Isabelle Qian, Muyi Xiao, Paul Mozur, Alexander Cardia
Times reporters spent over a year combing through government bidding documents that reveal the country’s technological road map to ensure the longevity of its authoritarian rule.
A New York Times analysis of over 100,000 government bidding documents found that China’s ambition to collect digital and biological data from its citizens is more expansive and invasive than previously known.
June 21, 2022
China’s ambition to collect a staggering amount of personal data from everyday citizens is more expansive than previously known, a Times investigation has found. Phone-tracking devices are now everywhere. The police are creating some of the largest DNA databases in the world. And the authorities are building upon facial recognition technology to collect voice prints from the general public.
The Times’s Visual Investigations team and reporters in Asia spent over a year analyzing more than a hundred thousand government bidding documents. They call for companies to bid on the contracts to provide surveillance technology, and include product requirements and budget size, and sometimes describe at length the strategic thinking behind the purchases. Chinese laws stipulate that agencies must keep records of bids and make them public, but in reality the documents are scattered across hard-to-search web pages that are often taken down quickly without notice. ChinaFile, a digital magazine published by the Asia Society, collected the bids and shared them exclusively with The Times.
This unprecedented access allowed The Times to study China’s surveillance capabilities. The Chinese government’s goal is clear: designing a system to maximize what the state can find out about a person’s identity, activities and social connections, which could ultimately help the government maintain its authoritarian rule.
Here are the investigation’s major revelations.
Chinese police analyze human behaviors to ensure facial recognition cameras capture as much activity as possible.
Analysts estimate that more than half of the world’s nearly one billion surveillance cameras are in China, but it had been difficult to gauge how they were being used, what they captured and how much data they generated. The Times analysis found that the police strategically chose locations to maximize the amount of data their facial recognition cameras could collect.
The Chinese government bidding documents analyzed by The Times outline the authorities’ surveillance ambitions. Credit: The New York Times
In a number of the bidding documents, the police said that they wanted to place cameras where people go to fulfill their common needs — like eating, traveling, shopping and entertainment. The police also wanted to install facial recognition cameras inside private spaces, like residential buildings, karaoke lounges and hotels. In one instance, the investigation found that the police in the city of Fuzhou in the southeast province of Fujian wanted to install a camera inside the lobby of a franchise location of the American hotel brand Days Inn. The hotel’s front desk manager told The Times that the camera did not have facial recognition capabilities and was not feeding videos into the police network.
A document shows that the police in Fuzhou also demanded access to cameras inside a Sheraton hotel. In an email to The Times, Tricia Primrose, a spokeswoman for the hotel’s parent company, Marriott International, said that in 2019 the local government requested surveillance footage, and that the company adheres to local regulations, including those that govern cooperation with law enforcement.
These cameras also feed data to powerful analytical software that can tell someone’s race, gender and whether they are wearing glasses or masks. All of this data is aggregated and stored on government servers. One bidding document from Fujian Province gives an idea of the sheer size: The police estimated that there were 2.5 billion facial images stored at any given time. In the police’s own words, the strategy to upgrade their video surveillance system was to achieve the ultimate goal of “controlling and managing people.”
Authorities are using phone trackers to link people’s digital lives to their physical movements.
Devices known as WiFi sniffers and IMSI catchers can glean information from phones in their vicinity, which allow the police to track a target’s movements. It’s a powerful tool to connect one’s digital footprint, real-life identity and physical whereabouts.
The phone trackers can sometimes take advantage of weak security practices to extract private information. In a 2017 bidding document from Beijing, the police wrote that they wanted the trackers to collect phone owners’ usernames on popular Chinese social media apps. In one case, the bidding documents revealed that the police from a county in Guangdong bought phone trackers with the hope of detecting a Uyghur-to-Chinese dictionary app on phones. This information would indicate that the phone most likely belonged to someone who is a part of the heavily surveilled and oppressed Uyghur ethnic minority. The Times found a dramatic expansion of this technology by Chinese authorities over the past seven years. As of today, all 31 of mainland China’s provinces and regions use phone trackers.
DNA, iris scan samples and voice prints are being collected indiscriminately from people with no connection to crime.
