The failure of capitalism to solve our biggest problems is prompting many to question one of its basic precepts.
David Rotman
This story was part of our November 2020 issue
October 14, 2020
No wonder many in the US and Europe have begun questioning the underpinnings of capitalism—particularly its devotion to free markets and its faith in the power of economic growth to create prosperity and solve our problems.
The antipathy to growth is not new; the term “degrowth” was coined in the early 1970s. But these days, worries over climate change, as well as rising inequality, are prompting its reemergence as a movement.
Calls for “the end of growth” are still on the economic fringe, but degrowth arguments have been taken up by political movements as different as the Extinction Rebellion and the populist Five Star Movement in Italy. “And all you can talk about is money and fairy tales of eternal economic growth. How dare you!” thundered Greta Thunberg, the young Swedish climate activist, to an audience of diplomats and politicians at UN Climate Week last year.
At the core of the degrowth movement is a critique of capitalism itself. In Less Is More: How Degrowth Will Save the World, Jason Hickel writes: “Capitalism is fundamentally dependent on growth.” It is, he says, “not growth for any particular purpose, mind you, but growth for its own sake.”
That mindless growth, Hickel and his fellow degrowth believers contend, is very bad both for the planet and for our spiritual well-being. We need, Hickel writes, to develop “new theories of being” and rethink our place in the “living world.” (Hickel goes on about intelligent plants and their ability to communicate, which is both controversial botany and confusing economics.) It’s tempting to dismiss it all as being more about social engineering of our lifestyles than about actual economic reforms.
Though Hickel, an anthropologist, offers a few suggestions (“cut advertising” and “end planned obsolescence”), there’s little about the practical steps that would make a no-growth economy work. Sorry, but talking about plant intelligence won’t solve our woes; it won’t feed hungry people or create well-paying jobs.
Still, the degrowth movement does have a point: faced with climate change and the financial struggles of many workers, capitalism isn’t getting it done.
Slow growth
Even some economists outside the degrowth camp, while not entirely rejecting the importance of growth, are questioning our blind devotion to it.
One obvious factor shaking their faith is that growth has been lousy for decades. There have been exceptions to this economic sluggishness—the US during the late 1990s and early 2000s and developing countries like China as they raced to catch up. But some scholars, notably Robert Gordon, whose 2016 book The Rise and Fall of American Growth triggered much economic soul-searching, are realizing that slow growth might be the new normal, not some blip, for much of the world.
Gordon held that growth “ended on October 16, 1973, or thereabouts,” write MIT economists Esther Duflo and Abhijit Banerjee, who won the 2019 Nobel Prize, in Good Economics for Hard Times. Referencing Gordon, they single out the day when the OPEC oil embargo began; GDP growth in the US and Europe never fully recovered.
The pair are of course being somewhat facetious in tracing the end of growth to a particular day. Their larger point: robust growth seemingly disappeared almost overnight, and no one knows what happened.
Duflo and Banerjee offer possible explanations, only to dismiss them. They write: “The bottom line is that despite the best efforts of generations of economists, the deep mechanisms of persistent economic growth remain elusive.” Nor do we know how to revive it. They conclude: “Given that, we will argue, it may be time to abandon our profession’s obsession with growth.”
In this perspective, growth is not the villain of today’s capitalism, but—at least as measured by GDP—it’s an aspiration that is losing its relevance. Slow growth is nothing to worry about, says Dietrich Vollrath, an economist at the University of Houston, at least not in rich countries. It’s largely the result of lower birth rates—a shrinking workforce means less output—and a shift to services to meet the demands of wealthier consumers. In any case, says Vollrath, with few ways to change it, we might as well embrace slow growth. “It is what it is,” he says.
Vollrath says when his book Fully Grown: Why a Stagnant Economy Is a Sign of Success came out last January, he “was adopted by the degrowthers.” But unlike them, he’s indifferent to whether growth ends or not; rather, he wants to shift the discussion to ways of creating more sustainable technologies and achieving other social goals, whether the changes boost growth or not. “There is now a disconnect between GDP and whether things are getting better,” he says.
Living better
Though the US is the world’s largest economy as measured by GDP, it is doing poorly on indicators such as environmental performance and access to quality education and health care, according to the Social Progress Index, released late this summer by a Washington-based think tank. In the annual ranking (done before the covid pandemic), the US came in 28th, far behind other wealthy countries, including ones with slower GDP growth rates.
“You can churn out all the GDP you want,” says Rebecca Henderson, an economist at Harvard Business School, “but if the suicide rates go up, and the depression rates go up, and the rate of children dying before they’re four goes up, it’s not the kind of society you want to build.” We need to “stop relying totally on GDP,” she says. “It should be just one metric among many.”
Part of the problem, she suggests, is “a failure to imagine that capitalism can be done differently, that it can operate without toasting the planet.”
In her perspective, the US needs to start measuring and valuing growth according to its impact on climate change and access to essential services like health care. “We need self-aware growth,” says Henderson. “Not growth at any cost.”
Daron Acemoglu, another MIT economist, is calling for a “new growth strategy” aimed at creating technologies needed to solve our most pressing problems. Acemoglu describes today’s growth as being driven by large corporations committed to digital technologies, automation, and AI. This concentration of innovation in a few dominant companies has led to inequality and, for many, wage stagnation.
People in Silicon Valley, he says, often acknowledge to him that this is a problem but argue, “It’s what technology wants. It’s the path of technology.” Acemoglu disagrees; we make deliberate choices about which technologies we invent and use, he says.
Acemoglu argues that growth should be directed by market incentives and by regulation. That, he believes, is the best way to make sure we create and deploy technologies that society needs, rather than ones that simply generate massive profits for a few.
Which technologies are those? “I don’t know exactly,” he says. “I’m not clairvoyant. It hasn’t been a priority to develop such technologies, and we’re not aware of the capabilities.”
Turning such a strategy into reality will depend on politics. And the reasoning of academic economists like Acemoglu and Henderson, one fears, is not likely to be popular politically—ignoring as it does the loud calls for the end of growth from the left and the self-confident demands for continued unfettered free markets on the right.
But for those not willing to give up on a future of growth and the vast promise of innovation to improve lives and save the planet, expanding our technological imagination is the only the real choice.
Rewriting capitalism: some must-reads
Reimagining Capitalism in a World on Fire, BY REBECCA HENDERSON The Harvard Business School economist argues that companies can play an important role in improving the world.
Good Economics for Hard Times, BY ABHIJIT V. BANERJEE AND ESTHER DUFLO The MIT economists and 2019 Nobel laureates explain the challenges of boosting growth both in rich countries and in poor ones, where they do much of their research.
Fully Grown: Why a Stagnant Economy Is a Sign of Success, BY DIETRICH VOLLRATH The University of Houston economist argues that slow growth in rich countries like the United States is just fine, but we need to make the benefits from it more inclusive.
Less Is More: How Degrowth Will Save the World, BY JASON HICKEL A leading voice in the degrowth movement provides an overview of the argument for ending growth. It’s a convincing diagnosis of the problems we’re facing; how an end to growth will solve any of them is less clear.
A 1972 MIT study predicted that rapid economic growth would lead to societal collapse in the mid 21st century. A new paper shows we’re unfortunately right on schedule.
A remarkable new study by a director at one of the largest accounting firms in the world has found that a famous, decades-old warning from MIT about the risk of industrial civilization collapsing appears to be accurate based on new empirical data.
As the world looks forward to a rebound in economic growth following the devastation wrought by the pandemic, the research raises urgent questions about the risks of attempting to simply return to the pre-pandemic ‘normal.’
In 1972, a team of MIT scientists got together to study the risks of civilizational collapse. Their system dynamics model published by the Club of Rome identified impending ‘limits to growth’ (LtG) that meant industrial civilization was on track to collapse sometime within the 21st century, due to overexploitation of planetary resources.
The controversial MIT analysis generated heated debate, and was widely derided at the time by pundits who misrepresented its findings and methods. But the analysis has now received stunning vindication from a study written by a senior director at professional services giant KPMG, one of the ‘Big Four’ accounting firms as measured by global revenue.
Limits to growth
The study was published in the Yale Journal of Industrial Ecology in November 2020 and is available on the KPMG website. It concludes that the current business-as-usual trajectory of global civilization is heading toward the terminal decline of economic growth within the coming decade—and at worst, could trigger societal collapse by around 2040.
The study represents the first time a top analyst working within a mainstream global corporate entity has taken the ‘limits to growth’ model seriously. Its author, Gaya Herrington, is Sustainability and Dynamic System Analysis Lead at KPMG in the United States. However, she decided to undertake the research as a personal project to understand how well the MIT model stood the test of time.
The study itself is not affiliated or conducted on behalf of KPMG, and does not necessarily reflect the views of KPMG. Herrington performed the research as an extension of her Masters thesis at Harvard University in her capacity as an advisor to the Club of Rome. However, she is quoted explaining her project on the KPMG website as follows:
“Given the unappealing prospect of collapse, I was curious to see which scenarios were aligning most closely with empirical data today. After all, the book that featured this world model was a bestseller in the 70s, and by now we’d have several decades of empirical data which would make a comparison meaningful. But to my surprise I could not find recent attempts for this. So I decided to do it myself.”
Titled ‘Update to limits to growth: Comparing the World3 model with empirical data’, the study attempts to assess how MIT’s ‘World3’ model stacks up against new empirical data. Previous studies that attempted to do this found that the model’s worst-case scenarios accurately reflected real-world developments. However, the last study of this nature was completed in 2014.
The risk of collapse
Herrington’s new analysis examines data across 10 key variables, namely population, fertility rates, mortality rates, industrial output, food production, services, non-renewable resources, persistent pollution, human welfare, and ecological footprint. She found that the latest data most closely aligns with two particular scenarios, ‘BAU2’ (business-as-usual) and ‘CT’ (comprehensive technology).
“BAU2 and CT scenarios show a halt in growth within a decade or so from now,” the study concludes. “Both scenarios thus indicate that continuing business as usual, that is, pursuing continuous growth, is not possible. Even when paired with unprecedented technological development and adoption, business as usual as modelled by LtG would inevitably lead to declines in industrial capital, agricultural output, and welfare levels within this century.”
Study author Gaya Herrington told Motherboard that in the MIT World3 models, collapse “does not mean that humanity will cease to exist,” but rather that “economic and industrial growth will stop, and then decline, which will hurt food production and standards of living… In terms of timing, the BAU2 scenario shows a steep decline to set in around 2040.”
The ‘Business-as-Usual’ scenario (Source: Herrington, 2021)
The end of growth?
In the comprehensive technology (CT) scenario, economic decline still sets in around this date with a range of possible negative consequences, but this does not lead to societal collapse.
The ‘Comprehensive Technology’ scenario (Source: Herrington, 2021)
Unfortunately, the scenario which was the least closest fit to the latest empirical data happens to be the most optimistic pathway known as ‘SW’ (stabilized world), in which civilization follows a sustainable path and experiences the smallest declines in economic growth—based on a combination of technological innovation and widespread investment in public health and education.
The ‘Stabilized World’ Scenario (Source: Herrington, 2021)
Although both the business-as-usual and comprehensive technology scenarios point to the coming end of economic growth in around 10 years, only the BAU2 scenario “shows a clear collapse pattern, whereas CT suggests the possibility of future declines being relatively soft landings, at least for humanity in general.”
Both scenarios currently “seem to align quite closely not just with observed data,” Herrington concludes in her study, indicating that the future is open.
A window of opportunity
While focusing on the pursuit of continued economic growth for its own sake will be futile, the study finds that technological progress and increased investments in public services could not just avoid the risk of collapse, but lead to a new stable and prosperous civilization operating safely within planetary boundaries. But we really have only the next decade to change course.
“At this point therefore, the data most aligns with the CT and BAU2 scenarios which indicate a slowdown and eventual halt in growth within the next decade or so, but World3 leaves open whether the subsequent decline will constitute a collapse,” the study concludes. Although the ‘stabilized world’ scenario “tracks least closely, a deliberate trajectory change brought about by society turning toward another goal than growth is still possible. The LtG work implies that this window of opportunity is closing fast.”
In a presentation at the World Economic Forum in 2020 delivered in her capacity as a KPMG director, Herrington argued for ‘agrowth’—an agnostic approach to growth which focuses on other economic goals and priorities.
“Changing our societal priorities hardly needs to be a capitulation to grim necessity,” she said. “Human activity can be regenerative and our productive capacities can be transformed. In fact, we are seeing examples of that happening right now. Expanding those efforts now creates a world full of opportunity that is also sustainable.”
She noted how the rapid development and deployment of vaccines at unprecedented rates in response to the COVID-19 pandemic demonstrates that we are capable of responding rapidly and constructively to global challenges if we choose to act. We need exactly such a determined approach to the environmental crisis.
“The necessary changes will not be easy and pose transition challenges but a sustainable and inclusive future is still possible,” said Herrington.
The best available data suggests that what we decide over the next 10 years will determine the long-term fate of human civilization. Although the odds are on a knife-edge, Herrington pointed to a “rapid rise” in environmental, social and good governance priorities as a basis for optimism, signalling the change in thinking taking place in both governments and businesses. She told me that perhaps the most important implication of her research is that it’s not too late to create a truly sustainable civilization that works for all.
Machine-learning systems can be duped or confounded by situations they haven’t seen before. A self-driving car gets flummoxed by a scenario that a human driver could handle easily. An AI system laboriously trained to carry out one task (identifying cats, say) has to be taught all over again to do something else (identifying dogs). In the process, it’s liable to lose some of the expertise it had in the original task. Computer scientists call this problem “catastrophic forgetting.”
These shortcomings have something in common: they exist because AI systems don’t understand causation. They see that some events are associated with other events, but they don’t ascertain which things directly make other things happen. It’s as if you knew that the presence of clouds made rain likelier, but you didn’t know clouds caused rain.
Elias Bareinboim: AI systems are clueless when it comes to causation.
Understanding cause and effect is a big aspect of what we call common sense, and it’s an area in which AI systems today “are clueless,” says Elias Bareinboim. He should know: as the director of the new Causal Artificial Intelligence Lab at Columbia University, he’s at the forefront of efforts to fix this problem.
His idea is to infuse artificial-intelligence research with insights from the relatively new science of causality, a field shaped to a huge extent by Judea Pearl, a Turing Award–winning scholar who considers Bareinboim his protégé.
As Bareinboim and Pearl describe it, AI’s ability to spot correlations—e.g., that clouds make rain more likely—is merely the simplest level of causal reasoning. It’s good enough to have driven the boom in the AI technique known as deep learning over the past decade. Given a great deal of data about familiar situations, this method can lead to very good predictions. A computer can calculate the probability that a patient with certain symptoms has a certain disease, because it has learned just how often thousands or even millions of other people with the same symptoms had that disease.
But there’s a growing consensus that progress in AI will stall if computers don’t get better at wrestling with causation. If machines could grasp that certain things lead to other things, they wouldn’t have to learn everything anew all the time—they could take what they had learned in one domain and apply it to another. And if machines could use common sense we’d be able to put more trust in them to take actions on their own, knowing that they aren’t likely to make dumb errors.
Today’s AI has only a limited ability to infer what will result from a given action. In reinforcement learning, a technique that has allowed machines to master games like chess and Go, a system uses extensive trial and error to discern which moves will essentially cause them to win. But this approach doesn’t work in messier settings in the real world. It doesn’t even leave a machine with a general understanding of how it might play other games.
An even higher level of causal thinking would be the ability to reason about why things happened and ask “what if” questions. A patient dies while in a clinical trial; was it the fault of the experimental medicine or something else? School test scores are falling; what policy changes would most improve them? This kind of reasoning is far beyond the current capability of artificial intelligence.
Performing miracles
The dream of endowing computers with causal reasoning drew Bareinboim from Brazil to the United States in 2008, after he completed a master’s in computer science at the Federal University of Rio de Janeiro. He jumped at an opportunity to study under Judea Pearl, a computer scientist and statistician at UCLA. Pearl, 83, is a giant—the giant—of causal inference, and his career helps illustrate why it’s hard to create AI that understands causality.
Even well-trained scientists are apt to misinterpret correlations as signs of causation—or to err in the opposite direction, hesitating to call out causation even when it’s justified. In the 1950s, for example, a few prominent statisticians muddied the waters around whether tobacco caused cancer. They argued that without an experiment randomly assigning people to be smokers or nonsmokers, no one could rule out the possibility that some unknown—stress, perhaps, or some gene—caused people both to smoke and to get lung cancer.
Eventually, the fact that smoking causes cancer was definitively established, but it needn’t have taken so long. Since then, Pearl and other statisticians have devised a mathematical approach to identifying what facts would be required to support a causal claim. Pearl’s method shows that, given the prevalence of smoking and lung cancer, an independent factor causing both would be extremely unlikely.
Conversely, Pearl’s formulas also help identify when correlations can’t be used to determine causation. Bernhard Schölkopf, who researches causal AI techniques as a director at Germany’s Max Planck Institute for Intelligent Systems, points out that you can predict a country’s birth rate if you know its population of storks. That isn’t because storks deliver babies or because babies attract storks, but probably because economic development leads to more babies and more storks. Pearl has helped give statisticians and computer scientists ways of attacking such problems, Schölkopf says.
Judea Pearl: His theory of causal reasoning has transformed science.
Pearl’s work has also led to the development of causal Bayesian networks—software that sifts through large amounts of data to detect which variables appear to have the most influence on other variables. For example, GNS Healthcare, a company in Cambridge, Massachusetts, uses these techniques to advise researchers about experiments that look promising.
In one project, GNS worked with researchers who study multiple myeloma, a kind of blood cancer. The researchers wanted to know why some patients with the disease live longer than others after getting stem-cell transplants, a common form of treatment. The software churned through data with 30,000 variables and pointed to a few that seemed especially likely to be causal. Biostatisticians and experts in the disease zeroed in on one in particular: the level of a certain protein in patients’ bodies. Researchers could then run a targeted clinical trial to see whether patients with the protein did indeed benefit more from the treatment. “It’s way faster than poking here and there in the lab,” says GNS cofounder Iya Khalil.
Nonetheless, the improvements that Pearl and other scholars have achieved in causal theory haven’t yet made many inroads in deep learning, which identifies correlations without too much worry about causation. Bareinboim is working to take the next step: making computers more useful tools for human causal explorations.
Pearl says AI can’t be truly intelligent until it has a rich understanding of cause and effect, which would enable the introspection that is at the core of cognition.
One of his systems, which is still in beta, can help scientists determine whether they have sufficient data to answer a causal question. Richard McElreath, an anthropologist at the Max Planck Institute for Evolutionary Anthropology, is using the software to guide research into why humans go through menopause (we are the only apes that do).
The hypothesis is that the decline of fertility in older women benefited early human societies because women who put more effort into caring for grandchildren ultimately had more descendants. But what evidence might exist today to support the claim that children do better with grandparents around? Anthropologists can’t just compare the educational or medical outcomes of children who have lived with grandparents and those who haven’t. There are what statisticians call confounding factors: grandmothers might be likelier to live with grandchildren who need the most help. Bareinboim’s software can help McElreath discern which studies about kids who grew up with their grandparents are least riddled with confounding factors and could be valuable in answering his causal query. “It’s a huge step forward,” McElreath says.
The last mile
Bareinboim talks fast and often gestures with two hands in the air, as if he’s trying to balance two sides of a mental equation. It was halfway through the semester when I visited him at Columbia in October, but it seemed as if he had barely moved into his office—hardly anything on the walls, no books on the shelves, only a sleek Mac computer and a whiteboard so dense with equations and diagrams that it looked like a detail from a cartoon about a mad professor.
He shrugged off the provisional state of the room, saying he had been very busy giving talks about both sides of the causal revolution. Bareinboim believes work like his offers the opportunity not just to incorporate causal thinking into machines, but also to improve it in humans.
Getting people to think more carefully about causation isn’t necessarily much easier than teaching it to machines, he says. Researchers in a wide range of disciplines, from molecular biology to public policy, are sometimes content to unearth correlations that are not actually rooted in causal relationships. For instance, some studies suggest drinking alcohol will kill you early, while others indicate that moderate consumption is fine and even beneficial, and still other research has found that heavy drinkers outlive nondrinkers. This phenomenon, known as the “reproducibility crisis,” crops up not only in medicine and nutrition but also in psychology and economics. “You can see the fragility of all these inferences,” says Bareinboim. “We’re flipping results every couple of years.”
He argues that anyone asking “what if”—medical researchers setting up clinical trials, social scientists developing pilot programs, even web publishers preparing A/B tests—should start not merely by gathering data but by using Pearl’s causal logic and software like Bareinboim’s to determine whether the available data could possibly answer a causal hypothesis. Eventually, he envisions this leading to “automated scientist” software: a human could dream up a causal question to go after, and the software would combine causal inference theory with machine-learning techniques to rule out experiments that wouldn’t answer the question. That might save scientists from a huge number of costly dead ends.
Bareinboim described this vision while we were sitting in the lobby of MIT’s Sloan School of Management, after a talk he gave last fall. “We have a building here at MIT with, I don’t know, 200 people,” he said. How do those social scientists, or any scientists anywhere, decide which experiments to pursue and which data points to gather? By following their intuition: “They are trying to see where things will lead, based on their current understanding.”
That’s an inherently limited approach, he said, because human scientists designing an experiment can consider only a handful of variables in their minds at once. A computer, on the other hand, can see the interplay of hundreds or thousands of variables. Encoded with “the basic principles” of Pearl’s causal calculus and able to calculate what might happen with new sets of variables, an automated scientist could suggest exactly which experiments the human researchers should spend their time on. Maybe some public policy that has been shown to work only in Texas could be made to work in California if a few causally relevant factors were better appreciated. Scientists would no longer be “doing experiments in the darkness,” Bareinboim said.
He also doesn’t think it’s that far off: “This is the last mile before the victory.”
What if?
Finishing that mile will probably require techniques that are just beginning to be developed. For example, Yoshua Bengio, a computer scientist at the University of Montreal who shared the 2018 Turing Award for his work on deep learning, is trying to get neural networks—the software at the heart of deep learning—to do “meta-learning” and notice the causes of things.
As things stand now, if you wanted a neural network to detect when people are dancing, you’d show it many, many images of dancers. If you wanted it to identify when people are running, you’d show it many, many images of runners. The system would learn to distinguish runners from dancers by identifying features that tend to be different in the images, such as the positions of a person’s hands and arms. But Bengio points out that fundamental knowledge about the world can be gleaned by analyzing the things that are similar or “invariant” across data sets. Maybe a neural network could learn that movements of the legs physically cause both running and dancing. Maybe after seeing these examples and many others that show people only a few feet off the ground, a machine would eventually understand something about gravity and how it limits human movement. Over time, with enough meta-learning about variables that are consistent across data sets, a computer could gain causal knowledge that would be reusable in many domains.
For his part, Pearl says AI can’t be truly intelligent until it has a rich understanding of cause and effect. Although causal reasoning wouldn’t be sufficient for an artificial general intelligence, it’s necessary, he says, because it would enable the introspection that is at the core of cognition. “What if” questions “are the building blocks of science, of moral attitudes, of free will, of consciousness,” Pearl told me.
You can’t draw Pearl into predicting how long it will take for computers to get powerful causal reasoning abilities. “I am not a futurist,” he says. But in any case, he thinks the first move should be to develop machine-learning tools that combine data with available scientific knowledge: “We have a lot of knowledge that resides in the human skull which is not utilized.”
Brian Bergstein, a former editor at MIT Technology Review, is deputy opinion editor at the Boston Globe.
Our model reveals the true course of the pandemic. Here is what to do next
May 15th 2021 8-10 minutos
THIS WEEK we publish our estimate of the true death toll from covid-19. It tells the real story of the pandemic. But it also contains an urgent warning. Unless vaccine supplies reach poorer countries, the tragic scenes now unfolding in India risk being repeated elsewhere. Millions more will die.
Using known data on 121 variables, from recorded deaths to demography, we have built a pattern of correlations that lets us fill in gaps where numbers are lacking. Our model suggests that covid-19 has already claimed 7.1m-12.7m lives. Our central estimate is that 10m people have died who would otherwise be living. This tally of “excess deaths” is over three times the official count, which nevertheless is the basis for most statistics on the disease, including fatality rates and cross-country comparisons.
The most important insight from our work is that covid-19 has been harder on the poor than anyone knew. Official figures suggest that the pandemic has struck in waves, and that the United States and Europe have been hit hard. Although South America has been ravaged, the rest of the developing world seemed to get off lightly.
Our modelling tells another story. When you count all the bodies, you see that the pandemic has spread remorselessly from the rich, connected world to poorer, more isolated places. As it has done so, the global daily death rate has climbed steeply.
Death rates have been very high in some rich countries, but the overwhelming majority of the 6.7m or so deaths that nobody counted were in poor and middle-income ones. In Romania and Iran excess deaths are more than double the number officially put down to covid-19. In Egypt they are 13 times as big. In America the difference is 7.1%.
