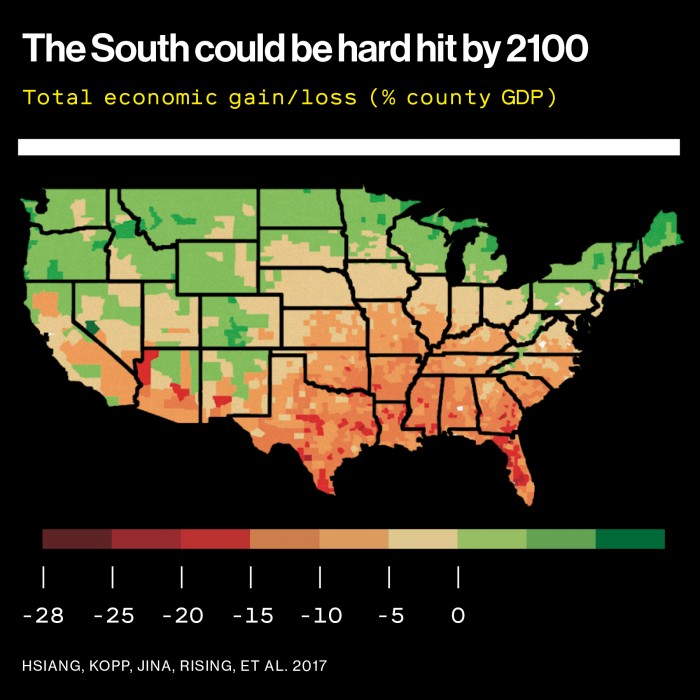
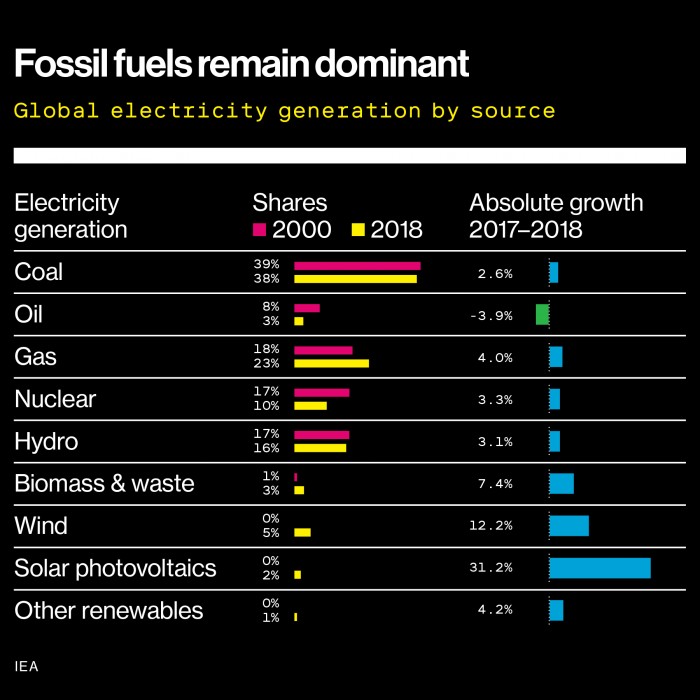










Você precisa fazer login para comentar.