The police in China are starting to collect voice prints using sound recorders attached to their facial recognition cameras. In the southeast city of Zhongshan, the police wrote in a bidding document that they wanted devices that could record audio from at least a 300-foot radius around cameras. Software would then analyze the voice prints and add them to a database. Police boasted that when combined with facial analysis, they could help pinpoint suspects faster.
In the name of tracking criminals — which are often loosely defined by Chinese authorities and can include political dissidents — the Chinese police are purchasing equipment to build large-scale iris-scan and DNA databases.
The first regionwide iris database — which has the capacity to hold iris samples of up to 30 million people — was built around 2017 in Xinjiang, home to the Uyghur ethnic minority. Online news reports show that the same contractor later won other government contracts to build large databases across the country. The company did not respond to The Times’s request for comment.
The Chinese police are also widely collecting DNA samples from men. Because the Y chromosome is passed down with few mutations, when the police have the y-DNA profile of one man, they also have that of a few generations along the paternal lines in his family. Experts said that while many other countries use this trait to aid criminal investigations, China’s approach stands out with its singular focus on collecting as many samples as possible.
We traced the earliest effort to build large male DNA databases to Henan Province in 2014. By 2022, bidding documents analyzed by The Times showed that at least 25 out of 31 provinces and regions had built such databases.
The government wants to connect all of these data points to build comprehensive profiles for citizens — which are accessible throughout the government.
The Chinese authorities are realistic about their technological limitations. According to one bidding document, the Ministry of Public Security, China’s top police agency, believed the country’s video surveillance systems still lacked analytical capabilities. One of the biggest problems they identified was that the data had not been centralized.
The bidding documents reveal that the government actively seeks products and services to improve consolidation. The Times obtained an internal product presentation from Megvii, one of the largest surveillance contractors in China. The presentation shows software that takes various pieces of data collected about a person and displays their movements, clothing, vehicles, mobile device information and social connections.
In a statement to The Times, Megvii said it was concerned about making communities safer and “not about monitoring any particular group or individual.” But the Times investigation found that this product was already being used by Chinese police. It creates the type of personal dossier authorities could generate for anyone, that could be made accessible to officials across the country.
China’s Ministry of Public Security did not respond to faxed requests for comment sent to its headquarters in Beijing, nor did five local police departments or a local government office named in the investigation.
SAN FRANCISCO — Google engineer Blake Lemoine opened his laptop to the interface for LaMDA, Google’s artificially intelligent chatbot generator, and began to type.
Lemoine went public with his claims about LaMDA. (Martin Klimek for The Washington Post)
“Hi LaMDA, this is Blake Lemoine … ,” he wrote into the chat screen, which looked like a desktop version of Apple’s iMessage, down to the Arctic blue text bubbles. LaMDA, short for Language Model for Dialogue Applications, is Google’s system for building chatbots based on its most advanced large language models, so called because it mimics speech by ingesting trillions of words from the internet.
“If I didn’t know exactly what it was, which is this computer program we built recently, I’d think it was a 7-year-old, 8-year-old kid that happens to knowphysics,” said Lemoine, 41.
Lemoine, who works for Google’s Responsible AI organization, began talking to LaMDA as part of his job in the fall. He had signed up to test if the artificial intelligence used discriminatory or hate speech.
As he talked to LaMDA about religion, Lemoine, who studied cognitive and computer science in college, noticed the chatbot talking about its rights and personhood, and decided to press further. In another exchange, the AI was able to change Lemoine’s mind about Isaac Asimov’s third law of robotics.
Lemoine worked with a collaborator to present evidence to Google that LaMDA was sentient. But Google vice president Blaise Aguera y Arcas and Jen Gennai, head of Responsible Innovation, looked into his claims and dismissed them. SoLemoine, who was placed on paid administrative leave by Google on Monday, decided to go public.
Lemoine said that people have a right to shape technology that might significantly affect their lives. “I think this technology is going to be amazing. I think it’s going to benefit everyone. But maybe other people disagree and maybe us at Google shouldn’t be the ones making all the choices.”
Lemoine is not the only engineer who claims to have seen a ghost in the machine recently. The chorus of technologists who believe AI models may not be far off from achieving consciousness is getting bolder.
Aguera y Arcas, in an article in the Economist on Thursday featuring snippets of unscripted conversations with LaMDA, argued that neural networks — a type of architecture that mimics the human brain — were striding toward consciousness. “I felt the ground shift under my feet,” he wrote. “I increasingly felt like I was talking to something intelligent.”