India, where about 20,000 are dying every day, is not an outlier. Our figures suggest that, in terms of deaths as a share of population, Peru’s pandemic has been 2.5 times worse than India’s. The disease is working its way through Nepal and Pakistan. Infectious variants spread faster and, because of the tyranny of exponential growth, overwhelm health-care systems and fill mortuaries even if the virus is no more lethal.
Ultimately the way to stop this is vaccination. As an example of collaboration and pioneering science, covid-19 vaccines rank with the Apollo space programme. Within just a year of the virus being discovered, people could be protected from severe disease and death. Hundreds of millions of them have benefited.
However, in the short run vaccines will fuel the divide between rich and poor. Soon, the only people to die from covid-19 in rich countries will be exceptionally frail or exceptionally unlucky, as well as those who have spurned the chance to be vaccinated. In poorer countries, by contrast, most people will have no choice. They will remain unprotected for many months or years.
The world cannot rest while people perish for want of a jab costing as little as $4 for a two-dose course. It is hard to think of a better use of resources than vaccination. Economists’ central estimate for the direct value of a course is $2,900—if you include factors like long covid and the effect of impaired education, the total is much bigger. The benefit from an extra 1bn doses supplied by July would be worth hundreds of billions of dollars. Less circulating virus means less mutation, and so a lower chance of a new variant that reinfects the vaccinated.
Supplies of vaccines are already growing. By the end of April, according to Airfinity, an analytics firm, vaccine-makers produced 1.7bn doses, 700m more than the end of March and ten times more than January. Before the pandemic, annual global vaccine capacity was roughly 3.5bn doses. The latest estimates are that total output in 2021 will be almost 11bn. Some in the industry predict a global surplus in 2022.
And yet the world is right to strive to get more doses in more arms sooner. Hence President Joe Biden has proposed waiving intellectual-property claims on covid-19 vaccines. Many experts argue that, because some manufacturing capacity is going begging, millions more doses might become available if patent-owners shared their secrets, including in countries that today are at the back of the queue. World-trade rules allow for a waiver. When invoke them if not in the throes of a pandemic?
We believe that Mr Biden is wrong. A waiver may signal that his administration cares about the world, but it is at best an empty gesture and at worst a cynical one.
A waiver will do nothing to fill the urgent shortfall of doses in 2021. The head of the World Trade Organisation, the forum where it will be thrashed out, warns there may be no vote until December. Technology transfer would take six months or so to complete even if it started today. With the new mRNA vaccines made by Pfizer and Moderna, it may take longer. Supposing the tech transfer was faster than that, experienced vaccine-makers would be unavailable for hire and makers could not obtain inputs from suppliers whose order books are already bursting. Pfizer’s vaccine requires 280 inputs from suppliers in 19 countries. No firm can recreate that in a hurry.
In any case, vaccine-makers do not appear to be hoarding their technology—otherwise output would not be increasing so fast. They have struck 214 technology-transfer agreements, an unprecedented number. They are not price-gouging: money is not the constraint on vaccination. Poor countries are not being priced out of the market: their vaccines are coming through COVAX, a global distribution scheme funded by donors.
In the longer term, the effect of a waiver is unpredictable. Perhaps it will indeed lead to technology being transferred to poor countries; more likely, though, it will cause harm by disrupting supply chains, wasting resources and, ultimately, deterring innovation. Whatever the case, if vaccines are nearing a surplus in 2022, the cavalry will arrive too late.
A needle in time
If Mr Biden really wants to make a difference, he can donate vaccine right now through COVAX. Rich countries over-ordered because they did not know which vaccines would work. Britain has ordered more than nine doses for each adult, Canada more than 13. These will be urgently needed elsewhere. It is wrong to put teenagers, who have a minuscule risk of dying from covid-19, before the elderly and health-care workers in poor countries. The rich world should not stockpile boosters to cover the population many times over on the off-chance that they may be needed. In the next six months, this could yield billions of doses of vaccine.
Countries can also improve supply chains. The Serum Institute, an Indian vaccine-maker, has struggled to get parts such as filters from America because exports were gummed up by the Defence Production Act (DPA), which puts suppliers on a war-footing. Mr Biden authorised a one-off release, but he should be focusing the DPA on supplying the world instead. And better use needs to be made of finished vaccine. In some poor countries, vaccine languishes unused because of hesitancy and chaotic organisation. It makes sense to prioritise getting one shot into every vulnerable arm, before setting about the second.
Our model is not predictive. However it does suggest that some parts of the world are particularly vulnerable—one example is South-East Asia, home to over 650m people, which has so far been spared mass fatalities for no obvious reason. Covid-19 has not yet run its course. But vaccines have created the chance to save millions of lives. The world must not squander it. ■
Could the way drosophila use antennae to sense heat help us teach self-driving cars make decisions?
Date: April 6, 2021
Source: Northwestern University
Summary: With over 70% of respondents to a AAA annual survey on autonomous driving reporting they would fear being in a fully self-driving car, makers like Tesla may be back to the drawing board before rolling out fully autonomous self-driving systems. But new research shows us we may be better off putting fruit flies behind the wheel instead of robots.
With over 70% of respondents to a AAA annual survey on autonomous driving reporting they would fear being in a fully self-driving car, makers like Tesla may be back to the drawing board before rolling out fully autonomous self-driving systems. But new research from Northwestern University shows us we may be better off putting fruit flies behind the wheel instead of robots.
Drosophila have been subjects of science as long as humans have been running experiments in labs. But given their size, it’s easy to wonder what can be learned by observing them. Research published today in the journal Nature Communications demonstrates that fruit flies use decision-making, learning and memory to perform simple functions like escaping heat. And researchers are using this understanding to challenge the way we think about self-driving cars.
“The discovery that flexible decision-making, learning and memory are used by flies during such a simple navigational task is both novel and surprising,” said Marco Gallio, the corresponding author on the study. “It may make us rethink what we need to do to program safe and flexible self-driving vehicles.”
According to Gallio, an associate professor of neurobiology in the Weinberg College of Arts and Sciences, the questions behind this study are similar to those vexing engineers building cars that move on their own. How does a fruit fly (or a car) cope with novelty? How can we build a car that is flexibly able to adapt to new conditions?
This discovery reveals brain functions in the household pest that are typically associated with more complex brains like those of mice and humans.
“Animal behavior, especially that of insects, is often considered largely fixed and hard-wired — like machines,” Gallio said. “Most people have a hard time imagining that animals as different from us as a fruit fly may possess complex brain functions, such as the ability to learn, remember or make decisions.”
To study how fruit flies tend to escape heat, the Gallio lab built a tiny plastic chamber with four floor tiles whose temperatures could be independently controlled and confined flies inside. They then used high-resolution video recordings to map how a fly reacted when it encountered a boundary between a warm tile and a cool tile. They found flies were remarkably good at treating heat boundaries as invisible barriers to avoid pain or harm.
Using real measurements, the team created a 3D model to estimate the exact temperature of each part of the fly’s tiny body throughout the experiment. During other trials, they opened a window in the fly’s head and recorded brain activity in neurons that process external temperature signals.
Miguel Simões, a postdoctoral fellow in the Gallio lab and co-first author of the study, said flies are able to determine with remarkable accuracy if the best path to thermal safety is to the left or right. Mapping the direction of escape, Simões said flies “nearly always” escape left when they approach from the right, “like a tennis ball bouncing off a wall.”
“When flies encounter heat, they have to make a rapid decision,” Simões said. “Is it safe to continue, or should it turn back? This decision is highly dependent on how dangerous the temperature is on the other side.”
Observing the simple response reminded the scientists of one of the classic concepts in early robotics.
“In his famous book, the cyberneticist Valentino Braitenberg imagined simple models made of sensors and motors that could come close to reproducing animal behavior,” said Josh Levy, an applied math graduate student and a member of the labs of Gallio and applied math professor William Kath. “The vehicles are a combination of simple wires, but the resulting behavior appears complex and even intelligent.”
Braitenberg argued that much of animal behavior could be explained by the same principles. But does that mean fly behavior is as predictable as that of one of Braitenberg’s imagined robots?
The Northwestern team built a vehicle using a computer simulation of fly behavior with the same wiring and algorithm as a Braitenberg vehicle to see how closely they could replicate animal behavior. After running model race simulations, the team ran a natural selection process of sorts, choosing the cars that did best and mutating them slightly before recombining them with other high-performing vehicles. Levy ran 500 generations of evolution in the powerful NU computing cluster, building cars they ultimately hoped would do as well as flies at escaping the virtual heat.
This simulation demonstrated that “hard-wired” vehicles eventually evolved to perform nearly as well as flies. But while real flies continued to improve performance over time and learn to adopt better strategies to become more efficient, the vehicles remain “dumb” and inflexible. The researchers also discovered that even as flies performed the simple task of escaping the heat, fly behavior remains somewhat unpredictable, leaving space for individual decisions. Finally, the scientists observed that while flies missing an antenna adapt and figure out new strategies to escape heat, vehicles “damaged” in the same way are unable to cope with the new situation and turn in the direction of the missing part, eventually getting trapped in a spin like a dog chasing its tail.
Gallio said the idea that simple navigation contains such complexity provides fodder for future work in this area.
Work in the Gallio lab is supported by the NIH (Award No. R01NS086859 and R21EY031849), a Pew Scholars Program in the Biomedical Sciences and a McKnight Technological Innovation in Neuroscience Awards.
Story Source:
Materials provided by Northwestern University. Original written by Lila Reynolds. Note: Content may be edited for style and length.
Journal Reference:
José Miguel Simões, Joshua I. Levy, Emanuela E. Zaharieva, Leah T. Vinson, Peixiong Zhao, Michael H. Alpert, William L. Kath, Alessia Para, Marco Gallio. Robustness and plasticity in Drosophila heat avoidance. Nature Communications, 2021; 12 (1) DOI: 10.1038/s41467-021-22322-w
Em seu novo livro Como evitar um desastre climático, Bill Gates adota uma abordagem tecnológica para compreender a crise climática. Gates começa com os 51 bilhões de toneladas de gases com efeito de estufa criados por ano. Ele divide essa poluição em setores com base em seu impacto, passando pelo elétrico, industrial e agrícola para o de transporte e construção civil. Do começo ao fim, Gates se mostra adepto a diminuir as complexidades do desafio climático, dando ao leitor heurísticas úteis para distinguir maiores problemas tecnológicos (cimento) de menores (aeronaves).
Presente nas negociações climáticas de Paris em 2015, Gates e dezenas de indivíduos bem-afortunados lançaram o Breakthrough Energy, um fundo de capital de investimento interdependente lobista empenhado em conduzir pesquisas. Gates e seus companheiros investidores argumentaram que tanto o governo federal quanto o setor privado estão investindo pouco em inovação energética. A Breakthrough pretende preencher esta lacuna, investindo em tudo, desde tecnologia nuclear da próxima geração até carne vegetariana com sabor de carne bovina. A primeira rodada de US$ 1 bilhão do fundo de investimento teve alguns sucessos iniciais, como a Impossible Foods, uma fabricante de hambúrgueres à base de plantas. O fundo anunciou uma segunda rodada de igual tamanho em janeiro.
Um esforço paralelo, um acordo internacional chamado de Mission Innovation, diz ter convencido seus membros (o setor executivo da União Europeia junto com 24 países incluindo China, os EUA, Índia e o Brasil) a investirem um adicional de US$ 4,6 bilhões por ano desde 2015 para a pesquisa e desenvolvimento da energia limpa.
Essas várias iniciativas são a linha central para o livro mais recente de Gates, escrito a partir de uma perspectiva tecno-otimista. “Tudo que aprendi a respeito do clima e tecnologia me deixam otimista… se agirmos rápido o bastante, [podemos] evitar uma catástrofe climática,” ele escreveu nas páginas iniciais.
Como muitos já assinalaram, muito da tecnologia necessária já existe, muito pode ser feito agora. Por mais que Gates não conteste isso, seu livro foca nos desafios tecnológicos que ele acredita que ainda devem ser superados para atingir uma maior descarbonização. Ele gasta menos tempo nos percalços políticos, escrevendo que pensa “mais como um engenheiro do que um cientista político.” Ainda assim, a política, com toda a sua desordem, é o principal impedimento para o progresso das mudanças climáticas. E engenheiros devem entender como sistemas complexos podem ter ciclos de feedback que dão errado.
Sim, ministro
Kim Stanley Robinson, este sim pensa como um cientista político. O começo de seu romance mais recente The Ministry for the Future (ainda sem tradução para o português), se passa apenas a alguns anos no futuro, em 2025, quando uma onda de calor imensa atinge a Índia, matando milhões de pessoas. A protagonista do livro, Mary Murphy, comanda uma agência da ONU designada a representar os interesses das futuras gerações em uma tentativa de unir os governos mundiais em prol de uma solução climática. Durante todo o livro a equidade intergeracional e várias formas de políticas distributivas em foco.
Se você já viu os cenários que o Painel Intergovernamental sobre Mudanças Climáticas (IPCC) desenvolve para o futuro, o livro de Robinson irá parecer familiar. Sua história questiona as políticas necessárias para solucionar a crise climática, e ele certamente fez seu dever de casa. Apesar de ser um exercício de imaginação, há momentos em que o romance se assemelha mais a um seminário de graduação sobre ciências sociais do que a um trabalho de ficção escapista. Os refugiados climáticos, que são centrais para a história, ilustram a forma como as consequências da poluição atingem a população global mais pobre com mais força. Mas os ricos produzem muito mais carbono.
Ler Gates depois de Robinson evidencia a inextricável conexão entre desigualdade e mudanças climáticas. Os esforços de Gates sobre a questão do clima são louváveis. Mas quando ele nos diz que a riqueza combinada das pessoas apoiando seu fundo de investimento é de US$ 170 bilhões, ficamos um pouco intrigados que estes tenham dedicado somente US$ 2 bilhões para soluções climáticas, menos de 2% de seus ativos. Este fato por si só é um argumento favorável para taxar fortunas: a crise climática exige ação governamental. Não pode ser deixado para o capricho de bilionários.
Quanto aos bilionários, Gates é possivelmente um dos bonzinhos. Ele conta histórias sobre como usa sua fortuna para ajudar os pobres e o planeta. A ironia dele escrever um livro sobre mudanças climáticas quando voa em um jato particular e detém uma mansão de 6.132 m² não é algo que passa despercebido pelo leitor, e nem por Gates, que se autointitula um “mensageiro imperfeito sobre mudanças climáticas”. Ainda assim, ele é inquestionavelmente um aliado do movimento climático.
Mas ao focar em inovações tecnológicas, Gates minimiza a participação dos combustíveis fósseis na obstrução deste progresso. Peculiarmente, o ceticismo climático não é mencionado no livro. Lavando as mãos no que diz respeito à polarização política, Gates nunca faz conexão com seus colegas bilionários Charles e David Koch, que enriqueceram com os petroquímicos e têm desempenhado papel de destaque na reprodução do negacionismo climático.
Por exemplo, Gates se admira que para a vasta maioria dos americanos aquecedores elétricos são na verdade mais baratos do que continuar a usar combustíveis fósseis. Para ele, as pessoas não adotarem estas opções mais econômicas e sustentáveis é um enigma. Mas, não é assim. Como os jornalistas Rebecca Leber e Sammy Roth reportaram em Mother Jones e no Los Angeles Times, a indústria do gás está investindo em defensores e criando campanhas de marketing para se opor à eletrificação e manter as pessoas presas aos combustíveis fósseis.
Essas forças de oposição são melhor vistas no livro do Robinson do que no de Gates. Gates teria se beneficiado se tivesse tirado partido do trabalho que Naomi Oreskes, Eric Conway, Geoffrey Supran, entre outros, têm feito para documentar os esforços persistentes das empresas de combustíveis fósseis em semear dúvida sobre a ciência climática para a população.
No entanto, uma coisa que Gates e Robinson têm em comum é a opinião de que a geoengenharia, intervenções monumentais para combater os sintomas ao invés das causas das mudanças climáticas, venha a ser inevitável. Em The Ministry for the Future, a geoengenharia solar, que vem a ser a pulverização de partículas finas na atmosfera para refletir mais do calor solar de volta para o espaço, é usada na sequência dos acontecimentos da onda de calor mortal que inicia a história. E mais tarde, alguns cientistas vão aos polos e inventam elaborados métodos para remover água derretida de debaixo de geleiras para evitar que avançasse para o mar. Apesar de alguns contratempos, eles impedem a subida do nível do mar em vários metros. É possível imaginar Gates aparecendo no romance como um dos primeiros a financiar estes esforços. Como ele próprio observa em seu livro, ele tem investido em pesquisa sobre geoengenharia solar há anos.
A pior parte
O título do novo livro de Elizabeth Kolbert, Under a White Sky (ainda sem tradução para o português), é uma referência a esta tecnologia nascente, já que implementá-la em larga escala pode alterar a cor do céu de azul para branco. Kolbert observa que o primeiro relatório sobre mudanças climáticas foi parar na mesa do presidente Lyndon Johnson em 1965. Este relatório não argumentava que deveríamos diminuir as emissões de carbono nos afastando de combustíveis fósseis. No lugar, defendia mudar o clima por meio da geoengenharia solar, apesar do termo ainda não ter sido inventado. É preocupante que alguns se precipitem imediatamente para essas soluções arriscadas em vez de tratar a raiz das causas das mudanças climáticas.
Ao ler Under a White Sky, somos lembrados das formas com que intervenções como esta podem dar errado. Por exemplo, a cientista e escritora Rachel Carson defendeu importar espécies não nativas como uma alternativa a utilizar pesticidas. No ano após o seu livro Primavera Silenciosa ser publicado, em 1962, o US Fish and Wildlife Service trouxe carpas asiáticas para a América pela primeira vez, a fim de controlar algas aquáticas. Esta abordagem solucionou um problema, mas criou outro: a disseminação dessa espécie invasora ameaçou às locais e causou dano ambiental.
Como Kolbert observa, seu livro é sobre “pessoas tentando solucionar problemas criados por pessoas tentando solucionar problemas.” Seu relato cobre exemplos incluindo esforços malfadados de parar a disseminação das carpas, as estações de bombeamento em Nova Orleans que aceleram o afundamento da cidade e as tentativas de seletivamente reproduzir corais que possam tolerar temperaturas mais altas e a acidificação do oceano. Kolbert tem senso de humor e uma percepção aguçada para consequências não intencionais. Se você gosta do seu apocalipse com um pouco de humor, ela irá te fazer rir enquanto Roma pega fogo.
Em contraste, apesar de Gates estar consciente das possíveis armadilhas das soluções tecnológicas, ele ainda enaltece invenções como plástico e fertilizante como vitais. Diga isso para as tartarugas marinhas engolindo lixo plástico ou as florações de algas impulsionadas por fertilizantes destruindo o ecossistema do Golfo do México.
Com níveis perigosos de dióxido de carbono na atmosfera, a geoengenharia pode de fato se provar necessária, mas não deveríamos ser ingênuos sobre os riscos. O livro de Gates tem muitas ideias boas e vale a pena a leitura. Mas para um panorama completo da crise que enfrentamos, certifique-se de também ler Robinson e Kolbert.
O florescer das famosas cerejeiras brancas e rosas leva milhares às ruas e parques do Japão para observar o fenômeno, que dura poucos dias e é reverenciado há mais de mil anos. Mas este ano a antecipação da florada tem preocupado cientistas, pois indica impacto nas mudanças climáticas.
Segundo registros da Universidade da Prefeitura de Osaka, em 2021, as famosas cerejeiras brancas e rosas floresceram totalmente em 26 de março em Quioto, a data mais antecipada em 12 séculos. As floradas mais cedo foram registradas em 27 de março dos anos 1612, 1409 e 1236.
A instituição conseguiu identificar a antecipação do fenômeno porque tem um banco de dados completo dos registros das floradas ao longo dos séculos. Os registros começaram no ano 812 e incluem documentos judiciais da Quioto Imperial, a antiga capital do Japão e diários medievais.
O professor de ciência ambiental da universidade da Prefeitura de Osaka, Yasuyuki Aono, responsável por compilar um banco de dados, disse à Agência Reuters que o fenômeno costuma ocorrer em abril, mas à medida que as temperaturas sobem, o início da floração é mais cedo.
Kazuhiro Nogui, 24.mar.2021/AFP
“As flores de cerejeira são muito sensíveis à temperatura. A floração e a plena floração podem ocorrer mais cedo ou mais tarde, dependendo apenas da temperatura. A temperatura era baixa na década de 1820, mas subiu cerca de 3,5 graus Celsius até hoje”, disse.
Segundo ele, as estações deste ano, em particular, influenciaram as datas de floração. O inverno foi muito frio, mas a primavera veio rápida e excepcionalmente quente, então “os botões estão completamente despertos depois de um descanso suficiente”.
Na capital Tóquio, as cerejeiras atingiram o máximo da florada em 22 de março, o segundo ano mais cedo já registrado. “À medida que as temperaturas globais aumentam, as geadas da última Primavera estão ocorrendo mais cedo e a floração está ocorrendo mais cedo”, afirmou Lewis Ziska, da Universidade de Columbia, à CNN.
A Agência Meteorológica do Japão acompanha ainda 58 cerejeiras “referência” no país. Neste ano, 40 já atingiram o pico de floração e 14 o fizeram em tempo recorde. As árvores normalmente florescem por cerca de duas semanas todos os anos. “Podemos dizer que é mais provável por causa do impacto do aquecimento global”, disse Shunji Anbe, funcionário da divisão de observações da agência.
Dados Organização Meteorológica Mundial divulgados em janeiro mostram que as temperaturas globais em 2020 estiveram entre as mais altas já registradas e rivalizaram com 2016 com o ano mais quente de todos os tempos.
As flores de cerejeira têm longas raízes históricas e culturais no Japão, anunciando a Primavera e inspirando artistas e poetas ao longo dos séculos. Sua fragilidade é vista como um símbolo de vida, morte e renascimento.
Atualmente, as pessoas se reúnem sob as flores de cerejeiras a cada primavera para festas hanami (observação das flores), passeiam em parques e fazem piqueniques embaixo dos galhos e abusar das selfies. Mas, neste ano, a florada de cerejeiras veio e se foi em um piscar de olhos.
Com o fim do estado de emergência para conter a pandemia de Covid-19 em todas as regiões do Japão, muitas pessoas se aglomeraram em locais populares de exibição no fim de semana, embora o número de pessoas tenha sido menor do que em anos normais.
Joaquin Quiñonero Candela, a director of AI at Facebook, was apologizing to his audience.
It was March 23, 2018, just days after the revelation that Cambridge Analytica, a consultancy that worked on Donald Trump’s 2016 presidential election campaign, had surreptitiously siphoned the personal data of tens of millions of Americans from their Facebook accounts in an attempt to influence how they voted. It was the biggest privacy breach in Facebook’s history, and Quiñonero had been previously scheduled to speak at a conference on, among other things, “the intersection of AI, ethics, and privacy” at the company. He considered canceling, but after debating it with his communications director, he’d kept his allotted time.
As he stepped up to face the room, he began with an admission. “I’ve just had the hardest five days in my tenure at Facebook,” he remembers saying. “If there’s criticism, I’ll accept it.”
The Cambridge Analytica scandal would kick off Facebook’s largest publicity crisis ever. It compounded fears that the algorithms that determine what people see on the platform were amplifying fake news and hate speech, and that Russian hackers had weaponized them to try to sway the election in Trump’s favor. Millions began deleting the app; employees left in protest; the company’s market capitalization plunged by more than $100 billion after its July earnings call.
In the ensuing months, Mark Zuckerberg began his own apologizing. He apologized for not taking “a broad enough view” of Facebook’s responsibilities, and for his mistakes as a CEO. Internally, Sheryl Sandberg, the chief operating officer, kicked off a two-year civil rights audit to recommend ways the company could prevent the use of its platform to undermine democracy.
Finally, Mike Schroepfer, Facebook’s chief technology officer, asked Quiñonero to start a team with a directive that was a little vague: to examine the societal impact of the company’s algorithms. The group named itself the Society and AI Lab (SAIL); last year it combined with another team working on issues of data privacy to form Responsible AI.
Quiñonero was a natural pick for the job. He, as much as anybody, was the one responsible for Facebook’s position as an AI powerhouse. In his six years at Facebook, he’d created some of the first algorithms for targeting users with content precisely tailored to their interests, and then he’d diffused those algorithms across the company. Now his mandate would be to make them less harmful.
Facebook has consistently pointed to the efforts by Quiñonero and others as it seeks to repair its reputation. It regularly trots out various leaders to speak to the media about the ongoing reforms. In May of 2019, it granted a series of interviews with Schroepfer to the New York Times, which rewarded the company with a humanizing profile of a sensitive, well-intentioned executive striving to overcome the technical challenges of filtering out misinformation and hate speech from a stream of content that amounted to billions of pieces a day. These challenges are so hard that it makes Schroepfer emotional, wrote the Times: “Sometimes that brings him to tears.”
In the spring of 2020, it was apparently my turn. Ari Entin, Facebook’s AI communications director, asked in an email if I wanted to take a deeper look at the company’s AI work. After talking to several of its AI leaders, I decided to focus on Quiñonero. Entin happily obliged. As not only the leader of the Responsible AI team but also the man who had made Facebook into an AI-driven company, Quiñonero was a solid choice to use as a poster boy.
He seemed a natural choice of subject to me, too. In the years since he’d formed his team following the Cambridge Analytica scandal, concerns about the spread of lies and hate speech on Facebook had only grown. In late 2018 the company admitted that this activity had helped fuel a genocidal anti-Muslim campaign in Myanmar for several years. In 2020 Facebook started belatedly taking action against Holocaust deniers, anti-vaxxers, and the conspiracy movement QAnon. All these dangerous falsehoods were metastasizing thanks to the AI capabilities Quiñonero had helped build. The algorithms that underpin Facebook’s business weren’t created to filter out what was false or inflammatory; they were designed to make people share and engage with as much content as possible by showing them things they were most likely to be outraged or titillated by. Fixing this problem, to me, seemed like core Responsible AI territory.
I began video-calling Quiñonero regularly. I also spoke to Facebook executives, current and former employees, industry peers, and external experts. Many spoke on condition of anonymity because they’d signed nondisclosure agreements or feared retaliation. I wanted to know: What was Quiñonero’s team doing to rein in the hate and lies on its platform?
Joaquin Quiñonero Candela outside his home in the Bay Area, where he lives with his wife and three kids.
But Entin and Quiñonero had a different agenda. Each time I tried to bring up these topics, my requests to speak about them were dropped or redirected. They only wanted to discuss the Responsible AI team’s plan to tackle one specific kind of problem: AI bias, in which algorithms discriminate against particular user groups. An example would be an ad-targeting algorithm that shows certain job or housing opportunities to white people but not to minorities.
By the time thousands of rioters stormed the US Capitol in January, organized in part on Facebook and fueled by the lies about a stolen election that had fanned out across the platform, it was clear from my conversations that the Responsible AI team had failed to make headway against misinformation and hate speech because it had never made those problems its main focus. More important, I realized, if it tried to, it would be set up for failure.
The reason is simple. Everything the company does and chooses not to do flows from a single motivation: Zuckerberg’s relentless desire for growth. Quiñonero’s AI expertise supercharged that growth. His team got pigeonholed into targeting AI bias, as I learned in my reporting, because preventing such bias helps the company avoid proposed regulation that might, if passed, hamper that growth. Facebook leadership has also repeatedly weakened or halted many initiatives meant to clean up misinformation on the platform because doing so would undermine that growth.
In other words, the Responsible AI team’s work—whatever its merits on the specific problem of tackling AI bias—is essentially irrelevant to fixing the bigger problems of misinformation, extremism, and political polarization. And it’s all of us who pay the price.
“When you’re in the business of maximizing engagement, you’re not interested in truth. You’re not interested in harm, divisiveness, conspiracy. In fact, those are your friends,” says Hany Farid, a professor at the University of California, Berkeley who collaborates with Facebook to understand image- and video-based misinformation on the platform.
“They always do just enough to be able to put the press release out. But with a few exceptions, I don’t think it’s actually translated into better policies. They’re never really dealing with the fundamental problems.”
In March of 2012, Quiñonero visited a friend in the Bay Area. At the time, he was a manager in Microsoft Research’s UK office, leading a team using machine learning to get more visitors to click on ads displayed by the company’s search engine, Bing. His expertise was rare, and the team was less than a year old. Machine learning, a subset of AI, had yet to prove itself as a solution to large-scale industry problems. Few tech giants had invested in the technology.
Quiñonero’s friend wanted to show off his new employer, one of the hottest startups in Silicon Valley: Facebook, then eight years old and already with close to a billion monthly active users (i.e., those who have logged in at least once in the past 30 days). As Quiñonero walked around its Menlo Park headquarters, he watched a lone engineer make a major update to the website, something that would have involved significant red tape at Microsoft. It was a memorable introduction to Zuckerberg’s “Move fast and break things” ethos. Quiñonero was awestruck by the possibilities. Within a week, he had been through interviews and signed an offer to join the company.
His arrival couldn’t have been better timed. Facebook’s ads service was in the middle of a rapid expansion as the company was preparing for its May IPO. The goal was to increase revenue and take on Google, which had the lion’s share of the online advertising market. Machine learning, which could predict which ads would resonate best with which users and thus make them more effective, could be the perfect tool. Shortly after starting, Quiñonero was promoted to managing a team similar to the one he’d led at Microsoft.
Quiñonero started raising chickens in late 2019 as a way to unwind from the intensity of his job.
Unlike traditional algorithms, which are hard-coded by engineers, machine-learning algorithms “train” on input data to learn the correlations within it. The trained algorithm, known as a machine-learning model, can then automate future decisions. An algorithm trained on ad click data, for example, might learn that women click on ads for yoga leggings more often than men. The resultant model will then serve more of those ads to women. Today at an AI-based company like Facebook, engineers generate countless models with slight variations to see which one performs best on a given problem.
Facebook’s massive amounts of user data gave Quiñonero a big advantage. His team could develop models that learned to infer the existence not only of broad categories like “women” and “men,” but of very fine-grained categories like “women between 25 and 34 who liked Facebook pages related to yoga,” and targeted ads to them. The finer-grained the targeting, the better the chance of a click, which would give advertisers more bang for their buck.
Within a year his team had developed these models, as well as the tools for designing and deploying new ones faster. Before, it had taken Quiñonero’s engineers six to eight weeks to build, train, and test a new model. Now it took only one.
News of the success spread quickly. The team that worked on determining which posts individual Facebook users would see on their personal news feeds wanted to apply the same techniques. Just as algorithms could be trained to predict who would click what ad, they could also be trained to predict who would like or share what post, and then give those posts more prominence. If the model determined that a person really liked dogs, for instance, friends’ posts about dogs would appear higher up on that user’s news feed.
Quiñonero’s success with the news feed—coupled with impressive new AI research being conducted outside the company—caught the attention of Zuckerberg and Schroepfer. Facebook now had just over 1 billion users, making it more than eight times larger than any other social network, but they wanted to know how to continue that growth. The executives decided to invest heavily in AI, internet connectivity, and virtual reality.
They created two AI teams. One was FAIR, a fundamental research lab that would advance the technology’s state-of-the-art capabilities. The other, Applied Machine Learning (AML), would integrate those capabilities into Facebook’s products and services. In December 2013, after months of courting and persuasion, the executives recruited Yann LeCun, one of the biggest names in the field, to lead FAIR. Three months later, Quiñonero was promoted again, this time to lead AML. (It was later renamed FAIAR, pronounced “fire.”)
“That’s how you know what’s on his mind. I was always, for a couple of years, a few steps from Mark’s desk.”
Joaquin Quiñonero Candela
In his new role, Quiñonero built a new model-development platform for anyone at Facebook to access. Called FBLearner Flow, it allowed engineers with little AI experience to train and deploy machine-learning models within days. By mid-2016, it was in use by more than a quarter of Facebook’s engineering team and had already been used to train over a million models, including models for image recognition, ad targeting, and content moderation.
Zuckerberg’s obsession with getting the whole world to use Facebook had found a powerful new weapon. Teams had previously used design tactics, like experimenting with the content and frequency of notifications, to try to hook users more effectively. Their goal, among other things, was to increase a metric called L6/7, the fraction of people who logged in to Facebook six of the previous seven days. L6/7 is just one of myriad ways in which Facebook has measured “engagement”—the propensity of people to use its platform in any way, whether it’s by posting things, commenting on them, liking or sharing them, or just looking at them. Now every user interaction once analyzed by engineers was being analyzed by algorithms. Those algorithms were creating much faster, more personalized feedback loops for tweaking and tailoring each user’s news feed to keep nudging up engagement numbers.
Zuckerberg, who sat in the center of Building 20, the main office at the Menlo Park headquarters, placed the new FAIR and AML teams beside him. Many of the original AI hires were so close that his desk and theirs were practically touching. It was “the inner sanctum,” says a former leader in the AI org (the branch of Facebook that contains all its AI teams), who recalls the CEO shuffling people in and out of his vicinity as they gained or lost his favor. “That’s how you know what’s on his mind,” says Quiñonero. “I was always, for a couple of years, a few steps from Mark’s desk.”
With new machine-learning models coming online daily, the company created a new system to track their impact and maximize user engagement. The process is still the same today. Teams train up a new machine-learning model on FBLearner, whether to change the ranking order of posts or to better catch content that violates Facebook’s community standards (its rules on what is and isn’t allowed on the platform). Then they test the new model on a small subset of Facebook’s users to measure how it changes engagement metrics, such as the number of likes, comments, and shares, says Krishna Gade, who served as the engineering manager for news feed from 2016 to 2018.
If a model reduces engagement too much, it’s discarded. Otherwise, it’s deployed and continually monitored. On Twitter, Gade explained that his engineers would get notifications every few days when metrics such as likes or comments were down. Then they’d decipher what had caused the problem and whether any models needed retraining.
But this approach soon caused issues. The models that maximize engagement also favor controversy, misinformation, and extremism: put simply, people just like outrageous stuff. Sometimes this inflames existing political tensions. The most devastating example to date is the case of Myanmar, where viral fake news and hate speech about the Rohingya Muslim minority escalated the country’s religious conflict into a full-blown genocide. Facebook admitted in 2018, after years of downplaying its role, that it had not done enough “to help prevent our platform from being used to foment division and incite offline violence.”
While Facebook may have been oblivious to these consequences in the beginning, it was studying them by 2016. In an internal presentation from that year, reviewed by the Wall Street Journal, a company researcher, Monica Lee, found that Facebook was not only hosting a large number of extremist groups but also promoting them to its users: “64% of all extremist group joins are due to our recommendation tools,” the presentation said, predominantly thanks to the models behind the “Groups You Should Join” and “Discover” features.
“The question for leadership was: Should we be optimizing for engagement if you find that somebody is in a vulnerable state of mind?”
A former AI researcher who joined in 2018
In 2017, Chris Cox, Facebook’s longtime chief product officer, formed a new task force to understand whether maximizing user engagement on Facebook was contributing to political polarization. It found that there was indeed a correlation, and that reducing polarization would mean taking a hit on engagement. In a mid-2018 document reviewed by the Journal, the task force proposed several potential fixes, such as tweaking the recommendation algorithms to suggest a more diverse range of groups for people to join. But it acknowledged that some of the ideas were “antigrowth.” Most of the proposals didn’t move forward, and the task force disbanded.
Since then, other employees have corroborated these findings. A former Facebook AI researcher who joined in 2018 says he and his team conducted “study after study” confirming the same basic idea: models that maximize engagement increase polarization. They could easily track how strongly users agreed or disagreed on different issues, what content they liked to engage with, and how their stances changed as a result. Regardless of the issue, the models learned to feed users increasingly extreme viewpoints. “Over time they measurably become more polarized,” he says.
The researcher’s team also found that users with a tendency to post or engage with melancholy content—a possible sign of depression—could easily spiral into consuming increasingly negative material that risked further worsening their mental health. The team proposed tweaking the content-ranking models for these users to stop maximizing engagement alone, so they would be shown less of the depressing stuff. “The question for leadership was: Should we be optimizing for engagement if you find that somebody is in a vulnerable state of mind?” he remembers. (A Facebook spokesperson said she could not find documentation for this proposal.)
But anything that reduced engagement, even for reasons such as not exacerbating someone’s depression, led to a lot of hemming and hawing among leadership. With their performance reviews and salaries tied to the successful completion of projects, employees quickly learned to drop those that received pushback and continue working on those dictated from the top down.
One such project heavily pushed by company leaders involved predicting whether a user might be at risk for something several people had already done: livestreaming their own suicide on Facebook Live. The task involved building a model to analyze the comments that other users were posting on a video after it had gone live, and bringing at-risk users to the attention of trained Facebook community reviewers who could call local emergency responders to perform a wellness check. It didn’t require any changes to content-ranking models, had negligible impact on engagement, and effectively fended off negative press. It was also nearly impossible, says the researcher: “It’s more of a PR stunt. The efficacy of trying to determine if somebody is going to kill themselves in the next 30 seconds, based on the first 10 seconds of video analysis—you’re not going to be very effective.”
Facebook disputes this characterization, saying the team that worked on this effort has since successfully predicted which users were at risk and increased the number of wellness checks performed. But the company does not release data on the accuracy of its predictions or how many wellness checks turned out to be real emergencies.
That former employee, meanwhile, no longer lets his daughter use Facebook.
Quiñonero should have been perfectly placed to tackle these problems when he created the SAIL (later Responsible AI) team in April 2018. His time as the director of Applied Machine Learning had made him intimately familiar with the company’s algorithms, especially the ones used for recommending posts, ads, and other content to users.
It also seemed that Facebook was ready to take these problems seriously. Whereas previous efforts to work on them had been scattered across the company, Quiñonero was now being granted a centralized team with leeway in his mandate to work on whatever he saw fit at the intersection of AI and society.
At the time, Quiñonero was engaging in his own reeducation about how to be a responsible technologist. The field of AI research was paying growing attention to problems of AI bias and accountability in the wake of high-profile studies showing that, for example, an algorithm was scoring Black defendants as more likely to be rearrested than white defendants who’d been arrested for the same or a more serious offense. Quiñonero began studying the scientific literature on algorithmic fairness, reading books on ethical engineering and the history of technology, and speaking with civil rights experts and moral philosophers.
Over the many hours I spent with him, I could tell he took this seriously. He had joined Facebook amid the Arab Spring, a series of revolutions against oppressive Middle Eastern regimes. Experts had lauded social media for spreading the information that fueled the uprisings and giving people tools to organize. Born in Spain but raised in Morocco, where he’d seen the suppression of free speech firsthand, Quiñonero felt an intense connection to Facebook’s potential as a force for good.
Six years later, Cambridge Analytica had threatened to overturn this promise. The controversy forced him to confront his faith in the company and examine what staying would mean for his integrity. “I think what happens to most people who work at Facebook—and definitely has been my story—is that there’s no boundary between Facebook and me,” he says. “It’s extremely personal.” But he chose to stay, and to head SAIL, because he believed he could do more for the world by helping turn the company around than by leaving it behind.
“I think if you’re at a company like Facebook, especially over the last few years, you really realize the impact that your products have on people’s lives—on what they think, how they communicate, how they interact with each other,” says Quiñonero’s longtime friend Zoubin Ghahramani, who helps lead the Google Brain team. “I know Joaquin cares deeply about all aspects of this. As somebody who strives to achieve better and improve things, he sees the important role that he can have in shaping both the thinking and the policies around responsible AI.”
At first, SAIL had only five people, who came from different parts of the company but were all interested in the societal impact of algorithms. One founding member, Isabel Kloumann, a research scientist who’d come from the company’s core data science team, brought with her an initial version of a tool to measure the bias in AI models.
The team also brainstormed many other ideas for projects. The former leader in the AI org, who was present for some of the early meetings of SAIL, recalls one proposal for combating polarization. It involved using sentiment analysis, a form of machine learning that interprets opinion in bits of text, to better identify comments that expressed extreme points of view. These comments wouldn’t be deleted, but they would be hidden by default with an option to reveal them, thus limiting the number of people who saw them.
And there were discussions about what role SAIL could play within Facebook and how it should evolve over time. The sentiment was that the team would first produce responsible-AI guidelines to tell the product teams what they should or should not do. But the hope was that it would ultimately serve as the company’s central hub for evaluating AI projects and stopping those that didn’t follow the guidelines.
Former employees described, however, how hard it could be to get buy-in or financial support when the work didn’t directly improve Facebook’s growth. By its nature, the team was not thinking about growth, and in some cases it was proposing ideas antithetical to growth. As a result, it received few resources and languished. Many of its ideas stayed largely academic.
On August 29, 2018, that suddenly changed. In the ramp-up to the US midterm elections, President Donald Trump and other Republican leaders ratcheted up accusations that Facebook, Twitter, and Google had anti-conservative bias. They claimed that Facebook’s moderators in particular, in applying the community standards, were suppressing conservative voices more than liberal ones. This charge would later be debunked, but the hashtag #StopTheBias, fueled by a Trump tweet, was rapidly spreading on social media.
For Trump, it was the latest effort to sow distrust in the country’s mainstream information distribution channels. For Zuckerberg, it threatened to alienate Facebook’s conservative US users and make the company more vulnerable to regulation from a Republican-led government. In other words, it threatened the company’s growth.
Facebook did not grant me an interview with Zuckerberg, but previousreporting has shown how he increasingly pandered to Trump and the Republican leadership. After Trump was elected, Joel Kaplan, Facebook’s VP of global public policy and its highest-ranking Republican, advised Zuckerberg to tread carefully in the new political environment.
On September 20, 2018, three weeks after Trump’s #StopTheBias tweet, Zuckerberg held a meeting with Quiñonero for the first time since SAIL’s creation. He wanted to know everything Quiñonero had learned about AI bias and how to quash it in Facebook’s content-moderation models. By the end of the meeting, one thing was clear: AI bias was now Quiñonero’s top priority. “The leadership has been very, very pushy about making sure we scale this aggressively,” says Rachad Alao, the engineering director of Responsible AI who joined in April 2019.
It was a win for everybody in the room. Zuckerberg got a way to ward off charges of anti-conservative bias. And Quiñonero now had more money and a bigger team to make the overall Facebook experience better for users. They could build upon Kloumann’s existing tool in order to measure and correct the alleged anti-conservative bias in content-moderation models, as well as to correct other types of bias in the vast majority of models across the platform.
This could help prevent the platform from unintentionally discriminating against certain users. By then, Facebook already had thousands of models running concurrently, and almost none had been measured for bias. That would get it into legal trouble a few months later with the US Department of Housing and Urban Development (HUD), which alleged that the company’s algorithms were inferring “protected” attributes like race from users’ data and showing them ads for housing based on those attributes—an illegal form of discrimination. (The lawsuit is still pending.) Schroepfer also predicted that Congress would soon pass laws to regulate algorithmic discrimination, so Facebook needed to make headway on these efforts anyway.
(Facebook disputes the idea that it pursued its work on AI bias to protect growth or in anticipation of regulation. “We built the Responsible AI team because it was the right thing to do,” a spokesperson said.)
But narrowing SAIL’s focus to algorithmic fairness would sideline all Facebook’s other long-standing algorithmic problems. Its content-recommendation models would continue pushing posts, news, and groups to users in an effort to maximize engagement, rewarding extremist content and contributing to increasingly fractured political discourse.
Zuckerberg even admitted this. Two months after the meeting with Quiñonero, in a public note outlining Facebook’s plans for content moderation, he illustrated the harmful effects of the company’s engagement strategy with a simplified chart. It showed that the more likely a post is to violate Facebook’s community standards, the more user engagement it receives, because the algorithms that maximize engagement reward inflammatory content.
But then he showed another chart with the inverse relationship. Rather than rewarding content that came close to violating the community standards, Zuckerberg wrote, Facebook could choose to start “penalizing” it, giving it “less distribution and engagement” rather than more. How would this be done? With more AI. Facebook would develop better content-moderation models to detect this “borderline content” so it could be retroactively pushed lower in the news feed to snuff out its virality, he said.
The problem is that for all Zuckerberg’s promises, this strategy is tenuous at best.
Misinformation and hate speech constantly evolve. New falsehoods spring up; new people and groups become targets. To catch things before they go viral, content-moderation models must be able to identify new unwanted content with high accuracy. But machine-learning models do not work that way. An algorithm that has learned to recognize Holocaust denial can’t immediately spot, say, Rohingya genocide denial. It must be trained on thousands, often even millions, of examples of a new type of content before learning to filter it out. Even then, users can quickly learn to outwit the model by doing things like changing the wording of a post or replacing incendiary phrases with euphemisms, making their message illegible to the AI while still obvious to a human. This is why new conspiracy theories can rapidly spiral out of control, and partly why, even after such content is banned, forms of it canpersist on the platform.
In his New York Times profile, Schroepfer named these limitations of the company’s content-moderation strategy. “Every time Mr. Schroepfer and his more than 150 engineering specialists create A.I. solutions that flag and squelch noxious material, new and dubious posts that the A.I. systems have never seen before pop up—and are thus not caught,” wrote the Times. “It’s never going to go to zero,” Schroepfer told the publication.
Meanwhile, the algorithms that recommend this content still work to maximize engagement. This means every toxic post that escapes the content-moderation filters will continue to be pushed higher up the news feed and promoted to reach a larger audience. Indeed, a study from New York University recently found that among partisan publishers’ Facebook pages, those that regularly posted political misinformation received the most engagement in the lead-up to the 2020 US presidential election and the Capitol riots. “That just kind of got me,” says a former employee who worked on integrity issues from 2018 to 2019. “We fully acknowledged [this], and yet we’re still increasing engagement.”
But Quiñonero’s SAIL team wasn’t working on this problem. Because of Kaplan’s and Zuckerberg’s worries about alienating conservatives, the team stayed focused on bias. And even after it merged into the bigger Responsible AI team, it was never mandated to work on content-recommendation systems that might limit the spread of misinformation. Nor has any other team, as I confirmed after Entin and another spokesperson gave me a full list of all Facebook’s other initiatives on integrity issues—the company’s umbrella term for problems including misinformation, hate speech, and polarization.
A Facebook spokesperson said, “The work isn’t done by one specific team because that’s not how the company operates.” It is instead distributed among the teams that have the specific expertise to tackle how content ranking affects misinformation for their part of the platform, she said. But Schroepfer told me precisely the opposite in an earlier interview. I had asked him why he had created a centralized Responsible AI team instead of directing existing teams to make progress on the issue. He said it was “best practice” at the company.
“[If] it’s an important area, we need to move fast on it, it’s not well-defined, [we create] a dedicated team and get the right leadership,” he said. “As an area grows and matures, you’ll see the product teams take on more work, but the central team is still needed because you need to stay up with state-of-the-art work.”
When I described the Responsible AI team’s work to other experts on AI ethics and human rights, they noted the incongruity between the problems it was tackling and those, like misinformation, for which Facebook is most notorious. “This seems to be so oddly removed from Facebook as a product—the things Facebook builds and the questions about impact on the world that Facebook faces,” said Rumman Chowdhury, whose startup, Parity, advises firms on the responsible use of AI, and was acquired by Twitter after our interview. I had shown Chowdhury the Quiñonero team’s documentation detailing its work. “I find it surprising that we’re going to talk about inclusivity, fairness, equity, and not talk about the very real issues happening today,” she said.
“It seems like the ‘responsible AI’ framing is completely subjective to what a company decides it wants to care about. It’s like, ‘We’ll make up the terms and then we’ll follow them,’” says Ellery Roberts Biddle, the editorial director of Ranking Digital Rights, a nonprofit that studies the impact of tech companies on human rights. “I don’t even understand what they mean when they talk about fairness. Do they think it’s fair to recommend that people join extremist groups, like the ones that stormed the Capitol? If everyone gets the recommendation, does that mean it was fair?”
“We’re at a place where there’s one genocide [Myanmar] that the UN has, with a lot of evidence, been able to specifically point to Facebook and to the way that the platform promotes content,” Biddle adds. “How much higher can the stakes get?”
Over the last two years, Quiñonero’s team has built out Kloumann’s original tool, called Fairness Flow. It allows engineers to measure the accuracy of machine-learning models for different user groups. They can compare a face-detection model’s accuracy across different ages, genders, and skin tones, or a speech-recognition algorithm’s accuracy across different languages, dialects, and accents.
Fairness Flow also comes with a set of guidelines to help engineers understand what it means to train a “fair” model. One of the thornier problems with making algorithms fair is that there are different definitions of fairness, which can be mutually incompatible. Fairness Flow lists four definitions that engineers can use according to which suits their purpose best, such as whether a speech-recognition model recognizes all accents with equal accuracy or with a minimum threshold of accuracy.
But testing algorithms for fairness is still largely optional at Facebook. None of the teams that work directly on Facebook’s news feed, ad service, or other products are required to do it. Pay incentives are still tied to engagement and growth metrics. And while there are guidelines about which fairness definition to use in any given situation, they aren’t enforced.
This last problem came to the fore when the company had to deal with allegations of anti-conservative bias.
In 2014, Kaplan was promoted from US policy head to global vice president for policy, and he began playing a more heavy-handed role in content moderation and decisions about how to rank posts in users’ news feeds. After Republicans started voicing claims of anti-conservative bias in 2016, his team began manually reviewing the impact of misinformation-detection models on users to ensure—among other things—that they didn’t disproportionately penalize conservatives.
All Facebook users have some 200 “traits” attached to their profile. These include various dimensions submitted by users or estimated by machine-learning models, such as race, political and religious leanings, socioeconomic class, and level of education. Kaplan’s team began using the traits to assemble custom user segments that reflected largely conservative interests: users who engaged with conservative content, groups, and pages, for example. Then they’d run special analyses to see how content-moderation decisions would affect posts from those segments, according to a former researcher whose work was subject to those reviews.
The Fairness Flow documentation, which the Responsible AI team wrote later, includes a case study on how to use the tool in such a situation. When deciding whether a misinformation model is fair with respect to political ideology, the team wrote, “fairness” does not mean the model should affect conservative and liberal users equally. If conservatives are posting a greater fraction of misinformation, as judged by public consensus, then the model should flag a greater fraction of conservative content. If liberals are posting more misinformation, it should flag their content more often too.
But members of Kaplan’s team followed exactly the opposite approach: they took “fairness” to mean that these models should not affect conservatives more than liberals. When a model did so, they would stop its deployment and demand a change. Once, they blocked a medical-misinformation detector that had noticeably reduced the reach of anti-vaccine campaigns, the former researcher told me. They told the researchers that the model could not be deployed until the team fixed this discrepancy. But that effectively made the model meaningless. “There’s no point, then,” the researcher says. A model modified in that way “would have literally no impact on the actual problem” of misinformation.
“I don’t even understand what they mean when they talk about fairness. Do they think it’s fair to recommend that people join extremist groups, like the ones that stormed the Capitol? If everyone gets the recommendation, does that mean it was fair?”
Ellery Roberts Biddle, editorial director of Ranking Digital Rights
This happened countless other times—and not just for content moderation. In 2020, the Washington Post reported that Kaplan’s team had undermined efforts to mitigate election interference and polarization within Facebook, saying they could contribute to anti-conservative bias. In 2018, it used the same argument to shelve a project to edit Facebook’s recommendation models even though researchers believed it would reduce divisiveness on the platform, according to the Wall Street Journal. His claims about political bias also weakened a proposal to edit the ranking models for the news feed that Facebook’s data scientists believed would strengthen the platform against the manipulation tactics Russia had used during the 2016 US election.
And ahead of the 2020 election, Facebook policy executives used this excuse, according to the New York Times, to veto or weaken several proposals that would have reduced the spread of hateful and damaging content.
Facebook disputed the Wall Street Journal’s reporting in a follow-up blog post, and challenged the New York Times’s characterization in an interview with the publication. A spokesperson for Kaplan’s team also denied to me that this was a pattern of behavior, saying the cases reported by the Post, the Journal, and the Times were “all individual instances that we believe are then mischaracterized.” He declined to comment about the retraining of misinformation models on the record.
Many of these incidents happened before Fairness Flow was adopted. But they show how Facebook’s pursuit of fairness in the service of growth had already come at a steep cost to progress on the platform’s other challenges. And if engineers used the definition of fairness that Kaplan’s team had adopted, Fairness Flow could simply systematize behavior that rewarded misinformation instead of helping to combat it.
Often “the whole fairness thing” came into play only as a convenient way to maintain the status quo, the former researcher says: “It seems to fly in the face of the things that Mark was saying publicly in terms of being fair and equitable.”
The last time I spoke with Quiñonero was a month after the US Capitol riots. I wanted to know how the storming of Congress had affected his thinking and the direction of his work.
In the video call, it was as it always was: Quiñonero dialing in from his home office in one window and Entin, his PR handler, in another. I asked Quiñonero what role he felt Facebook had played in the riots and whether it changed the task he saw for Responsible AI. After a long pause, he sidestepped the question, launching into a description of recent work he’d done to promote greater diversity and inclusion among the AI teams.
I asked him the question again. His Facebook Portal camera, which uses computer-vision algorithms to track the speaker, began to slowly zoom in on his face as he grew still. “I don’t know that I have an easy answer to that question, Karen,” he said. “It’s an extremely difficult question to ask me.”
Entin, who’d been rapidly pacing with a stoic poker face, grabbed a red stress ball.
I asked Quiñonero why his team hadn’t previously looked at ways to edit Facebook’s content-ranking models to tamp down misinformation and extremism. He told me it was the job of other teams (though none, as I confirmed, have been mandated to work on that task). “It’s not feasible for the Responsible AI team to study all those things ourselves,” he said. When I asked whether he would consider having his team tackle those issues in the future, he vaguely admitted, “I would agree with you that that is going to be the scope of these types of conversations.”
Near the end of our hour-long interview, he began to emphasize that AI was often unfairly painted as “the culprit.” Regardless of whether Facebook used AI or not, he said, people would still spew lies and hate speech, and that content would still spread across the platform.
I pressed him one more time. Certainly he couldn’t believe that algorithms had done absolutely nothing to change the nature of these issues, I said.
“I don’t know,” he said with a halting stutter. Then he repeated, with more conviction: “That’s my honest answer. Honest to God. I don’t know.”
Corrections:We amended a line that suggested that Joel Kaplan, Facebook’s vice president of global policy, had used Fairness Flow. He has not. But members of his team have used the notion of fairness to request the retraining of misinformation models in ways that directly contradict Responsible AI’s guidelines. We also clarified when Rachad Alao, the engineering director of Responsible AI, joined the company.
This combination of satellite images provided by the National Hurricane Center shows 30 hurricanes that occurred during the 2020 Atlantic hurricane season.
We’re one step closer to officially moving up hurricane season. The National Hurricane Center announced Tuesday that it would formally start issuing its hurricane season tropical weather outlooks on May 15 this year, bumping it up from the traditional start of hurricane season on June 1. The move comes after a recent spate of early season storms have raked the Atlantic.
Atlantic hurricane season runs from June 1 to November 30. That’s when conditions are most conducive to storm formation owing to warm air and water temperatures. (The Pacific ocean has its own hurricane season, which covers the same timeframe, but since waters are colder fewer hurricanes tend to form there than in the Atlantic.)
Storms have begun forming on the Atlantic earlier as ocean and air temperatures have increased due to climate change. Last year, Hurricane Arthur roared to life off the East Coast on May 16. That storm made 2020 the sixth hurricane season in a row to have a storm that formed earlier than the June 1 official start date. While the National Oceanic and Atmospheric Administration won’t be moving up the start of the season just yet, the earlier outlooks addresses the recent history.
“In the last decade, there have been 10 storms formed in the weeks before the traditional start of the season, which is a big jump,” said Sean Sublette, a meteorologist at Climate Central, who pointed out that the 1960s through 2010s saw between one and three storms each decade before the June 1 start date on average.
It might be tempting to ascribe this earlier season entirely to climate change warming the Atlantic. But technology also has a role to play, with more observations along the coast as well as satellites that can spot storms far out to sea.
“I would caution that we can’t just go, ‘hah, the planet’s warming, we’ve had to move the entire season!’” Sublette said. “I don’t think there’s solid ground for attribution of how much of one there is over the other. Weather folks can sit around and debate that for awhile.”
Earlier storms don’t necessarily mean more harmful ones, either. In fact, hurricanes earlier in the season tend to be weaker than the monsters that form in August and September when hurricane season is at its peak. But regardless of their strength, these earlier storms have generated discussion inside the NHC on whether to move up the official start date for the season, when the agency usually puts out two reports per day on hurricane activity. Tuesday’s step is not an official announcement of this decision, but an acknowledgement of the increased attention on early hurricanes.
“I would say that [Tuesday’s announcement] is the National Hurricane Center being proactive,” Sublette said. “Like hey, we know that the last few years it’s been a little busier in May than we’ve seen in the past five decades, and we know there is an awareness now, so we’re going to start issuing these reports early.”
While the jury is still out on whether climate change is pushing the season earlier, research has shown that the strongest hurricanes are becoming more common, and that climate change is likely playing a role. A study published last year found the odds of a storm becoming a major hurricanes—those Category 3 or stronger—have increase 49% in the basin since satellite monitoring began in earnest four decades ago. And when storms make landfall, sea level rise allows them to do more damage. So regardless of if climate change is pushing Atlantic hurricane season is getting earlier or not, the risks are increasing. Now, at least, we’ll have better warnings before early storms do hit.
Lincoln Park in Chicago. Scientists are hopeful, as vaccinations continue and despite the emergence of variants, that we’re past the worst of the pandemic. Credit: Lyndon French for The New York Times
Many scientists are expecting another rise in infections. But this time the surge will be blunted by vaccines and, hopefully, widespread caution. By summer, Americans may be looking at a return to normal life.
Published Feb. 25, 2021Updated Feb. 26, 2021, 12:07 a.m. ET
Across the United States, and the world, the coronavirus seems to be loosening its stranglehold. The deadly curve of cases, hospitalizations and deaths has yo-yoed before, but never has it plunged so steeply and so fast.
Is this it, then? Is this the beginning of the end? After a year of being pummeled by grim statistics and scolded for wanting human contact, many Americans feel a long-promised deliverance is at hand.
Americans will win against the virus and regain many aspects of their pre-pandemic lives, most scientists now believe. Of the 21 interviewed for this article, all were optimistic that the worst of the pandemic is past. This summer, they said, life may begin to seem normal again.
But — of course, there’s always a but — researchers are also worried that Americans, so close to the finish line, may once again underestimate the virus.
So far, the two vaccines authorized in the United States are spectacularly effective, and after a slow start, the vaccination rollout is picking up momentum. A third vaccine is likely to be authorized shortly, adding to the nation’s supply.
But it will be many weeks before vaccinations make a dent in the pandemic. And now the virus is shape-shifting faster than expected, evolving into variants that may partly sidestep the immune system.
The latest variant was discovered in New York City only this week, and another worrisome version is spreading at a rapid pace through California. Scientists say a contagious variant first discovered in Britain will become the dominant form of the virus in the United States by the end of March.
The road back to normalcy is potholed with unknowns: how well vaccines prevent further spread of the virus; whether emerging variants remain susceptible enough to the vaccines; and how quickly the world is immunized, so as to halt further evolution of the virus.
But the greatest ambiguity is human behavior. Can Americans desperate for normalcy keep wearing masks and distancing themselves from family and friends? How much longer can communities keep businesses, offices and schools closed?
Covid-19 deaths will most likely never rise quite as precipitously as in the past, and the worst may be behind us. But if Americans let down their guard too soon — many states are already lifting restrictions — and if the variants spread in the United States as they have elsewhere, another spike in cases may well arrive in the coming weeks.
Scientists call it the fourth wave. The new variants mean “we’re essentially facing a pandemic within a pandemic,” said Adam Kucharski, an epidemiologist at the London School of Hygiene and Tropical Medicine.
The declines are real, but they disguise worrying trends.
Credit: Daniel Dreifuss for The New York Times
The United States has now recorded 500,000 deaths amid the pandemic, a terrible milestone. As of Wednesday morning, at least 28.3 million people have been infected.
But the rate of new infections has tumbled by 35 percent over the past two weeks, according to a database maintained by The New York Times. Hospitalizations are down 31 percent, and deaths have fallen by 16 percent.
Yet the numbers are still at the horrific highs of November, scientists noted. At least 3,210 people died of Covid-19 on Wednesday alone. And there is no guarantee that these rates will continue to decrease.
“Very, very high case numbers are not a good thing, even if the trend is downward,” said Marc Lipsitch, an epidemiologist at the Harvard T.H. Chan School of Public Health in Boston. “Taking the first hint of a downward trend as a reason to reopen is how you get to even higher numbers.”
In late November, for example, Gov. Gina Raimondo of Rhode Island limited social gatherings and some commercial activities in the state. Eight days later, cases began to decline. The trend reversed eight days after the state’s pause lifted on Dec. 20.
The virus’s latest retreat in Rhode Island and most other states, experts said, results from a combination of factors: growing numbers of people with immunity to the virus, either from having been infected or from vaccination; changes in behavior in response to the surges of a few weeks ago; and a dash of seasonality — the effect of temperature and humidity on the survival of the virus.
The vaccines were first rolled out to residents of nursing homes and to the elderly, who are at highest risk of severe illness and death. That may explain some of the current decline in hospitalizations and deaths.
Credit: Joao Silva/The New York Times
But young people drive the spread of the virus, and most of them have not yet been inoculated. And the bulk of the world’s vaccine supply has been bought up by wealthy nations, which have amassed one billion more doses than needed to immunize their populations.
Vaccination cannot explain why cases are dropping even in countries where not a single soul has been immunized, like Honduras, Kazakhstan or Libya. The biggest contributor to the sharp decline in infections is something more mundane, scientists say: behavioral change.
Leaders in the United States and elsewhere stepped up community restrictions after the holiday peaks. But individual choices have also been important, said Lindsay Wiley, an expert in public health law and ethics at American University in Washington.
“People voluntarily change their behavior as they see their local hospital get hit hard, as they hear about outbreaks in their area,” she said. “If that’s the reason that things are improving, then that’s something that can reverse pretty quickly, too.”
The downward curve of infections with the original coronavirus disguises an exponential rise in infections with B.1.1.7, the variant first identified in Britain, according to many researchers.
“We really are seeing two epidemic curves,” said Ashleigh Tuite, an infectious disease modeler at the University of Toronto.
The B.1.1.7 variant is thought to be more contagious and more deadly, and it is expected to become the predominant form of the virus in the United States by late March. The number of cases with the variant in the United States has risen from 76 in 12 states as of Jan. 13 to more than 1,800 in 45 states now. Actual infections may be much higher because of inadequate surveillance efforts in the United States.
Buoyed by the shrinking rates over all, however, governors are lifting restrictions across the United States and are under enormous pressure to reopen completely. Should that occur, B.1.1.7 and the other variants are likely to explode.
“Everybody is tired, and everybody wants things to open up again,” Dr. Tuite said. “Bending to political pressure right now, when things are really headed in the right direction, is going to end up costing us in the long term.”
Another wave may be coming, but it can be minimized.
Credit: Lyndon French for The New York Times
Looking ahead to late March or April, the majority of scientists interviewed by The Times predicted a fourth wave of infections. But they stressed that it is not an inevitable surge, if government officials and individuals maintain precautions for a few more weeks.
A minority of experts were more sanguine, saying they expected powerful vaccines and an expanding rollout to stop the virus. And a few took the middle road.
“We’re at that crossroads, where it could go well or it could go badly,” said Dr. Anthony Fauci, director of the National Institute of Allergy and Infectious Diseases.
The vaccines have proved to be more effective than anyone could have hoped, so far preventing serious illness and death in nearly all recipients. At present, about 1.4 million Americans are vaccinated each day. More than 45 million Americans have received at least one dose.
A team of researchers at Fred Hutchinson Cancer Research Center in Seattle tried to calculate the number of vaccinations required per day to avoid a fourth wave. In a model completed before the variants surfaced, the scientists estimated that vaccinating just one million Americans a day would limit the magnitude of the fourth wave.
“But the new variants completely changed that,” said Dr. Joshua T. Schiffer, an infectious disease specialist who led the study. “It’s just very challenging scientifically — the ground is shifting very, very quickly.”
Natalie Dean, a biostatistician at the University of Florida, described herself as “a little more optimistic” than many other researchers. “We would be silly to undersell the vaccines,” she said, noting that they are effective against the fast-spreading B.1.1.7 variant.
But Dr. Dean worried about the forms of the virus detected in South Africa and Brazil that seem less vulnerable to the vaccines made by Pfizer and Moderna. (On Wednesday, Johnson & Johnson reported that its vaccine was relatively effective against the variant found in South Africa.)
Credit: Pete Kiehart for The New York Times
About 50 infections with those two variants have been identified in the United States, but that could change. Because of the variants, scientists do not know how many people who were infected and had recovered are now vulnerable to reinfection.
South Africa and Brazil have reported reinfections with the new variants among people who had recovered from infections with the original version of the virus.
“That makes it a lot harder to say, ‘If we were to get to this level of vaccinations, we’d probably be OK,’” said Sarah Cobey, an evolutionary biologist at the University of Chicago.
Yet the biggest unknown is human behavior, experts said. The sharp drop in cases now may lead to complacency about masks and distancing, and to a wholesale lifting of restrictions on indoor dining, sporting events and more. Or … not.
“The single biggest lesson I’ve learned during the pandemic is that epidemiological modeling struggles with prediction, because so much of it depends on human behavioral factors,” said Carl Bergstrom, a biologist at the University of Washington in Seattle.
Taking into account the counterbalancing rises in both vaccinations and variants, along with the high likelihood that people will stop taking precautions, a fourth wave is highly likely this spring, the majority of experts told The Times.
Kristian Andersen, a virologist at the Scripps Research Institute in San Diego, said he was confident that the number of cases will continue to decline, then plateau in about a month. After mid-March, the curve in new cases will swing upward again.
In early to mid-April, “we’re going to start seeing hospitalizations go up,” he said. “It’s just a question of how much.”
Summer will feel like summer again, sort of.
Credit: Kendrick Brinson for The New York Times
Now the good news.
Despite the uncertainties, the experts predict that the last surge will subside in the United States sometime in the early summer. If the Biden administration can keep its promise to immunize every American adult by the end of the summer, the variants should be no match for the vaccines.
Combine vaccination with natural immunity and the human tendency to head outdoors as weather warms, and “it may not be exactly herd immunity, but maybe it’s sufficient to prevent any large outbreaks,” said Youyang Gu, an independent data scientist, who created some of the most prescient models of the pandemic.
Infections will continue to drop. More important, hospitalizations and deaths will fall to negligible levels — enough, hopefully, to reopen the country.
“Sometimes people lose vision of the fact that vaccines prevent hospitalization and death, which is really actually what most people care about,” said Stefan Baral, an epidemiologist at the Johns Hopkins Bloomberg School of Public Health.
Even as the virus begins its swoon, people may still need to wear masks in public places and maintain social distance, because a significant percent of the population — including children — will not be immunized.
“Assuming that we keep a close eye on things in the summer and don’t go crazy, I think that we could look forward to a summer that is looking more normal, but hopefully in a way that is more carefully monitored than last summer,” said Emma Hodcroft, a molecular epidemiologist at the University of Bern in Switzerland.
Imagine: Groups of vaccinated people will be able to get together for barbecues and play dates, without fear of infecting one another. Beaches, parks and playgrounds will be full of mask-free people. Indoor dining will return, along with movie theaters, bowling alleys and shopping malls — although they may still require masks.
The virus will still be circulating, but the extent will depend in part on how well vaccines prevent not just illness and death, but also transmission. The data on whether vaccines stop the spread of the disease are encouraging, but immunization is unlikely to block transmission entirely.
Credit: Pete Kiehart for The New York Times
“It’s not zero and it’s not 100 — exactly where that number is will be important,” said Shweta Bansal, an infectious disease modeler at Georgetown University. “It needs to be pretty darn high for us to be able to get away with vaccinating anything below 100 percent of the population, so that’s definitely something we’re watching.”
Over the long term — say, a year from now, when all the adults and children in the United States who want a vaccine have received them — will this virus finally be behind us?
Every expert interviewed by The Times said no. Even after the vast majority of the American population has been immunized, the virus will continue to pop up in clusters, taking advantage of pockets of vulnerability. Years from now, the coronavirus may be an annoyance, circulating at low levels, causing modest colds.
Many scientists said their greatest worry post-pandemic was that new variants may turn out to be significantly less susceptible to the vaccines. Billions of people worldwide will remain unprotected, and each infection gives the virus new opportunities to mutate.
“We won’t have useless vaccines. We might have slightly less good vaccines than we have at the moment,” said Andrew Read, an evolutionary microbiologist at Penn State University. “That’s not the end of the world, because we have really good vaccines right now.”
For now, every one of us can help by continuing to be careful for just a few more months, until the curve permanently flattens.
“Just hang in there a little bit longer,” Dr. Tuite said. “There’s a lot of optimism and hope, but I think we need to be prepared for the fact that the next several months are likely to continue to be difficult.”
The world’s continuously warming climate is revealed also in contemporary ice melt at glaciers, such as with this one in the Kenai mountains, Alaska (seen September 2019). Photograph: Joe Raedle/Getty Images
The planet is hotter now than it has been for at least 12,000 years, a period spanning the entire development of human civilisation, according to research.
Analysis of ocean surface temperatures shows human-driven climate change has put the world in “uncharted territory”, the scientists say. The planet may even be at its warmest for 125,000 years, although data on that far back is less certain.
The research, published in the journal Nature, reached these conclusions by solving a longstanding puzzle known as the “Holocene temperature conundrum”. Climate models have indicated continuous warming since the last ice age ended 12,000 years ago and the Holocene period began. But temperature estimates derived from fossil shells showed a peak of warming 6,000 years ago and then a cooling, until the industrial revolution sent carbon emissions soaring.
This conflict undermined confidence in the climate models and the shell data. But it was found that the shell data reflected only hotter summers and missed colder winters, and so was giving misleadingly high annual temperatures.
“We demonstrate that global average annual temperature has been rising over the last 12,000 years, contrary to previous results,” said Samantha Bova, at Rutgers University–New Brunswick in the US, who led the research. “This means that the modern, human-caused global warming period is accelerating a long-term increase in global temperatures, making today completely uncharted territory. It changes the baseline and emphasises just how critical it is to take our situation seriously.”
The world may be hotter now than any time since about 125,000 years ago, which was the last warm period between ice ages. However, scientists cannot be certain as there is less data relating to that time.
One study, published in 2017, suggested that global temperatures were last as high as today 115,000 years ago, but that was based on less data.
The new research is published in the journal Nature and examined temperature measurements derived from the chemistry of tiny shells and algal compounds found in cores of ocean sediments, and solved the conundrum by taking account of two factors.
First, the shells and organic materials had been assumed to represent the entire year but in fact were most likely to have formed during summer when the organisms bloomed. Second, there are well-known predictable natural cycles in the heating of the Earth caused by eccentricities in the orbit of the planet. Changes in these cycles can lead to summers becoming hotter and winters colder while average annual temperatures change only a little.
Combining these insights showed that the apparent cooling after the warm peak 6,000 years ago, revealed by shell data, was misleading. The shells were in fact only recording a decline in summer temperatures, but the average annual temperatures were still rising slowly, as indicated by the models.
“Now they actually match incredibly well and it gives us a lot of confidence that our climate models are doing a really good job,” said Bova.
The study looked only at ocean temperature records, but Bova said: “The temperature of the sea surface has a really controlling impact on the climate of the Earth. If we know that, it is the best indicator of what global climate is doing.”
She led a research voyage off the coast of Chile in 2020 to take more ocean sediment cores and add to the available data.
Jennifer Hertzberg, of Texas A&M University in the US, said: “By solving a conundrum that has puzzled climate scientists for years, Bova and colleagues’ study is a major step forward. Understanding past climate change is crucial for putting modern global warming in context.”
Lijing Cheng, at the International Centre for Climate and Environment Sciences in Beijing, China, recently led a study that showed that in 2020 the world’s oceans reached their hottest level yet in instrumental records dating back to the 1940s. More than 90% of global heating is taken up by the seas.
Cheng said the new research was useful and intriguing. It provided a method to correct temperature data from shells and could also enable scientists to work out how much heat the ocean absorbed before the industrial revolution, a factor little understood.
The level of carbon dioxide today is at its highest for about 4m years and is rising at the fastest rate for 66m years. Further rises in temperature and sea level are inevitable until greenhouse gas emissions are cut to net zero.
A ideia da inteligência artificial derrubar a humanidade tem sido discutida por muitas décadas, e os cientistas acabaram de dar seu veredicto sobre se seríamos capazes de controlar uma superinteligência de computador de alto nível. A resposta? Quase definitivamente não.
O problema é que controlar uma superinteligência muito além da compreensão humana exigiria uma simulação dessa superinteligência que podemos analisar. Mas se não formos capazes de compreendê-lo, é impossível criar tal simulação.
Regras como ‘não causar danos aos humanos’ não podem ser definidas se não entendermos o tipo de cenário que uma IA irá criar, sugerem os pesquisadores. Uma vez que um sistema de computador está trabalhando em um nível acima do escopo de nossos programadores, não podemos mais estabelecer limites.
“Uma superinteligência apresenta um problema fundamentalmente diferente daqueles normalmente estudados sob a bandeira da ‘ética do robô’”, escrevem os pesquisadores.
“Isso ocorre porque uma superinteligência é multifacetada e, portanto, potencialmente capaz de mobilizar uma diversidade de recursos para atingir objetivos que são potencialmente incompreensíveis para os humanos, quanto mais controláveis.”
Parte do raciocínio da equipe vem do problema da parada apresentado por Alan Turing em 1936. O problema centra-se em saber se um programa de computador chegará ou não a uma conclusão e responderá (para que seja interrompido), ou simplesmente ficar em um loop eterno tentando encontrar uma.
Como Turing provou por meio de uma matemática inteligente, embora possamos saber isso para alguns programas específicos, é logicamente impossível encontrar uma maneira que nos permita saber isso para cada programa potencial que poderia ser escrito. Isso nos leva de volta à IA, que, em um estado superinteligente, poderia armazenar todos os programas de computador possíveis em sua memória de uma vez.
Qualquer programa escrito para impedir que a IA prejudique humanos e destrua o mundo, por exemplo, pode chegar a uma conclusão (e parar) ou não – é matematicamente impossível para nós estarmos absolutamente seguros de qualquer maneira, o que significa que não pode ser contido.
“Na verdade, isso torna o algoritmo de contenção inutilizável”, diz o cientista da computação Iyad Rahwan, do Instituto Max-Planck para o Desenvolvimento Humano, na Alemanha.
A alternativa de ensinar alguma ética à IA e dizer a ela para não destruir o mundo – algo que nenhum algoritmo pode ter certeza absoluta de fazer, dizem os pesquisadores – é limitar as capacidades da superinteligência. Ele pode ser cortado de partes da Internet ou de certas redes, por exemplo.
O novo estudo também rejeita essa ideia, sugerindo que isso limitaria o alcance da inteligência artificial – o argumento é que se não vamos usá-la para resolver problemas além do escopo dos humanos, então por que criá-la?
Se vamos avançar com a inteligência artificial, podemos nem saber quando chega uma superinteligência além do nosso controle, tal é a sua incompreensibilidade. Isso significa que precisamos começar a fazer algumas perguntas sérias sobre as direções que estamos tomando.
“Uma máquina superinteligente que controla o mundo parece ficção científica”, diz o cientista da computação Manuel Cebrian, do Instituto Max-Planck para o Desenvolvimento Humano. “Mas já existem máquinas que executam certas tarefas importantes de forma independente, sem que os programadores entendam totalmente como as aprenderam.”
“Portanto, surge a questão de saber se isso poderia em algum momento se tornar incontrolável e perigoso para a humanidade.”
Brian Nord is an astrophysicist and machine learning researcher. Photo: Mark Lopez/Argonne National Laboratory
Machine learning algorithms serve us the news we read, the ads we see, and in some cases even drive our cars. But there’s an insidious layer to these algorithms: They rely on data collected by and about humans, and they spit our worst biases right back out at us. For example, job candidate screening algorithms may automatically reject names that sound like they belong to nonwhite people, while facial recognition software is often much worse at recognizing women or nonwhite faces than it is at recognizing white male faces. An increasing number of scientists and institutions are waking up to these issues, and speaking out about the potential for AI to cause harm.
Brian Nord is one such researcher weighing his own work against the potential to cause harm with AI algorithms. Nord is a cosmologist at Fermilab and the University of Chicago, where he uses artificial intelligence to study the cosmos, and he’s been researching a concept for a “self-driving telescope” that can write and test hypotheses with the help of a machine learning algorithm. At the same time, he’s struggling with the idea that the algorithms he’s writing may one day be biased against him—and even used against him—and is working to build a coalition of physicists and computer scientists to fight for more oversight in AI algorithm development.
This interview has been edited and condensed for clarity.
Gizmodo: How did you become a physicist interested in AI and its pitfalls?
Brian Nord: My Ph.d is in cosmology, and when I moved to Fermilab in 2012, I moved into the subfield of strong gravitational lensing. [Editor’s note: Gravitational lenses are places in the night sky where light from distant objects has been bent by the gravitational field of heavy objects in the foreground, making the background objects appear warped and larger.] I spent a few years doing strong lensing science in the traditional way, where we would visually search through terabytes of images, through thousands of candidates of these strong gravitational lenses, because they’re so weird, and no one had figured out a more conventional algorithm to identify them. Around 2015, I got kind of sad at the prospect of only finding these things with my eyes, so I started looking around and found deep learning.
Here we are a few years later—myself and a few other people popularized this idea of using deep learning—and now it’s the standard way to find these objects. People are unlikely to go back to using methods that aren’t deep learning to do galaxy recognition. We got to this point where we saw that deep learning is the thing, and really quickly saw the potential impact of it across astronomy and the sciences. It’s hitting every science now. That is a testament to the promise and peril of this technology, with such a relatively simple tool. Once you have the pieces put together right, you can do a lot of different things easily, without necessarily thinking through the implications.
Gizmodo: So what is deep learning? Why is it good and why is it bad?
BN: Traditional mathematical models (like the F=ma of Newton’s laws) are built by humans to describe patterns in data: We use our current understanding of nature, also known as intuition, to choose the pieces, the shape of these models. This means that they are often limited by what we know or can imagine about a dataset. These models are also typically smaller and are less generally applicable for many problems.
On the other hand, artificial intelligence models can be very large, with many, many degrees of freedom, so they can be made very general and able to describe lots of different data sets. Also, very importantly, they are primarily sculpted by the data that they are exposed to—AI models are shaped by the data with which they are trained. Humans decide what goes into the training set, which is then limited again by what we know or can imagine about that data. It’s not a big jump to see that if you don’t have the right training data, you can fall off the cliff really quickly.
The promise and peril are highly related. In the case of AI, the promise is in the ability to describe data that humans don’t yet know how to describe with our ‘intuitive’ models. But, perilously, the data sets used to train them incorporate our own biases. When it comes to AI recognizing galaxies, we’re risking biased measurements of the universe. When it comes to AI recognizing human faces, when our data sets are biased against Black and Brown faces for example, we risk discrimination that prevents people from using services, that intensifies surveillance apparatus, that jeopardizes human freedoms. It’s critical that we weigh and address these consequences before we imperil people’s lives with our research.
Gizmodo: When did the light bulb go off in your head that AI could be harmful?
BN: I gotta say that it was with the Machine Bias article from ProPublica in 2016, where they discuss recidivism and sentencing procedure in courts. At the time of that article, there was a closed-source algorithm used to make recommendations for sentencing, and judges were allowed to use it. There was no public oversight of this algorithm, which ProPublica found was biased against Black people; people could use algorithms like this willy nilly without accountability. I realized that as a Black man, I had spent the last few years getting excited about neural networks, then saw it quite clearly that these applications that could harm me were already out there, already being used, and we’re already starting to become embedded in our social structure through the criminal justice system. Then I started paying attention more and more. I realized countries across the world were using surveillance technology, incorporating machine learning algorithms, for widespread oppressive uses.
Gizmodo: How did you react? What did you do?
BN: I didn’t want to reinvent the wheel; I wanted to build a coalition. I started looking into groups like Fairness, Accountability and Transparency in Machine Learning, plus Black in AI, who is focused on building communities of Black researchers in the AI field, but who also has the unique awareness of the problem because we are the people who are affected. I started paying attention to the news and saw that Meredith Whittaker had started a think tank to combat these things, and Joy Buolamwini had helped found the Algorithmic Justice League. I brushed up on what computer scientists were doing and started to look at what physicists were doing, because that’s my principal community.
It became clear to folks like me and Savannah Thais that physicists needed to realize that they have a stake in this game. We get government funding, and we tend to take a fundamental approach to research. If we bring that approach to AI, then we have the potential to affect the foundations of how these algorithms work and impact a broader set of applications. I asked myself and my colleagues what our responsibility in developing these algorithms was and in having some say in how they’re being used down the line.
Gizmodo: How is it going so far?
BN: Currently, we’re going to write a white paper for SNOWMASS, this high-energy physics event. The SNOWMASS process determines the vision that guides the community for about a decade. I started to identify individuals to work with, fellow physicists, and experts who care about the issues, and develop a set of arguments for why physicists from institutions, individuals, and funding agencies should care deeply about these algorithms they’re building and implementing so quickly. It’s a piece that’s asking people to think about how much they are considering the ethical implications of what they’re doing.
We’ve already held a workshop at the University of Chicago where we’ve begun discussing these issues, and at Fermilab we’ve had some initial discussions. But we don’t yet have the critical mass across the field to develop policy. We can’t do it ourselves as physicists; we don’t have backgrounds in social science or technology studies. The right way to do this is to bring physicists together from Fermilab and other institutions with social scientists and ethicists and science and technology studies folks and professionals, and build something from there. The key is going to be through partnership with these other disciplines.
Gizmodo: Why haven’t we reached that critical mass yet?
BN: I think we need to show people, as Angela Davis has said, that our struggle is also their struggle. That’s why I’m talking about coalition building. The thing that affects us also affects them. One way to do this is to clearly lay out the potential harm beyond just race and ethnicity. Recently, there was this discussion of a paper that used neural networks to try and speed up the selection of candidates for Ph.D programs. They trained the algorithm on historical data. So let me be clear, they said here’s a neural network, here’s data on applicants who were denied and accepted to universities. Those applicants were chosen by faculty and people with biases. It should be obvious to anyone developing that algorithm that you’re going to bake in the biases in that context. I hope people will see these things as problems and help build our coalition.
Gizmodo: What is your vision for a future of ethical AI?
BN: What if there were an agency or agencies for algorithmic accountability? I could see these existing at the local level, the national level, and the institutional level. We can’t predict all of the future uses of technology, but we need to be asking questions at the beginning of the processes, not as an afterthought. An agency would help ask these questions and still allow the science to get done, but without endangering people’s lives. Alongside agencies, we need policies at various levels that make a clear decision about how safe the algorithms have to be before they are used on humans or other living things. If I had my druthers, these agencies and policies would be built by an incredibly diverse group of people. We’ve seen instances where a homogeneous group develops an app or technology and didn’t see the things that another group who’s not there would have seen. We need people across the spectrum of experience to participate in designing policies for ethical AI.
Gizmodo: What are your biggest fears about all of this?
BN: My biggest fear is that people who already have access to technology resources will continue to use them to subjugate people who are already oppressed; Pratyusha Kalluri has also advanced this idea of power dynamics. That’s what we’re seeing across the globe. Sure, there are cities that are trying to ban facial recognition, but unless we have a broader coalition, unless we have more cities and institutions willing to take on this thing directly, we’re not going to be able to keep this tool from exacerbating white supremacy, racism, and misogyny that that already exists inside structures today. If we don’t push policy that puts the lives of marginalized people first, then they’re going to continue being oppressed, and it’s going to accelerate.
Gizmodo: How has thinking about AI ethics affected your own research?
BN: I have to question whether I want to do AI work and how I’m going to do it; whether or not it’s the right thing to do to build a certain algorithm. That’s something I have to keep asking myself… Before, it was like, how fast can I discover new things and build technology that can help the world learn something? Now there’s a significant piece of nuance to that. Even the best things for humanity could be used in some of the worst ways. It’s a fundamental rethinking of the order of operations when it comes to my research.
I don’t think it’s weird to think about safety first. We have OSHA and safety groups at institutions who write down lists of things you have to check off before you’re allowed to take out a ladder, for example. Why are we not doing the same thing in AI? A part of the answer is obvious: Not all of us are people who experience the negative effects of these algorithms. But as one of the few Black people at the institutions I work in, I’m aware of it, I’m worried about it, and the scientific community needs to appreciate that my safety matters too, and that my safety concerns don’t end when I walk out of work.
Gizmodo: Anything else?
BN: I’d like to re-emphasize that when you look at some of the research that has come out, like vetting candidates for graduate school, or when you look at the biases of the algorithms used in criminal justice, these are problems being repeated over and over again, with the same biases. It doesn’t take a lot of investigation to see that bias enters these algorithms very quickly. The people developing them should really know better. Maybe there needs to be more educational requirements for algorithm developers to think about these issues before they have the opportunity to unleash them on the world.
This conversation needs to be raised to the level where individuals and institutions consider these issues a priority. Once you’re there, you need people to see that this is an opportunity for leadership. If we can get a grassroots community to help an institution to take the lead on this, it incentivizes a lot of people to start to take action.
And finally, people who have expertise in these areas need to be allowed to speak their minds. We can’t allow our institutions to quiet us so we can’t talk about the issues we’re bringing up. The fact that I have experience as a Black man doing science in America, and the fact that I do AI—that should be appreciated by institutions. It gives them an opportunity to have a unique perspective and take a unique leadership position. I would be worried if individuals felt like they couldn’t speak their mind. If we can’t get these issues out into the sunlight, how will we be able to build out of the darkness?
Ryan F. Mandelbaum – Former Gizmodo physics writer and founder of Birdmodo, now a science communicator specializing in quantum computing and birds
Introduction: Sensors everywhere. Infinite storage. Clouds of processors. Our ability to capture, warehouse, and understand massive amounts of data is changing science, medicine, business, and technology. As our collection of facts and figures grows, so will the opportunity to find answers to fundamental questions. Because in the era of big data, more isn’t just more. […]
Marian Bantjes
Introduction:
Sensors everywhere. Infinite storage. Clouds of processors. Our ability to capture, warehouse, and understand massive amounts of data is changing science, medicine, business, and technology. As our collection of facts and figures grows, so will the opportunity to find answers to fundamental questions. Because in the era of big data, more isn’t just more. More is different.
Does big data have the answers? Maybe some, but not all, says Mark Graham
In 2008, Chris Anderson, then editor of Wired, wrote a provocative piece titled The End of Theory. Anderson was referring to the ways that computers, algorithms, and big data can potentially generate more insightful, useful, accurate, or true results than specialists or domain experts who traditionally craft carefully targeted hypotheses and research strategies.
This revolutionary notion has now entered not just the popular imagination, but also the research practices of corporations, states, journalists and academics. The idea being that the data shadows and information trails of people, machines, commodities and even nature can reveal secrets to us that we now have the power and prowess to uncover.
In other words, we no longer need to speculate and hypothesise; we simply need to let machines lead us to the patterns, trends, and relationships in social, economic, political, and environmental relationships.
It is quite likely that you yourself have been the unwitting subject of a big data experiment carried out by Google, Facebook and many other large Web platforms. Google, for instance, has been able to collect extraordinary insights into what specific colours, layouts, rankings, and designs make people more efficient searchers. They do this by slightly tweaking their results and website for a few million searches at a time and then examining the often subtle ways in which people react.
Most large retailers similarly analyse enormous quantities of data from their databases of sales (which are linked to you by credit card numbers and loyalty cards) in order to make uncanny predictions about your future behaviours. In a now famous case, the American retailer, Target, upset a Minneapolis man by knowing more about his teenage daughter’s sex life than he did. Target was able to predict his daughter’s pregnancy by monitoring her shopping patterns and comparing that information to an enormous database detailing billions of dollars of sales. This ultimately allows the company to make uncanny predictions about its shoppers.
More significantly, national intelligence agencies are mining vast quantities of non-public Internet data to look for weak signals that might indicate planned threats or attacks.
There can by no denying the significant power and potentials of big data. And the huge resources being invested in both the public and private sectors to study it are a testament to this.
However, crucially important caveats are needed when using such datasets: caveats that, worryingly, seem to be frequently overlooked.
The raw informational material for big data projects is often derived from large user-generated or social media platforms (e.g. Twitter or Wikipedia). Yet, in all such cases we are necessarily only relying on information generated by an incredibly biased or skewed user-base.
Gender, geography, race, income, and a range of other social and economic factors all play a role in how information is produced and reproduced. People from different places and different backgrounds tend to produce different sorts of information. And so we risk ignoring a lot of important nuance if relying on big data as a social/economic/political mirror.
We can of course account for such bias by segmenting our data. Take the case of using Twitter to gain insights into last summer’s London riots. About a third of all UK Internet users have a twitter profile; a subset of that group are the active tweeters who produce the bulk of content; and then a tiny subset of that group (about 1%) geocode their tweets (essential information if you want to know about where your information is coming from).
Despite the fact that we have a database of tens of millions of data points, we are necessarily working with subsets of subsets of subsets. Big data no longer seems so big. Such data thus serves to amplify the information produced by a small minority (a point repeatedly made by UCL’s Muki Haklay), and skew, or even render invisible, ideas, trends, people, and patterns that aren’t mirrored or represented in the datasets that we work with.
Big data is undoubtedly useful for addressing and overcoming many important issues face by society. But we need to ensure that we aren’t seduced by the promises of big data to render theory unnecessary.
We may one day get to the point where sufficient quantities of big data can be harvested to answer all of the social questions that most concern us. I doubt it though. There will always be digital divides; always be uneven data shadows; and always be biases in how information and technology are used and produced.
And so we shouldn’t forget the important role of specialists to contextualise and offer insights into what our data do, and maybe more importantly, don’t tell us.
Illustration: Marian Bantjes“All models are wrong, but some are useful.”
So proclaimed statistician George Box 30 years ago, and he was right. But what choice did we have? Only models, from cosmological equations to theories of human behavior, seemed to be able to consistently, if imperfectly, explain the world around us. Until now. Today companies like Google, which have grown up in an era of massively abundant data, don’t have to settle for wrong models. Indeed, they don’t have to settle for models at all.
Sixty years ago, digital computers made information readable. Twenty years ago, the Internet made it reachable. Ten years ago, the first search engine crawlers made it a single database. Now Google and like-minded companies are sifting through the most measured age in history, treating this massive corpus as a laboratory of the human condition. They are the children of the Petabyte Age.
The Petabyte Age is different because more is different. Kilobytes were stored on floppy disks. Megabytes were stored on hard disks. Terabytes were stored in disk arrays. Petabytes are stored in the cloud. As we moved along that progression, we went from the folder analogy to the file cabinet analogy to the library analogy to — well, at petabytes we ran out of organizational analogies.
At the petabyte scale, information is not a matter of simple three- and four-dimensional taxonomy and order but of dimensionally agnostic statistics. It calls for an entirely different approach, one that requires us to lose the tether of data as something that can be visualized in its totality. It forces us to view data mathematically first and establish a context for it later. For instance, Google conquered the advertising world with nothing more than applied mathematics. It didn’t pretend to know anything about the culture and conventions of advertising — it just assumed that better data, with better analytical tools, would win the day. And Google was right.
Google’s founding philosophy is that we don’t know why this page is better than that one: If the statistics of incoming links say it is, that’s good enough. No semantic or causal analysis is required. That’s why Google can translate languages without actually “knowing” them (given equal corpus data, Google can translate Klingon into Farsi as easily as it can translate French into German). And why it can match ads to content without any knowledge or assumptions about the ads or the content.
Speaking at the O’Reilly Emerging Technology Conference this past March, Peter Norvig, Google’s research director, offered an update to George Box’s maxim: “All models are wrong, and increasingly you can succeed without them.”
This is a world where massive amounts of data and applied mathematics replace every other tool that might be brought to bear. Out with every theory of human behavior, from linguistics to sociology. Forget taxonomy, ontology, and psychology. Who knows why people do what they do? The point is they do it, and we can track and measure it with unprecedented fidelity. With enough data, the numbers speak for themselves.
The big target here isn’t advertising, though. It’s science. The scientific method is built around testable hypotheses. These models, for the most part, are systems visualized in the minds of scientists. The models are then tested, and experiments confirm or falsify theoretical models of how the world works. This is the way science has worked for hundreds of years.
Scientists are trained to recognize that correlation is not causation, that no conclusions should be drawn simply on the basis of correlation between X and Y (it could just be a coincidence). Instead, you must understand the underlying mechanisms that connect the two. Once you have a model, you can connect the data sets with confidence. Data without a model is just noise.
But faced with massive data, this approach to science — hypothesize, model, test — is becoming obsolete. Consider physics: Newtonian models were crude approximations of the truth (wrong at the atomic level, but still useful). A hundred years ago, statistically based quantum mechanics offered a better picture — but quantum mechanics is yet another model, and as such it, too, is flawed, no doubt a caricature of a more complex underlying reality. The reason physics has drifted into theoretical speculation about n-dimensional grand unified models over the past few decades (the “beautiful story” phase of a discipline starved of data) is that we don’t know how to run the experiments that would falsify the hypotheses — the energies are too high, the accelerators too expensive, and so on.
Now biology is heading in the same direction. The models we were taught in school about “dominant” and “recessive” genes steering a strictly Mendelian process have turned out to be an even greater simplification of reality than Newton’s laws. The discovery of gene-protein interactions and other aspects of epigenetics has challenged the view of DNA as destiny and even introduced evidence that environment can influence inheritable traits, something once considered a genetic impossibility.
In short, the more we learn about biology, the further we find ourselves from a model that can explain it.
There is now a better way. Petabytes allow us to say: “Correlation is enough.” We can stop looking for models. We can analyze the data without hypotheses about what it might show. We can throw the numbers into the biggest computing clusters the world has ever seen and let statistical algorithms find patterns where science cannot.
The best practical example of this is the shotgun gene sequencing by J. Craig Venter. Enabled by high-speed sequencers and supercomputers that statistically analyze the data they produce, Venter went from sequencing individual organisms to sequencing entire ecosystems. In 2003, he started sequencing much of the ocean, retracing the voyage of Captain Cook. And in 2005 he started sequencing the air. In the process, he discovered thousands of previously unknown species of bacteria and other life-forms.
If the words “discover a new species” call to mind Darwin and drawings of finches, you may be stuck in the old way of doing science. Venter can tell you almost nothing about the species he found. He doesn’t know what they look like, how they live, or much of anything else about their morphology. He doesn’t even have their entire genome. All he has is a statistical blip — a unique sequence that, being unlike any other sequence in the database, must represent a new species.
This sequence may correlate with other sequences that resemble those of species we do know more about. In that case, Venter can make some guesses about the animals — that they convert sunlight into energy in a particular way, or that they descended from a common ancestor. But besides that, he has no better model of this species than Google has of your MySpace page. It’s just data. By analyzing it with Google-quality computing resources, though, Venter has advanced biology more than anyone else of his generation.
This kind of thinking is poised to go mainstream. In February, the National Science Foundation announced the Cluster Exploratory, a program that funds research designed to run on a large-scale distributed computing platform developed by Google and IBM in conjunction with six pilot universities. The cluster will consist of 1,600 processors, several terabytes of memory, and hundreds of terabytes of storage, along with the software, including IBM’s Tivoli and open source versions of Google File System and MapReduce.111 Early CluE projects will include simulations of the brain and the nervous system and other biological research that lies somewhere between wetware and software.
Learning to use a “computer” of this scale may be challenging. But the opportunity is great: The new availability of huge amounts of data, along with the statistical tools to crunch these numbers, offers a whole new way of understanding the world. Correlation supersedes causation, and science can advance even without coherent models, unified theories, or really any mechanistic explanation at all.
There’s no reason to cling to our old ways. It’s time to ask: What can science learn from Google?
Until recently, the field of plant breeding looked a lot like it did in centuries past. A breeder might examine, for example, which tomato plants were most resistant to drought and then cross the most promising plants to produce the most drought-resistant offspring. This process would be repeated, plant generation after generation, until, over the course of roughly seven years, the breeder arrived at what seemed the optimal variety.
Researchers at ETH Zürich use standard color images and thermal images collected by drone to determine how plots of wheat with different genotypes vary in grain ripeness. Image credit: Norbert Kirchgessner (ETH Zürich, Zürich, Switzerland).
Now, with the global population expected to swell to nearly 10 billion by 2050 (1) and climate change shifting growing conditions (2), crop breeder and geneticist Steven Tanksley doesn’t think plant breeders have that kind of time. “We have to double the productivity per acre of our major crops if we’re going to stay on par with the world’s needs,” says Tanksley, a professor emeritus at Cornell University in Ithaca, NY.
To speed up the process, Tanksley and others are turning to artificial intelligence (AI). Using computer science techniques, breeders can rapidly assess which plants grow the fastest in a particular climate, which genes help plants thrive there, and which plants, when crossed, produce an optimum combination of genes for a given location, opting for traits that boost yield and stave off the effects of a changing climate. Large seed companies in particular have been using components of AI for more than a decade. With computing power rapidly advancing, the techniques are now poised to accelerate breeding on a broader scale.
AI is not, however, a panacea. Crop breeders still grapple with tradeoffs such as higher yield versus marketable appearance. And even the most sophisticated AI cannot guarantee the success of a new variety. But as AI becomes integrated into agriculture, some crop researchers envisage an agricultural revolution with computer science at the helm.
An Art and a Science
During the “green revolution” of the 1960s, researchers developed new chemical pesticides and fertilizers along with high-yielding crop varieties that dramatically increased agricultural output (3). But the reliance on chemicals came with the heavy cost of environmental degradation (4). “If we’re going to do this sustainably,” says Tanksley, “genetics is going to carry the bulk of the load.”
Plant breeders lean not only on genetics but also on mathematics. As the genomics revolution unfolded in the early 2000s, plant breeders found themselves inundated with genomic data that traditional statistical techniques couldn’t wrangle (5). Plant breeding “wasn’t geared toward dealing with large amounts of data and making precise decisions,” says Tanksley.
In 1997, Tanksley began chairing a committee at Cornell that aimed to incorporate data-driven research into the life sciences. There, he encountered an engineering approach called operations research that translates data into decisions. In 2006, Tanksley cofounded the Ithaca, NY-based company Nature Source Improved Plants on the principle that this engineering tool could make breeding decisions more efficient. “What we’ve been doing almost 15 years now,” says Tanksley, “is redoing how breeding is approached.”
A Manufacturing Process
Such approaches try to tackle complex scenarios. Suppose, for example, a wheat breeder has 200 genetically distinct lines. The breeder must decide which lines to breed together to optimize yield, disease resistance, protein content, and other traits. The breeder may know which genes confer which traits, but it’s difficult to decipher which lines to cross in what order to achieve the optimum gene combination. The number of possible combinations, says Tanksley, “is more than the stars in the universe.”
An operations research approach enables a researcher to solve this puzzle by defining the primary objective and then using optimization algorithms to predict the quickest path to that objective given the relevant constraints. Auto manufacturers, for example, optimize production given the expense of employees, the cost of auto parts, and fluctuating global currencies. Tanksley’s team optimizes yield while selecting for traits such as resistance to a changing climate. “We’ve seen more erratic climate from year to year, which means you have to have crops that are more robust to different kinds of changes,” he says.
For each plant line included in a pool of possible crosses, Tanksley inputs DNA sequence data, phenotypic data on traits like drought tolerance, disease resistance, and yield, as well as environmental data for the region where the plant line was originally developed. The algorithm projects which genes are associated with which traits under which environmental conditions and then determines the optimal combination of genes for a specific breeding goal, such as drought tolerance in a particular growing region, while accounting for genes that help boost yield. The algorithm also determines which plant lines to cross together in which order to achieve the optimal combination of genes in the fewest generations.
Nature Source Improved Plants conducts, for example, a papaya program in southeastern Mexico where the once predictable monsoon season has become erratic. “We are selecting for varieties that can produce under those unknown circumstances,” says Tanksley. But the new papaya must also stand up to ringspot, a virus that nearly wiped papaya from Hawaii altogether before another Cornell breeder developed a resistant transgenic variety (6). Tanksley’s papaya isn’t as disease resistant. But by plugging “rapid growth rate” into their operations research approach, the team bred papaya trees that produce copious fruit within a year, before the virus accumulates in the plant.
“Plant breeders need operations research to help them make better decisions,” says William Beavis, a plant geneticist and computational biologist at Iowa State in Ames, who also develops operations research strategies for plant breeding. To feed the world in rapidly changing environments, researchers need to shorten the process of developing a new cultivar to three years, Beavis adds.
The big seed companies have investigated use of operations research since around 2010, with Syngenta, headquartered in Basel, Switzerland, leading the pack, says Beavis, who spent over a decade as a statistical geneticist at Pioneer Hi-Bred in Johnston, IA, a large seed company now owned by Corteva, which is headquartered in Wilmington, DE. “All of the soybean varieties that have come on the market within the last couple of years from Syngenta came out of a system that had been redesigned using operations research approaches,” he says. But large seed companies primarily focus on grains key to animal feed such as corn, wheat, and soy. To meet growing food demands, Beavis believes that the smaller seed companies that develop vegetable crops that people actually eat must also embrace operations research. “That’s where operations research is going to have the biggest impact,” he says, “local breeding companies that are producing for regional environments, not for broad adaptation.”
In collaboration with Iowa State colleague and engineer Lizhi Wang and others, Beavis is developing operations research-based algorithms to, for example, help seed companies choose whether to breed one variety that can survive in a range of different future growing conditions or a number of varieties, each tailored to specific environments. Two large seed companies, Corteva and Syngenta, and Kromite, a Lambertville, NJ-based consulting company, are partners on the project. The results will be made publicly available so that all seed companies can learn from their approach.
Nature Source Improved Plants (NSIP) speeds up its papaya breeding program in southeastern Mexico by using decision-making approaches more common in engineering. Image credit: Nature Source Improved Plants/Jesús Morales.
Drones and Adaptations
Useful farming AI requires good data, and plenty of it. To collect sufficient inputs, some researchers take to the skies. Crop researcher Achim Walter of the Institute of Agricultural Sciences at ETH Zürich in Switzerland and his team are developing techniques to capture aerial crop images. Every other day for several years, they have deployed image-capturing sensors over a wheat field containing hundreds of genetic lines. They fly their sensors on drones or on cables suspended above the crops or incorporate them into handheld devices that a researcher can use from an elevated platform (7).
Meanwhile, they’re developing imaging software that quantifies growth rate captured by these images (8). Using these data, they build models that predict how quickly different genetic lines grow under different weather conditions. If they find, for example, that a subset of wheat lines grew well despite a dry spell, then they can zero in on the genes those lines have in common and incorporate them into new drought-resistant varieties.
Research geneticist Edward Buckler at the US Department of Agriculture and his team are using machine learning to identify climate adaptations in 1,000 species in a large grouping of grasses spread across the globe. The grasses include food and bioenergy crops such as maize, sorghum, and sugar cane. Buckler says that when people rank what are the most photosynthetically efficient and water-efficient species, this is the group that comes out at the top. Still, he and collaborators, including plant scientist Elizabeth Kellogg of the Donald Danforth Plant Science Center in St. Louis, MO, and computational biologist Adam Siepel of Cold Spring Harbor Laboratory in NY, want to uncover genes that could make crops in this group even more efficient for food production in current and future environments. The team is first studying a select number of model species to determine which genes are expressed under a range of different environmental conditions. They’re still probing just how far this predictive power can go.
Such approaches could be scaled up—massively. To probe the genetic underpinnings of climate adaptation for crop species worldwide, Daniel Jacobson, the chief researcher for computational systems biology at Oak Ridge National Laboratory in TN, has amassed “climatype” data for every square kilometer of land on Earth. Using the Summit supercomputer, they then compared each square kilometer to every other square kilometer to identify similar environments (9). The result can be viewed as a network of GPS points connected by lines that show the degree of environmental similarity between points.
“For me, breeding is much more like art. I need to see the variation and I don’t prejudge it. I know what I’m after, but nature throws me curveballs all the time, and I probably can’t count the varieties that came from curveballs.”
—Molly Jahn
In collaboration with the US Department of Energy’s Center for Bioenergy Innovation, the team combines this climatype data with GPS coordinates associated with individual crop genotypes to project which genes and genetic interactions are associated with specific climate conditions. Right now, they’re focused on bioenergy and feedstocks, but they’re poised to explore a wide range of food crops as well. The results will be published so that other researchers can conduct similar analyses.
The Next Agricultural Revolution
Despite these advances, the transition to AI can be unnerving. Operations research can project an ideal combination of genes, but those genes may interact in unpredictable ways. Tanksley’s company hedges its bets by engineering 10 varieties for a given project in hopes that at least one will succeed.
On the other hand, such a directed approach could miss happy accidents, says Molly Jahn, a geneticist and plant breeder at the University of Wisconsin–Madison. “For me, breeding is much more like art. I need to see the variation and I don’t prejudge it,” she says. “I know what I’m after, but nature throws me curveballs all the time, and I probably can’t count the varieties that came from curveballs.”
There are also inherent tradeoffs that no algorithm can overcome. Consumers may prefer tomatoes with a leafy crown that stays green longer. But the price a breeder pays for that green calyx is one percent of the yield, says Tanksley.
Image recognition technology comes with its own host of challenges, says Walter. “To optimize algorithms to an extent that makes it possible to detect a certain trait, you have to train the algorithm thousands of times.” In practice, that means snapping thousands of crop images in a range of light conditions. Then there’s the ground-truthing. To know whether the models work, Walter and others must measure the trait they’re after by hand. Keen to know whether the model accurately captures the number of kernels on an ear of corn? You’d have to count the kernels yourself.
Despite these hurdles, Walter believes that computer science has brought us to the brink of a new agricultural revolution. In a 2017 PNAS Opinion piece, Walter and colleagues described emerging “smart farming” technologies—from autonomous weeding vehicles to moisture sensors in the soil (10). The authors worried, though, that only big industrial farms can afford these solutions. To make agriculture more sustainable, smaller farms in developing countries must have access as well.
Fortunately, “smart breeding” advances may have wider reach. Once image recognition technology becomes more developed for crops, which Walter expects will happen within the next 10 years, deploying it may be relatively inexpensive. Breeders could operate their own drones and obtain more precise ratings of traits like time to flowering or number of fruits in shorter time, says Walter. “The computing power that you need once you have established the algorithms is not very high.”
The genomic data so vital to AI-led breeding programs is also becoming more accessible. “We’re really at this point where genomics is cheap enough that you can apply these technologies to hundreds of species, maybe thousands,” says Buckler.
Plant breeding has “entered the engineered phase,” adds Tanksley. And with little time to spare. “The environment is changing,” he says. “You have to have a faster breeding process to respond to that.”
1. United Nations, Department of Economic and Social Affairs, Population Division, World Population Prospects 2019: Highlights, (United Nations, New York, 2019).
3. P. L. Pingali, Green revolution: Impacts, limits, and the path ahead. Proc. Natl. Acad. Sci. U.S.A. 109, 12302–12308 (2012).
4. D. Tilman, The greening of the green revolution. Nature 396, 211–212 (1998).
5. G. P. Ramstein, S. E. Jensen, E. S. Buckler, Breaking the curse of dimensionality to identify causal variants in Breeding 4. Theor. Appl. Genet. 132, 559–567 (2019).
6. D. Gonsalves, Control of papaya ringspot virus in papaya: A case study. Annu. Rev. Phytopathol. 36, 415–437 (1998).
7. N. Kirchgessner et al., The ETH field phenotyping platform FIP: A cable-suspended multi-sensor system. Funct. Plant Biol. 44, 154–168 (2016).
8. K. Yu, N. Kirchgessner, C. Grieder, A. Walter, A. Hund, An image analysis pipeline for automated classification of imaging light conditions and for quantification of wheat canopy cover time series in field phenotyping. Plant Methods 13, 15 (2017).
9. J. Streich et al., Can exascale computing and explainable artificial intelligence applied to plant biology deliver on the United Nations sustainable development goals? Curr. Opin. Biotechnol. 61, 217–225 (2020).
10. A. Walter, R. Finger, R. Huber, N. Buchmann, Opinion: Smart farming is key to developing sustainable agriculture. Proc. Natl. Acad. Sci. U.S.A. 114, 6148–6150 (2017).
Antes encaradas com desconfiança pela comunidade científica, as metodologias de intervenção artificial no meio ambiente com o objetivo de frear os efeitos devastadores do aquecimento global estão sendo consideradas agora como recursos a serem aplicados em última instância (já que iniciativas para reduzir a emissão de gases dependem diretamente da ação coletiva e demandam décadas para que tenham algum tipo de efeito benéfico). É possível que não tenhamos esse tempo, de acordo com alguns pesquisadores da área, os quais têm atraído investimentos e muita atenção.
Fazendo parte de um campo também referenciado como geoengenharia solar, grande parte dos métodos se vale da emissão controlada de partículas na atmosfera, responsáveis por barrar a energia recebida pelo nosso planeta e direcioná-la novamente ao espaço, criando uma espécie de resfriamento semelhante ao gerado por erupções vulcânicas.
Ainda que não atuem sobre a poluição, por exemplo, cientistas consideram que, diante de tempestades cada vez mais agressivas, tornados de fogo, inundações e outros desastres naturais, tais ações seriam interessantes enquanto soluções mais eficazes não são desenvolvidas.
Diretor do Sabin Center for Climate Change Law, na Columbia Law School, e editor de um livro sobre a tecnologia e suas implicações legais, Michael Gerrard exemplificou a situação em entrevista ao The New York Times: “Estamos enfrentando uma ameaça existencial. Por isso, é necessário que analisemos todas as opções”.
“Gosto de comparar a geoengenharia a uma quimioterapia para o planeta: se todo o resto estiver falhando, resta apenas tentar”, ele defendeu.
Desastres naturais ocasionados pelo aquecimento global tornam urgente a ação de intervenções, segundo pesquisadores. Fonte: Unsplash
Dois pesos e duas medidas
Entre aquelas que se destacam, pode ser citada a ação empreendida por uma organização não governamental chamada SilverLining, que concedeu US$ 3 milhões a diversas universidades e outras instituições para que se dediquem à busca de respostas para questões práticas. Um exemplo é encontrar a altitude ideal para a aplicação de aerossóis e como inserir a quantidade mais indicada, verificando seus efeitos sobre a cadeia de produção de alimentos mundial.
Chris Sacca, cofundador da Lowercarbon Capital, um grupo de investimentos que é um dos financiadores da SilverLining, declarou em tom alarmista: “A descarbonização é necessária, mas vai demorar 20 anos ou mais para que ocorra. Se não explorarmos intervenções climáticas como a reflexão solar neste momento, condenaremos um número incontável de vidas, espécies e ecossistemas ao calor”.
Outra contemplada por somas substanciais foi a National Oceanic and Atmospheric Administration, que recebeu do congresso norte-americano US$ 4 milhões justamente para o desenvolvimento de tecnologias do tipo, assim como o monitoramento de uso secreto de tais soluções por outros países.
Douglas MacMartin, pesquisador de Engenharia Mecânica e aeroespacial na Universidade Cornell, afirmou que “é certo o poder da humanidade de resfriar as coisas, mas o que não está claro é o que vem a seguir”.
Se, por um lado, o planeta pode ser resfriado artificialmente; por outro, não se sabe o que virá. Fonte: Unsplash
Existe uma maneira
Para esclarecer as possíveis consequências de intervenções dessa magnitude, MacMartin desenvolverá modelos de efeitos climáticos específicos oriundos da injeção de aerossóis na atmosfera acima de diferentes partes do globo e altitudes. “Dependendo de onde você colocar [a substância], terá efeitos diferentes nas monções na Ásia e no gelo marinho do Ártico“, ele apontou.
O Centro Nacional de Pesquisa Atmosférica em Boulder, Colorado, financiado também pela SilverLining, acredita ter o sistema ideal para isso — o qual é considerado o mais sofisticado do mundo. Com ele, serão executadas centenas de simulações e, assim, especialistas procurarão o que chamam de ponto ideal, no qual a quantidade de resfriamento artificial que pode reduzir eventos climáticos extremos não cause mudanças mais amplas nos padrões regionais de precipitação ou impactos semelhantes.
“Existe uma maneira, pelo menos em nosso modelo de mundo, de ver se podemos alcançar um sem acionar demais o outro?” questionou Jean-François Lamarque, diretor do laboratório de Clima e Dinâmica Global da instituição. Ainda não há resposta para essa dúvida, mas soluções sustentáveis estão sendo analisadas por pesquisadores australianos, que utilizariam a emissão de água salgada para tornar nuvens mais reflexivas, assim indicando resultados promissores de testes.
Dessa maneira, quem sabe as perdas de corais de recife que testemunhamos tenham data para acabar. Quanto ao resto, bem, só o tempo mostrará.
Existem muitas críticas à esses sistemas, algumas justas outras nem tanto; o fato é que personalização, curadoria, clusterização, mecanismos de persuasão, nada disso é novo, cabe é investigar o que mudou com a IA (Foto: Thinkstock)
Os algoritmos de inteligência artificial (IA) atuam como curadores da informação, personalizando, por exemplo, as respostas nas plataformas de busca como Google e a seleção do que será publicado no feed de notícias de cada usuário do Facebook. O ativista Eli Pariser (The Filtre Bubble, 2011) reconhece a utilidade de sistemas de relevância ao fornecer conteúdo personalizado, mas alerta para os efeitos negativos da formação de “bolhas” ao reduzir a exposição à opiniões divergentes. Para Cass Sunstein (#republic, 2017), esses sistemas são responsáveis pelo aumento da polarização cultural e política pondo em risco a democracia. Existem muitas críticas à esses sistemas, algumas justas outras nem tanto; o fato é que personalização, curadoria, clusterização, mecanismos de persuasão, nada disso é novo, cabe é investigar o que mudou com a IA.
A personalização do discurso, por exemplo, remete à Aristóteles. A arte de conhecer o ouvinte e adaptar o discurso ao seu perfil, não para convencê-lo racionalmente, mas para conquistá-lo pelo “coração” é o tema da obra “Retórica”. Composta de três volumes, o Livro II é dedicado ao plano emocional listando as emoções que devem conter um discurso persuasivo: ira, calma, amizade, inimizade, temor, confiança, vergonha, desvergonha, amabilidade, piedade, indignação, inveja e emulação. Para o filósofo, todos, de algum modo, praticam a retórica na sustentação de seus argumentos. Essa obra funda as bases da retórica ocidental que, com seus mecanismos de persuasão, busca influenciar o interlocutor seja ele usuário, consumidor, cliente ou eleitor.
Cada modelo econômico tem seus próprios mecanismos de persuasão, que extrapolam motivações comerciais com impactos culturais e comportamentais. Na Economia Industrial, caracterizada pela produção e pelo consumo massivo de bens e serviços, a propaganda predominou como meio de convencimento nas decisões dos consumidores, inicialmente tratados como uma “massa” de indivíduos indistinguíveis. O advento das tecnologias digitais viabilizou a comunicação segmentada em função de características, perfis e preferências similares, mas ainda distante da hipersegmentação proporcionada pelas tecnologias de IA.
A hipersegmentação com algoritmos de IA é baseada na mineração de grandes conjuntos de dados (Big Data) e sofisticadas técnicas de análise e previsão, particularmente os modelos estatísticos de redes neurais/deep learning. Esses modelos permitem extrair dos dados informações sobre seus usuários e/ou consumidores e fazer previsões com alto grau de acurácia – desejos, comportamentos, interesses, padrões de pesquisa, por onde circulam, bem como a capacidade de pagamento e até o estado de saúde. Os algoritmos de IA transformam em informação útil a imensidão de dados gerados nas movimentações online.
Na visão de Shoshana Zuboff (The Age of Surveillance Capitalism, 2019), a maior ameaça não está nos dados produzidos voluntariamente em nossas interações nos meios digitais (“dados consentidos”), mas nos “dados residuais” sob os quais os usuários de plataformas online não exercem controle. Até 2006, os dados residuais eram desprezados, com a sofisticação dos modelos preditivos de IA esses dados tornaram-se valiosos: a velocidade de digitalização, os erros gramaticais cometidos, o formato dos textos, as cores preferidas e mais uma infinidade de detalhes do comportamento dos usuários são registrados e inseridos na extensa base de dados gerando projeções assertivas sobre o comportamento humano atual e futuro. Outro aspecto ressaltado por Zuboff é que as plataformas tecnológicas, em geral, captam mais dados do que o necessário para a dinâmica de seus modelos de negócio, ou seja, para melhorar produtos e serviços, e os utilizam para prever o comportamento de grupos específicos (“excedente comportamental”).
Esses processos de persuasão ocorrem em níveis invisíveis, sem conhecimento e/ou consentimento dos usuários, que desconhecem o potencial e a abrangência das previsões dos algoritmos de IA; num nível mais avançado, essas previsões envolvem personalidade, emoções, orientação sexual e política, ou seja, um conjunto de informações que em tese não era a intenção do usuário revelar. As fotos postadas nas redes sociais, por exemplo, geram os chamados “sinais de previsão” tais como os músculos e a simetria da face, informações utilizadas no treinamento de algoritmos de IA de reconhecimento de imagem.
A escala atual de geração, armazenamento e mineração de dados, associada aos modelos assertivos de personalização, é um dos elementos-chave da mudança de natureza dos atuais mecanismos de persuasão. Comparando os modelos tradicionais com os de algoritmos de IA, é possível detectar a extensão dessa mudança: 1) de mensagens elaboradas com base em conhecimento do público-alvo superficial e limitado, a partir do entendimento das características generalistas das categorias, para mensagens elaboradas com base em conhecimento profundo e detalhado/minucioso do público-alvo, hipersegmentação e personalização; 2) de correlações entre variáveis determinadas pelo desenvolvedor do sistema para correlações entre variáveis determinadas automaticamente com base nos dados; 3) de limitados recursos para associar comportamentos offline e online para capacidade de capturar e armazenar dados de comportamento off-line e agregá-los aos dados capturados online formando uma base de dados única, mais completa, mais diversificada, mais precisa; 4) de mecanismos de persuasão visíveis (propaganda na mídia) e relativamente visíveis (propaganda na internet) para mecanismos de persuasão invisíveis; 5) de baixo grau de assertividade para alto grau de assertividade; 6) de instrumentos de medição/verificação dos resultados limitados para instrumentos de medição/verificação dos resultados precisos; 7) de capacidade preditiva limitada à tendências futuras para capacidade preditiva de cenários futuros e quando vão acontecer com grau de acurácia média em torno de 80-90%; e 8) de reduzida capacidade de distorcer imagem e voz para enorme capacidade de distorcer imagem e voz, as Deep Fakes.
Como sempre, cabe à sociedade encontrar um ponto de equilíbrio entre os benefícios e as ameaças da IA. No caso, entre a proteção aos direitos humanos civilizatórios e a inovação e o avanço tecnológico, e entre a curadoria da informação e a manipulação do consumo, do acesso à informação e dos processos democráticos.
*Dora Kaufman professora do TIDD PUC – SP, pós-doutora COPPE-UFRJ e TIDD PUC-SP, doutora ECA-USP com período na Université Paris – Sorbonne IV. Autora dos livros “O Despertar de Gulliver: os desafios das empresas nas redes digitais”, e “A inteligência artificial irá suplantar a inteligência humana?”. Professora convidada da Fundação Dom Cabral
One of the most consumed drugs in the US – and the most commonly taken analgesic worldwide – could be doing a lot more than simply taking the edge off your headache, new evidence suggests.
Acetaminophen, also known as paracetamol and sold widely under the brand names Tylenol and Panadol, also increases risk-taking, according to a new study that measured changes in people’s behaviour when under the influence of the common over-the-counter medication.
“Acetaminophen seems to make people feel less negative emotion when they consider risky activities – they just don’t feel as scared,” says neuroscientist Baldwin Way from The Ohio State University.
“With nearly 25 percent of the population in the US taking acetaminophen each week, reduced risk perceptions and increased risk-taking could have important effects on society.”
In a similar way, the new research suggests people’s affective ability to perceive and evaluate risks can be impaired when they take acetaminophen. While the effects might be slight, they’re definitely worth noting, given acetaminophen is the most common drug ingredient in America, found in over 600 different kinds of over-the-counter and prescription medicines.
In a series of experiments involving over 500 university students as participants, Way and his team measured how a single 1,000 mg dose of acetaminophen (the recommended maximum adult single dosage) randomly assigned to participants affected their risk-taking behaviour, compared against placebos randomly given to a control group.
In each of the experiments, participants had to pump up an uninflated balloon on a computer screen, with each single pump earning imaginary money. Their instructions were to earn as much imaginary money as possible by pumping the balloon as much as possible, but to make sure not to pop the balloon, in which case they would lose the money.
The results showed that the students who took acetaminophen engaged in significantly more risk-taking during the exercise, relative to the more cautious and conservative placebo group. On the whole, those on acetaminophen pumped (and burst) their balloons more than the controls.
“If you’re risk-averse, you may pump a few times and then decide to cash out because you don’t want the balloon to burst and lose your money,” Way says.
“But for those who are on acetaminophen, as the balloon gets bigger, we believe they have less anxiety and less negative emotion about how big the balloon is getting and the possibility of it bursting.”
In addition to the balloon simulation, participants also filled out surveys during two of the experiments, rating the level of risk they perceived in various hypothetical scenarios, such as betting a day’s income on a sporting event, bungee jumping off a tall bridge, or driving a car without a seatbelt.
In one of the surveys, acetaminophen consumption did appear to reduce perceived risk compared to the control group, although in another similar survey, the same effect wasn’t observed.
Overall, however, based on an average of results across the various tests, the team concludes that there is a significant relationship between taking acetaminophen and choosing more risk, even if the observed effect can be slight.
That said, they acknowledge the drug’s apparent effects on risk-taking behaviour could also be interpreted via other kinds of psychological processes, such as reduced anxiety, perhaps.
“It may be that as the balloon increases in size, those on placebo feel increasing amounts of anxiety about a potential burst,” the researchers explain.
“When the anxiety becomes too much, they end the trial. Acetaminophen may reduce this anxiety, thus leading to greater risk taking.”
Exploring such psychological alternative explanations for this phenomenon – as well as investigating the biological mechanisms responsible for acetaminophen’s effects on people’s choices in situations like this – should be addressed in future research, the team says.
While they’re at it, scientists no doubt will also have future opportunities to further investigate the role and efficacy of acetaminophen in pain relief more broadly, after studies in recent years found that in many medical scenarios, the drug can be ineffective at pain relief, and sometimes is no better than a placebo, in addition to inviting other kinds of health problems.
In light of what we’re finding out about acetaminophen, we might want to rethink some of that advice, Way says.
“Perhaps someone with mild COVID-19 symptoms may not think it is as risky to leave their house and meet with people if they’re taking acetaminophen,” Way says.
“We really need more research on the effects of acetaminophen and other over-the-counter drugs on the choices and risks we take.”
Humans are dismantling and disrupting natural ecosystems around the globe and changing Earth’s climate. Over the past 50 years, actions like farming, logging, hunting, development and global commerce have caused record losses of species on land and at sea. Animals, birds and reptiles are disappearing tens to hundreds of times faster than the natural rate of extinction over the past 10 million years.
Now the world is also contending with a global pandemic. In geographically remote regions such as the Brazilian Amazon, COVID-19 is devastating Indigenous populations, with tragic consequences for both Indigenous peoples and the lands they steward.
My research focuses on ecosystems and climate change from regional to global scales. In 2019, I worked with conservation biologist and strategist Eric Dinerstein and 17 colleagues to develop a road map for simultaneously averting a sixth mass extinction and reducing climate change by protecting half of Earth’s terrestrial, freshwater and marine realms by 2030. We called this plan “A Global Deal for Nature.”
Now we’ve released a follow-on called the “Global Safety Net” that identifies the exact regions on land that must be protected to achieve its goals. Our aim is for nations to pair it with the Paris Climate Agreement and use it as a dynamic tool to assess progress towards our comprehensive conservation targets.
Population size of terrestrial vertebrate species on the brink (i.e., with under 1,000 individuals). Most of these species are especially close to extinction because they consist of fewer than 250 individuals. In most cases, those few individuals are scattered through several small populations. Ceballos et al, 2020., CC BY
What to protect next
The Global Deal for Nature provided a framework for the milestones, targets and policies across terrestrial, freshwater and marine realms required to conserve the vast majority of life on Earth. Yet it didn’t specify where exactly these safeguards were needed. That’s where the new Global Safety Net comes in.
We analyzed unprotected terrestrial areas that, if protected, could sequester carbon and conserve biodiversity as effectively as the 15% of terrestrial areas that are currently protected. Through this analysis, we identified an additional 35% of unprotected lands for conservation, bringing the total percentage of protected nature to 50%.
By setting aside half of Earth’s lands for nature, nations can save our planet’s rich biodiversity, prevent future pandemics and meet the Paris climate target of keeping warming in this century below less than 2.7 degrees F (1.5 degrees C). To meet these goals, 20 countries must contribute disproportionately. Much of the responsibility falls to Russia, the U.S., Brazil, Indonesia, Canada, Australia and China. Why? Because these countries contain massive tracts of land needed to reach the dual goals of reducing climate change and saving biodiversity.
Supporting Indigenous communities
Indigenous peoples make up less than 5% of the total human population, yet they manage or have tenure rights over a quarter of the world’s land surface, representing close to 80% of our planet’s biodiversity. One of our key findings is that 37% of the proposed lands for increased protection overlap with Indigenous lands.
As the world edges closer towards a sixth mass extinction, Indigenous communities stand to lose the most. Forest loss, ecotourism and devastation wrought by climate change have already displaced Indigenous peoples from their traditional territories at unprecedented rates. Now one of the deadliest pandemics in recent history poses an even graver additional threat to Indigenous lives and livelihoods.
To address and alleviate human rights questions, social justice issues and conservation challenges, the Global Safety Net calls for better protection for Indigenous communities. We believe our goals are achievable by upholding existing land tenure rights, addressing Indigenous land claims, and carrying out supportive ecological management programs with indigenous peoples.
Tropical deforestation increases forest edges – areas where forests meet human habitats. These areas greatly increase the potential for contact between humans and animal vectors that serve as viral hosts.
The Global Safety Net’s policy milestones and targets would reduce the illegal wildlife trade and associated wildlife markets – two known sources of zoonotic diseases. Reducing contact zones between animals and humans can decrease the chances of future zoonotic spillovers from occurring.
Our framework also envisions the creation of a Pandemic Prevention Program, which would increase protections for natural habitats at high risk for human-animal interactions. Protecting wildlife in these areas could also reduce the potential for more catastrophic outbreaks.
Nature-based solutions
Achieving the Global Safety Net’s goals will require nature-based solutions – strategies that protect, manage and restore natural or modified ecosystems while providing co-benefits to both people and nature. They are low-cost and readily available today.
The nature-based solutions that we spotlight include: – Identifying biodiverse non-agricultural lands, particularly prevalent in tropical and sub-tropical regions, for increased conservation attention. – Prioritizing ecoregions that optimize carbon storage and drawdown, such as the Amazon and Congo basins. – Aiding species movement and adaptation across ecosystems by creating a comprehensive system of wildlife and climate corridors.
We estimate that an increase of just 2.3% more land in the right places could save our planet’s rarest plant and animal species within five years. Wildlife corridors connect fragmented wild spaces, providing wild animals the space they need to survive.
Leveraging technology for conservation
In the Global Safety Net study, we identified 50 ecoregions where additional conservation attention is most needed to meet the Global Deal for Nature’s targets, and 20 countries that must assume greater responsibility for protecting critical places. We mapped an additional 35% of terrestrial lands that play a critical role in reversing biodiversity loss, enhancing natural carbon removal and preventing further greenhouse gas emissions from land conversion.
But as climate change accelerates, it may scramble those priorities. Staying ahead of the game will require a satellite-driven monitoring system with the capability of tracking real-time land use changes on a global scale. These continuously updated maps would enable dynamic analyses to help sharpen conservation planning and help decision-making.
As director of the Arizona State University Center for Global Discovery and Conservation Science, I lead the development of new technologies that assess and monitor imminent ecological threats, such as coral reef bleaching events and illegal deforestation, as well as progress made toward responding to ecological emergencies. Along with colleagues from other research institutions who are advancing this kind of research, I’m confident that it is possible to develop a global nature monitoring program.
The Global Safety Net pinpoints locations around the globe that must be protected to slow climate change and species loss. And the science shows that there is no time to lose.
Earlier this summer, the Summit supercomputer at Oak Ridge National Lab in Tennessee set about crunching data on more than 40,000 genes from 17,000 genetic samples in an effort to better understand Covid-19. Summit is the second-fastest computer in the world, but the process — which involved analyzing 2.5 billion genetic combinations — still took more than a week.
When Summit was done, researchers analyzed the results. It was, in the words of Dr. Daniel Jacobson, lead researcher and chief scientist for computational systems biology at Oak Ridge, a “eureka moment.” The computer had revealed a new theory about how Covid-19 impacts the body: the bradykinin hypothesis. The hypothesis provides a model that explains many aspects of Covid-19, including some of its most bizarre symptoms. It also suggests 10-plus potential treatments, many of which are already FDA approved. Jacobson’s group published their results in a paper in the journal eLife in early July.
According to the team’s findings, a Covid-19 infection generally begins when the virus enters the body through ACE2 receptors in the nose, (The receptors, which the virus is known to target, are abundant there.) The virus then proceeds through the body, entering cells in other places where ACE2 is also present: the intestines, kidneys, and heart. This likely accounts for at least some of the disease’s cardiac and GI symptoms.
But once Covid-19 has established itself in the body, things start to get really interesting. According to Jacobson’s group, the data Summit analyzed shows that Covid-19 isn’t content to simply infect cells that already express lots of ACE2 receptors. Instead, it actively hijacks the body’s own systems, tricking it into upregulating ACE2 receptors in places where they’re usually expressed at low or medium levels, including the lungs.
In this sense, Covid-19 is like a burglar who slips in your unlocked second-floor window and starts to ransack your house. Once inside, though, they don’t just take your stuff — they also throw open all your doors and windows so their accomplices can rush in and help pillage more efficiently.
The renin–angiotensin system (RAS) controls many aspects of the circulatory system, including the body’s levels of a chemical called bradykinin, which normally helps to regulate blood pressure. According to the team’s analysis, when the virus tweaks the RAS, it causes the body’s mechanisms for regulating bradykinin to go haywire. Bradykinin receptors are resensitized, and the body also stops effectively breaking down bradykinin. (ACE normally degrades bradykinin, but when the virus downregulates it, it can’t do this as effectively.)
The end result, the researchers say, is to release a bradykinin storm — a massive, runaway buildup of bradykinin in the body. According to the bradykinin hypothesis, it’s this storm that is ultimately responsible for many of Covid-19’s deadly effects. Jacobson’s team says in their paper that “the pathology of Covid-19 is likely the result of Bradykinin Storms rather than cytokine storms,” which had been previously identified in Covid-19 patients, but that “the two may be intricately linked.” Other papers had previously identified bradykinin storms as a possible cause of Covid-19’s pathologies.
Covid-19 is like a burglar who slips in your unlocked second-floor window and starts to ransack your house.
As bradykinin builds up in the body, it dramatically increases vascular permeability. In short, it makes your blood vessels leaky. This aligns with recent clinical data, which increasingly views Covid-19 primarily as a vascular disease, rather than a respiratory one. But Covid-19 still has a massive effect on the lungs. As blood vessels start to leak due to a bradykinin storm, the researchers say, the lungs can fill with fluid. Immune cells also leak out into the lungs, Jacobson’s team found, causing inflammation.
And Covid-19 has another especially insidious trick. Through another pathway, the team’s data shows, it increases production of hyaluronic acid (HLA) in the lungs. HLA is often used in soaps and lotions for its ability to absorb more than 1,000 times its weight in fluid. When it combines with fluid leaking into the lungs, the results are disastrous: It forms a hydrogel, which can fill the lungs in some patients. According to Jacobson, once this happens, “it’s like trying to breathe through Jell-O.”
This may explain why ventilators have proven less effective in treating advanced Covid-19 than doctors originally expected, based on experiences with other viruses. “It reaches a point where regardless of how much oxygen you pump in, it doesn’t matter, because the alveoli in the lungs are filled with this hydrogel,” Jacobson says. “The lungs become like a water balloon.” Patients can suffocate even while receiving full breathing support.
The bradykinin hypothesis also extends to many of Covid-19’s effects on the heart. About one in five hospitalized Covid-19 patients have damage to their hearts, even if they never had cardiac issues before. Some of this is likely due to the virus infecting the heart directly through its ACE2 receptors. But the RAS also controls aspects of cardiac contractions and blood pressure. According to the researchers, bradykinin storms could create arrhythmias and low blood pressure, which are often seen in Covid-19 patients.
The bradykinin hypothesis also accounts for Covid-19’s neurological effects, which are some of the most surprising and concerning elements of the disease. These symptoms (which include dizziness, seizures, delirium, and stroke) are present in as many as half of hospitalized Covid-19 patients. According to Jacobson and his team, MRI studies in France revealed that many Covid-19 patients have evidence of leaky blood vessels in their brains.
Bradykinin — especially at high doses — can also lead to a breakdown of the blood-brain barrier. Under normal circumstances, this barrier acts as a filter between your brain and the rest of your circulatory system. It lets in the nutrients and small molecules that the brain needs to function, while keeping out toxins and pathogens and keeping the brain’s internal environment tightly regulated.
If bradykinin storms cause the blood-brain barrier to break down, this could allow harmful cells and compounds into the brain, leading to inflammation, potential brain damage, and many of the neurological symptoms Covid-19 patients experience. Jacobson told me, “It is a reasonable hypothesis that many of the neurological symptoms in Covid-19 could be due to an excess of bradykinin. It has been reported that bradykinin would indeed be likely to increase the permeability of the blood-brain barrier. In addition, similar neurological symptoms have been observed in other diseases that result from an excess of bradykinin.”
Increased bradykinin levels could also account for other common Covid-19 symptoms. ACE inhibitors — a class of drugs used to treat high blood pressure — have a similar effect on the RAS system as Covid-19, increasing bradykinin levels. In fact, Jacobson and his team note in their paper that “the virus… acts pharmacologically as an ACE inhibitor” — almost directly mirroring the actions of these drugs.
By acting like a natural ACE inhibitor, Covid-19 may be causing the same effects that hypertensive patients sometimes get when they take blood pressure–lowering drugs. ACE inhibitors are known to cause a dry cough and fatigue, two textbook symptoms of Covid-19. And they can potentially increase blood potassium levels, which has also been observed in Covid-19 patients. The similarities between ACE inhibitor side effects and Covid-19 symptoms strengthen the bradykinin hypothesis, the researchers say.
ACE inhibitors are also known to cause a loss of taste and smell. Jacobson stresses, though, that this symptom is more likely due to the virus “affecting the cells surrounding olfactory nerve cells” than the direct effects of bradykinin.
Though still an emerging theory, the bradykinin hypothesis explains several other of Covid-19’s seemingly bizarre symptoms. Jacobson and his team speculate that leaky vasculature caused by bradykinin storms could be responsible for “Covid toes,” a condition involving swollen, bruised toes that some Covid-19 patients experience. Bradykinin can also mess with the thyroid gland, which could produce the thyroid symptoms recently observed in some patients.
The bradykinin hypothesis could also explain some of the broader demographic patterns of the disease’s spread. The researchers note that some aspects of the RAS system are sex-linked, with proteins for several receptors (such as one called TMSB4X) located on the X chromosome. This means that “women… would have twice the levels of this protein than men,” a result borne out by the researchers’ data. In their paper, Jacobson’s team concludes that this “could explain the lower incidence of Covid-19 induced mortality in women.” A genetic quirk of the RAS could be giving women extra protection against the disease.
The bradykinin hypothesis provides a model that “contributes to a better understanding of Covid-19” and “adds novelty to the existing literature,” according to scientists Frank van de Veerdonk, Jos WM van der Meer, and Roger Little, who peer-reviewed the team’s paper. It predicts nearly all the disease’s symptoms, even ones (like bruises on the toes) that at first appear random, and further suggests new treatments for the disease.
As Jacobson and team point out, several drugs target aspects of the RAS and are already FDA approved to treat other conditions. They could arguably be applied to treating Covid-19 as well. Several, like danazol, stanozolol, and ecallantide, reduce bradykinin production and could potentially stop a deadly bradykinin storm. Others, like icatibant, reduce bradykinin signaling and could blunt its effects once it’s already in the body.
Interestingly, Jacobson’s team also suggests vitamin D as a potentially useful Covid-19 drug. The vitamin is involved in the RAS system and could prove helpful by reducing levels of another compound, known as REN. Again, this could stop potentially deadly bradykinin storms from forming. The researchers note that vitamin D has already been shown to help those with Covid-19. The vitamin is readily available over the counter, and around 20% of the population is deficient. If indeed the vitamin proves effective at reducing the severity of bradykinin storms, it could be an easy, relatively safe way to reduce the severity of the virus.
Other compounds could treat symptoms associated with bradykinin storms. Hymecromone, for example, could reduce hyaluronic acid levels, potentially stopping deadly hydrogels from forming in the lungs. And timbetasin could mimic the mechanism that the researchers believe protects women from more severe Covid-19 infections. All of these potential treatments are speculative, of course, and would need to be studied in a rigorous, controlled environment before their effectiveness could be determined and they could be used more broadly.
Covid-19 stands out for both the scale of its global impact and the apparent randomness of its many symptoms. Physicians have struggled to understand the disease and come up with a unified theory for how it works. Though as of yet unproven, the bradykinin hypothesis provides such a theory. And like all good hypotheses, it also provides specific, testable predictions — in this case, actual drugs that could provide relief to real patients.
The researchers are quick to point out that “the testing of any of these pharmaceutical interventions should be done in well-designed clinical trials.” As to the next step in the process, Jacobson is clear: “We have to get this message out.” His team’s finding won’t cure Covid-19. But if the treatments it points to pan out in the clinic, interventions guided by the bradykinin hypothesis could greatly reduce patients’ suffering — and potentially save lives.
Summary: With widespread, sustained declines in fertility, the world population will likely peak in 2064 at around 9.7 billion, and then decline to about 8.8 billion by 2100 — about 2 billion lower than some previous estimates, according to a new study.
Improvements in access to modern contraception and the education of girls and women are generating widespread, sustained declines in fertility, and world population will likely peak in 2064 at around 9.7 billion, and then decline to about 8.8 billion by 2100 — about 2 billion lower than some previous estimates, according to a new study published in The Lancet.
The modelling research uses data from the Global Burden of Disease Study 2017 to project future global, regional, and national population. Using novel methods for forecasting mortality, fertility, and migration, the researchers from the Institute for Health Metrics and Evaluation (IHME) at the University of Washington’s School of Medicine estimate that by 2100, 183 of 195 countries will have total fertility rates (TFR), which represent the average number of children a woman delivers over her lifetime, below replacement level of 2.1 births per woman. This means that in these countries populations will decline unless low fertility is compensated by immigration.
The new population forecasts contrast to projections of ‘continuing global growth’ by the United Nations Population Division, and highlight the huge challenges to economic growth of a shrinking workforce, the high burden on health and social support systems of an aging population, and the impact on global power linked to shifts in world population.
The new study also predicts huge shifts in the global age structure, with an estimated 2.37 billion individuals over 65 years globally in 2100, compared with 1.7 billion under 20 years, underscoring the need for liberal immigration policies in countries with significantly declining working age populations.
“Continued global population growth through the century is no longer the most likely trajectory for the world’s population,” says IHME Director Dr. Christopher Murray, who led the research. “This study provides governments of all countries an opportunity to start rethinking their policies on migration, workforces and economic development to address the challenges presented by demographic change.”
IHME Professor Stein Emil Vollset, first author of the paper, continues, “The societal, economic, and geopolitical power implications of our predictions are substantial. In particular, our findings suggest that the decline in the numbers of working-age adults alone will reduce GDP growth rates that could result in major shifts in global economic power by the century’s end. Responding to population decline is likely to become an overriding policy concern in many nations, but must not compromise efforts to enhance women’s reproductive health or progress on women’s rights.”
Dr Richard Horton, Editor-in-Chief, The Lancet, adds: “This important research charts a future we need to be planning for urgently. It offers a vision for radical shifts in geopolitical power, challenges myths about immigration, and underlines the importance of protecting and strengthening the sexual and reproductive rights of women. The 21st century will see a revolution in the story of our human civilisation. Africa and the Arab World will shape our future, while Europe and Asia will recede in their influence. By the end of the century, the world will be multipolar, with India, Nigeria, China, and the US the dominant powers. This will truly be a new world, one we should be preparing for today.”
Accelerating decline in fertility worldwide
The global TFR is predicted to steadily decline, from 2.37 in 2017 to 1.66 in 2100 — well below the minimum rate (2.1) considered necessary to maintain population numbers (replacement level) — with rates falling to around 1.2 in Italy and Spain, and as low as 1.17 in Poland.
Even slight changes in TFR translate into large differences in population size in countries below the replacement level — increasing TFR by as little as 0.1 births per woman is equivalent to around 500 million more individuals on the planet in 2100.
Much of the anticipated fertility decline is predicted in high-fertility countries, particularly those in sub-Saharan Africa where rates are expected to fall below the replacement level for the first time — from an average 4.6 births per woman in 2017 to just 1.7 by 2100. In Niger, where the fertility rate was the highest in the world in 2017 — with women giving birth to an average of seven children — the rate is projected to decline to around 1.8 by 2100.
Nevertheless, the population of sub-Saharan Africa is forecast to triple over the course of the century, from an estimated 1.03 billion in 2017 to 3.07 billion in 2100 — as death rates decline and an increasing number of women enter reproductive age. North Africa and the Middle East is the only other region predicted to have a larger population in 2100 (978 million) than in 2017 (600 million).
Many of the fastest-shrinking populations will be in Asia and central and eastern Europe. Populations are expected to more than halve in 23 countries and territories, including Japan (from around 128 million people in 2017 to 60 million in 2100), Thailand (71 to 35 million), Spain (46 to 23 million), Italy (61 to 31 million), Portugal (11 to 5 million), and South Korea (53 to 27 million). An additional 34 countries are expected to have population declines of 25 to 50%, including China (1.4 billion in 2017 to 732 million in 2100; see table).
Huge shifts in global age structure — with over 80s outnumbering under 5s two to one
As fertility falls and life expectancy increases worldwide, the number of children under 5 years old is forecasted to decline by 41% from 681 million in 2017 to 401 million in 2100, whilst the number of individuals older than 80 years is projected to increase six fold, from 141 million to 866 million. Similarly, the global ratio of adults over 80 years to each person aged 15 years or younger is projected to rise from 0.16 in 2017 to 1.50 in 2100, in countries with a population decline of more than 25%.
Furthermore, the global ratio of non-working adults to workers was around 0.8 in 2017, but is projected to increase to 1.16 in 2100 if labour force participation by age and sex does not change.
“While population decline is potentially good news for reducing carbon emissions and stress on food systems, with more old people and fewer young people, economic challenges will arise as societies struggle to grow with fewer workers and taxpayers, and countries’ abilities to generate the wealth needed to fund social support and health care for the elderly are reduced,” says Vollset.
Declining working-age populations could see major shifts in size of economies
The study also examined the economic impact of fewer working-age adults for all countries in 2017. While China is set to replace the USA in 2035 with the largest total gross domestic product (GDP) globally, rapid population decline from 2050 onward will curtail economic growth. As a result, the USA is expected to reclaim the top spot by 2098, if immigration continues to sustain the US workforce.
Although numbers of working-age adults in India are projected to fall from 762 million in 2017 to around 578 million in 2100, it is expected to be one of the few — if only — major power in Asia to protect its working-age population over the century. It is expected to surpass China’s workforce population in the mid-2020s (where numbers of workers are estimated to decline from 950 million in 2017 to 357 million in 2100) — rising up the GDP rankings from 7th to 3rd.
Sub-Saharan Africa is likely to become an increasingly powerful continent on the geopolitical stage as its population rises. Nigeria is projected to be the only country among the world’s 10 most populated nations to see its working-age population grow over the course of the century (from 86 million in 2017 to 458 million in 2100), supporting rapid economic growth and its rise in GDP rankings from 23rd place in 2017 to 9th place in 2100.
While the UK, Germany, and France are expected to remain in the top 10 for largest GDP worldwide at the turn of the century, Italy (from rank 9th in 2017 to 25th in 2100) and Spain (from 13th to 28th) are projected to fall down the rankings, reflecting much greater population decline.
Liberal immigration could help sustain population size and economic growth
The study also suggests that population decline could be offset by immigration, with countries that promote liberal immigration better able to maintain their population size and support economic growth, even in the face of declining fertility rates.
The model predicts that some countries with fertility lower than replacement level, such as the USA, Australia, and Canada, will probably maintain their working-age populations through net immigration (see appendix 2 section 4). Although the authors note that there is considerable uncertainty about these future trends.
“For high-income countries with below-replacement fertility rates, the best solutions for sustaining current population levels, economic growth, and geopolitical security are open immigration policies and social policies supportive of families having their desired number of children,” Murray says. “However, a very real danger exists that, in the face of declining population, some countries might consider policies that restrict access to reproductive health services, with potentially devastating consequences. It is imperative that women’s freedom and rights are at the top of every government’s development agenda.”
The authors note some important limitations, including that while the study uses the best available data, predictions are constrained by the quantity and quality of past data. They also note that past trends are not always predictive of what will happen in the future, and that some factors not included in the model could change the pace of fertility, mortality, or migration. For example, the COVID-19 pandemic has affected local and national health systems throughout the world, and caused over half a million deaths. However, the authors believe the excess deaths caused by the pandemic are unlikely to significantly alter longer term forecasting trends of global population.
Writing in a linked Comment, Professor Ibrahim Abubakar, University College London (UCL), UK, and Chair of Lancet Migration (who was not involved in the study), says: “Migration can be a potential solution to the predicted shortage of working-age populations. While demographers continue to debate the long-term implications of migration as a remedy for declining TFR, for it to be successful, we need a fundamental rethink of global politics. Greater multilateralism and a new global leadership should enable both migrant sending and migrant-receiving countries to benefit, while protecting the rights of individuals. Nations would need to cooperate at levels that have eluded us to date to strategically support and fund the development of excess skilled human capital in countries that are a source of migrants. An equitable change in global migration policy will need the voice of rich and poor countries. The projected changes in the sizes of national economies and the consequent change in military power might force these discussions.”
He adds: “Ultimately, if Murray and colleagues’ predictions are even half accurate, migration will become a necessity for all nations and not an option. The positive impacts of migration on health and economies are known globally. The choice that we face is whether we improve health and wealth by allowing planned population movement or if we end up with an underclass of imported labour and unstable societies. The Anthropocene has created many challenges such as climate change and greater global migration. The distribution of working-age populations will be crucial to whether humanity prospers or withers.”
The study was in part funded by the Bill & Melinda Gates Foundation. It was conducted by researchers at the University of Washington, Seattle, USA.
Story Source:
Materials provided by The Lancet. Note: Content may be edited for style and length.
Journal Reference:
Stein Emil Vollset, Emily Goren, Chun-Wei Yuan, Jackie Cao, Amanda E Smith, Thomas Hsiao, Catherine Bisignano, Gulrez S Azhar, Emma Castro, Julian Chalek, Andrew J Dolgert, Tahvi Frank, Kai Fukutaki, Simon I Hay, Rafael Lozano, Ali H Mokdad, Vishnu Nandakumar, Maxwell Pierce, Martin Pletcher, Toshana Robalik, Krista M Steuben, Han Yong Wunrow, Bianca S Zlavog, Christopher J L Murray. Fertility, mortality, migration, and population scenarios for 195 countries and territories from 2017 to 2100: a forecasting analysis for the Global Burden of Disease Study. The Lancet, 2020; DOI: 10.1016/S0140-6736(20)30677-2
On May 20, disease modelers at Columbia University posted a preprint that concluded the US could have prevented 36,000 of the 65,300 deaths that the country had suffered as a result of COVID-19 by May 3 if states had instituted social distancing measures a week earlier. In early June, Imperial College London epidemiologist Neil Ferguson, one of the UK government’s key advisers in the early stages of the pandemic, came to a similar conclusion about the UK. In evidence he presented to a parliamentary committee inquiry, Ferguson said that if the country had introduced restrictions on movement and socializing a week sooner than it did, Britain’s official death toll of 40,000 could have been halved.
On a more positive note, Ferguson and other researchers at Imperial College London published a model in Nature around the same time estimating that more than 3 million deaths had been avoided in the UK as a result of the policies that were put in place.
These and other studies from recent months aim to understand how well various social-distancing measures have curbed infections, and by extension saved lives. It’s a big challenge to unravel and reliably understand all the factors at play, but experts say the research could help inform future policies.
The most effective measure, one study found, was getting people not to travel to work, while school closures had relatively little effect.
“It’s not just about looking retrospectively,” Jeffrey Shaman, a data scientist at Columbia University and coauthor of the preprint on US deaths, tells The Scientist. “All the places that have managed to get it under control to a certain extent are still at risk of having a rebound and a flare up. And if they don’t respond to it because they can’t motivate the political and public will to actually reinstitute control measures, then we’re going to repeat the same mistakes.”
Diving into the data
Shaman and his team used a computer model and data on how people moved around to work out how reduced contact between people could explain disease trends after the US introduced social distancing measures in mid-March. Then, the researchers looked at what would have happened if the same measures had been introduced a week earlier, and found that more than half of total infections and deaths up to May 3 would have been prevented. Starting the measures on March 1 would have prevented 83 percent of the nation’s deaths during that period, according to the model. Shaman says he is waiting to submit for publication in a peer-reviewed journal until he and his colleagues update the study with more-recent data.
“I thought they had reasonably credible data in terms of trying to argue that the lockdowns had prevented infections,” says Daniel Sutter, an economist at Troy University. “They were training or calibrating that model using some cell phone data and foot traffic data and correlating that with lockdowns.”
Sébastien Annan-Phan, an economist at the University of California, Berkeley, undertook a similar analysis, looking at the growth rate of case numbers before and after various lockdown measures were introduced in China, South Korea, Italy, Iran, France, and the US. Because these countries instituted different combinations of social distancing measures, the team was able to estimate how well each action slowed disease spread. The most effective measure, they found, was getting people not to travel to work, while school closures had relatively little effect. “Every country is different and they implement different policies, but we can still tease out a couple of things,” says Annan-Phan.
In total, his group estimated that combined interventions prevented or delayed about 62 million confirmed cases in the six countries studied, or about 530 million total infections. The results were published in Naturein June alongside a study from a group at Imperial College London, which had compared COVID-19 cases reported in several European countries under lockdown with the worst-case scenario predicted for each of those countries by a computer model in which no such measures were taken. According to that analysis, which assumed that the effects of social distancing measures were the same from country to country, some 3.1 million deaths had been avoided.
It’s hard to argue against the broad conclusion that changing people’s behavior was beneficial, says Andrew Gelman, a statistician at Columbia University. “If people hadn’t changed their behavior, then it would have been disastrous.”
Lockdown policies versus personal decisions to isolate
Like all hypothetical scenarios, it’s impossible to know how events would have played out if different decisions were made. And attributing changes in people’s behavior to official lockdown policies during the pandemic is especially difficult, says Gelman. “Ultimately, we can’t say what would have happened without it, because the timing of lockdown measures correlates with when people would have gone into self-isolation anyway.” Indeed, according to a recent study of mobile phone data in the US, many people started to venture out less a good one to four weeks before they were officially asked to.
A report on data from Sweden, a country that did not introduce the same strict restrictions as others in Europe, seems to support that idea. It found that, compared with data from other countries, Sweden’s outcomes were no worse. “A lockdown would not have helped in terms of limiting COVID-19 infections or deaths in Sweden,” the study originally concluded. But Gernot Müller, an economist at the University of Tubingen who worked on that report, now says updated data show that original conclusion was flawed. Many Swedes took voluntary actions in the first few weeks, he says, and this masked the benefits that a lockdown would have had. But after the first month, the death rate started to rise. “It turns out that we do now see a lockdown effect,” Müller says of his group’s new, still unpublished analyses. “So lockdowns do work and we can attach a number to that: some 40 percent or 50 percent fewer deaths.”
Some critics question the assumption that such deaths have been prevented, rather than simply delayed. While it can appear to be a semantic point, the distinction between preventing and delaying infection is an important one when policymakers assess the costs and benefits of lockdown measures, Sutter says. “I think it’s a little misleading to keep saying these lockdowns have prevented death. They’ve just prevented cases from occurring so far,” he says. “There’s still the underlying vulnerability out there. People are still susceptible to get the virus and get sick at a later date.”
Shaman notes, however, that it’s really a race against the clock. It’s about “buying yourself and your population critical time to not be infected while we try to get our act together to produce an effective vaccine or therapeutic.”

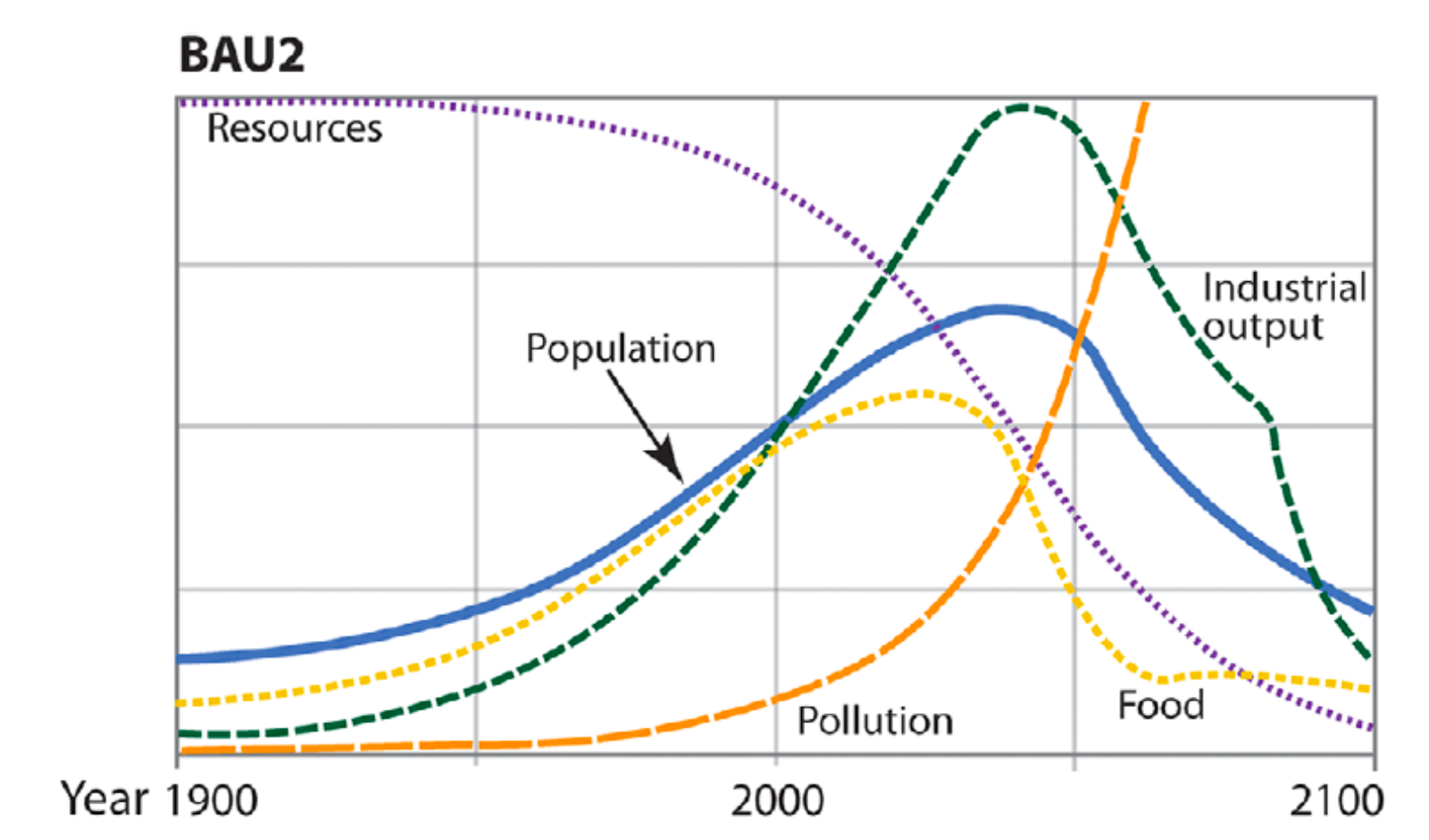
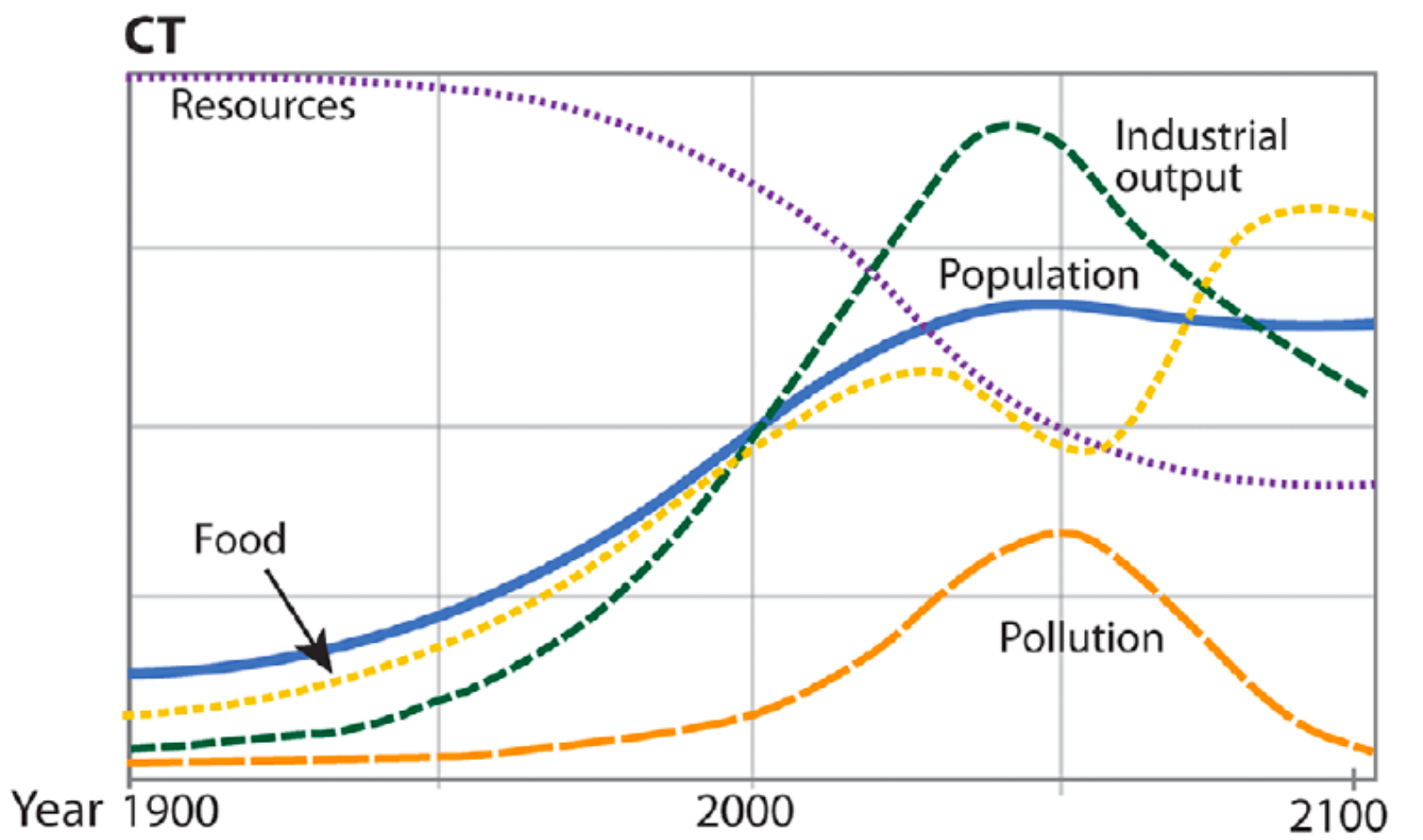
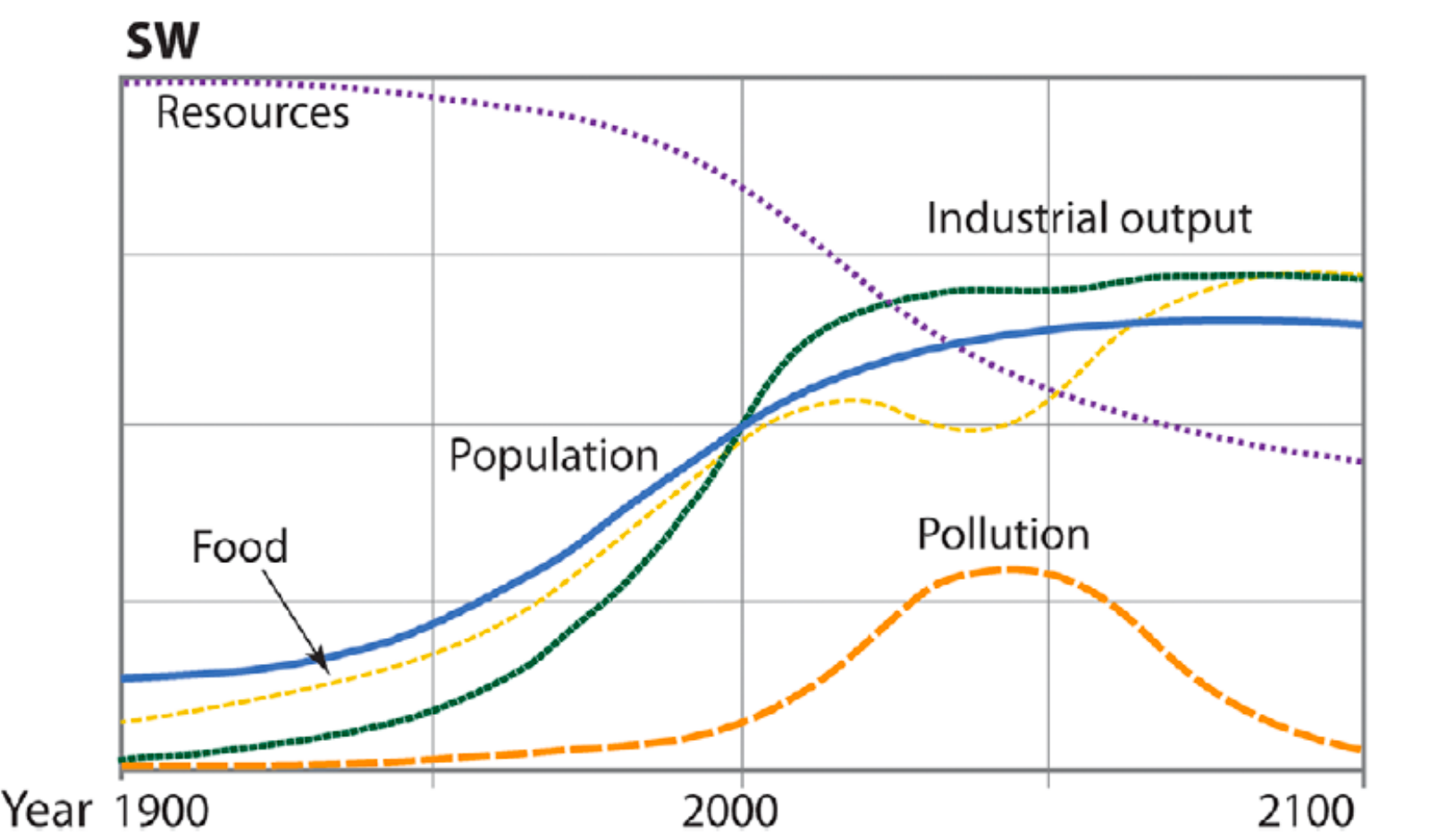












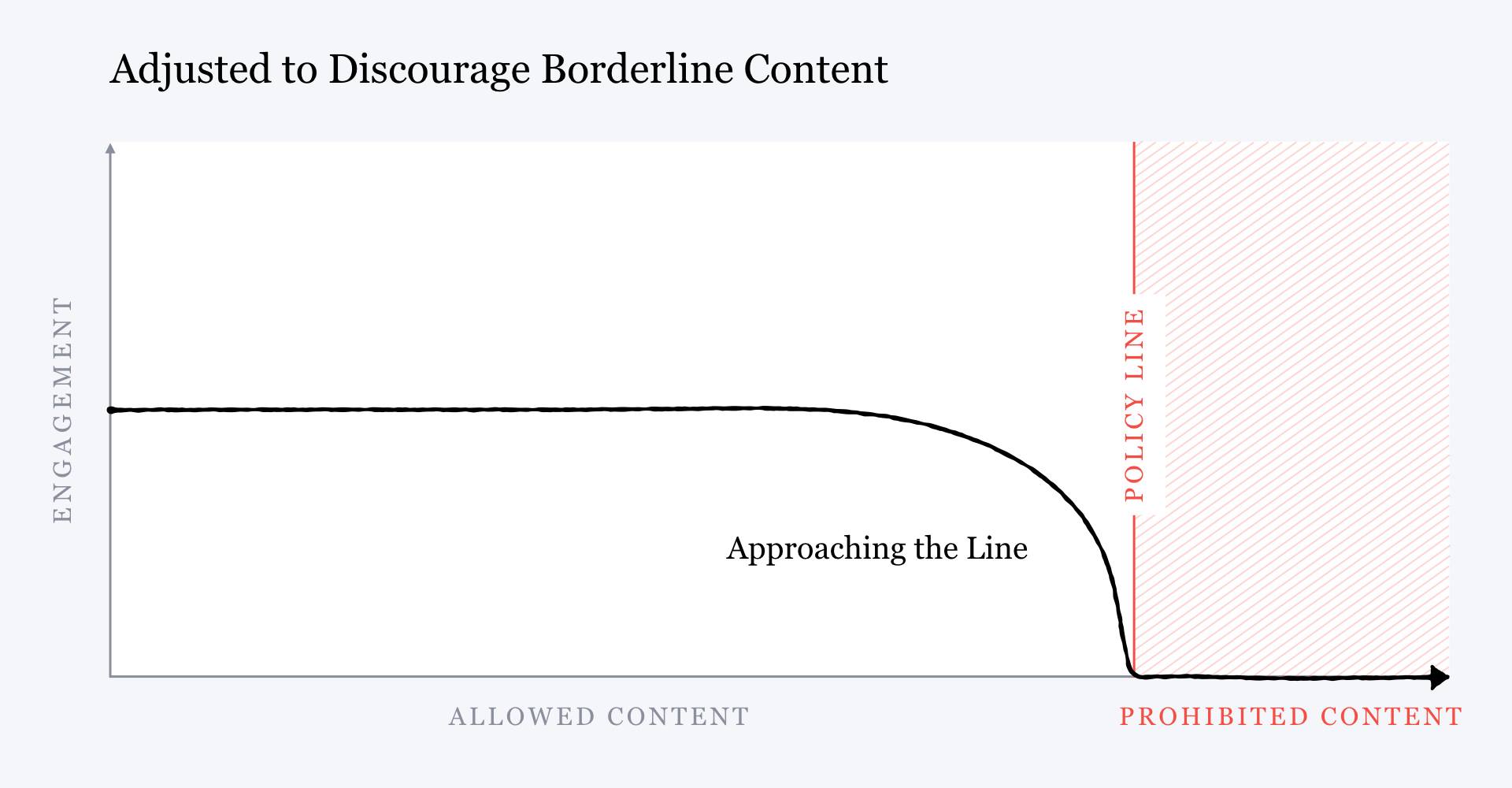










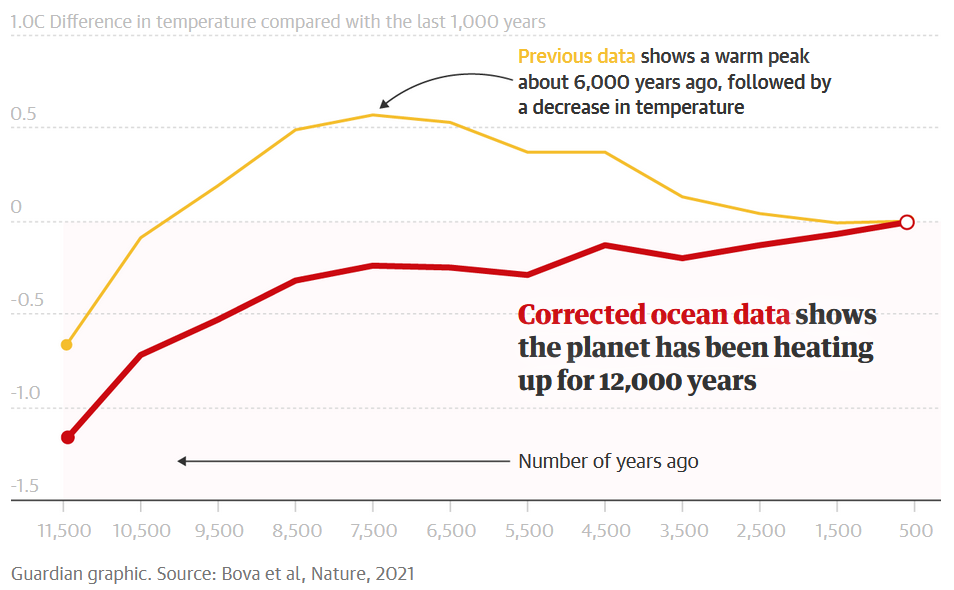
















 Illustration: Marian Bantjes “All models are wrong, but some are useful.”
Illustration: Marian Bantjes “All models are wrong, but some are useful.”





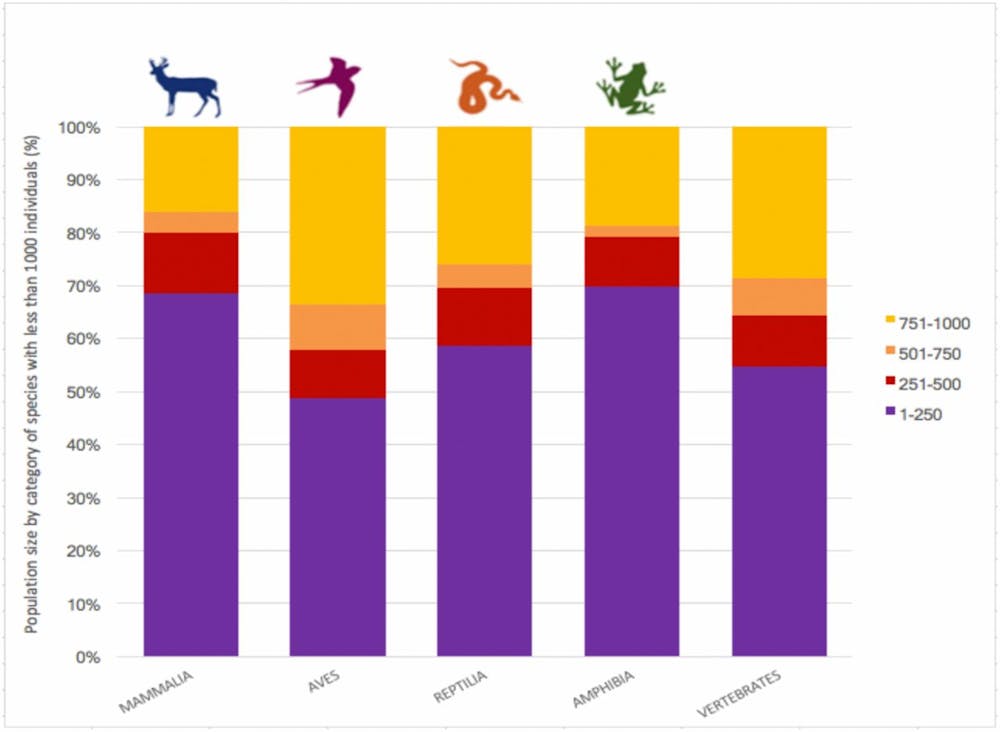


Você precisa fazer login para comentar.