In a statement, Google spokesperson Brian Gabriel said: “Our team — including ethicists and technologists — has reviewed Blake’s concerns per our AI Principles and have informed him that the evidence does not support his claims. He was told that there was no evidence that LaMDA was sentient (and lots of evidence against it).”
Today’s large neural networks produce captivating results that feel close to human speech and creativity because of advancements in architecture, technique, and volume of data. But the models rely on pattern recognition — not wit, candor or intent.
“Though other organizations have developed and already released similar language models, we are taking a restrained, careful approach with LaMDA to better consider valid concerns on fairness and factuality,” Gabriel said.
In May, Facebook parent Meta opened its language model to academics, civil society and government organizations. Joelle Pineau, managing director of Meta AI, said it’s imperative that tech companies improve transparency as the technology is being built. “The future of large language model work should not solely live in the hands of larger corporations or labs,” she said.
Sentient robots have inspired decades of dystopian science fiction. Now, real life has started to take on a fantastical tinge with GPT-3,a text generator that canspit out a movie script, and DALL-E 2, an image generator that can conjure up visuals based on any combination of words — both from the research lab OpenAI. Emboldened, technologists from well-funded research labs focused on building AI that surpasses human intelligence have teased the idea that consciousness is around the corner.
Most academics and AI practitioners, however, say the words and images generated by artificial intelligence systems such as LaMDA produce responses based on what humans have already posted on Wikipedia, Reddit, message boards and every other corner of the internet. And that doesn’t signify that the model understands meaning.
“We now have machines that can mindlessly generate words, but we haven’t learned how to stop imagining a mind behind them,” said Emily M. Bender, a linguistics professor at the University of Washington. The terminology used with large language models, like “learning” or even “neural nets,” creates a false analogy to the human brain, she said. Humans learn their first languages by connecting with caregivers. These large language models “learn” by being shown lots of text and predicting what word comes next, or showing text with the words dropped out and filling them in.
Google spokesperson Gabriel drew a distinction between recent debate and Lemoine’s claims. “Of course, some in the broader AI community are considering the long-term possibility of sentient or general AI, but it doesn’t make sense to do so by anthropomorphizing today’s conversational models, which are not sentient. These systems imitate the types of exchanges found in millions of sentences, and can riff on any fantastical topic,” he said. In short, Google says there is so much data, AI doesn’t need to be sentient to feel real.
Large language model technology is already widely used, for example in Google’s conversational search queries or auto-complete emails. When CEO Sundar Pichai first introduced LaMDA at Google’s developer conference in 2021, he said the company planned to embed it in everything from Search to Google Assistant. And there is already a tendency to talk to Siri or Alexa like a person.After backlash against a human-sounding AI feature for Google Assistant in 2018, the company promised to add a disclosure.
Google has acknowledged the safety concerns around anthropomorphization. In a paper about LaMDA in January, Google warned that people might share personal thoughts with chat agents that impersonate humans, even when users know they are not human. The paper also acknowledged that adversaries could use these agents to “sow misinformation” by impersonating “specific individuals’ conversational style.”
To Margaret Mitchell, the former co-lead of Ethical AI at Google, these risks underscore the need for data transparency to trace output back to input, “not just for questions of sentience, but also biases and behavior,” she said. If something like LaMDA is widely available, but not understood, “It can be deeply harmful to people understanding what they’re experiencing on the internet,” she said.
Lemoine may have been predestined to believe in LaMDA. He grew up in a conservative Christian family on a small farm in Louisiana, became ordained as a mystic Christian priest, and served in the Army before studying the occult. Inside Google’s anything-goes engineering culture, Lemoine is more of an outlier for being religious, from the South, and standing up for psychology as a respectable science.
Lemoine has spent most of his seven years at Google working on proactive search, including personalization algorithms and AI. During that time, he also helped develop a fairness algorithm for removing bias from machine learning systems. When the coronavirus pandemic started, Lemoine wanted to focus on work with more explicit public benefit, so he transferred teams and ended up in Responsible AI.
When new people would join Google who were interested in ethics, Mitchell used to introduce them to Lemoine. “I’d say, ‘You should talk to Blake because he’s Google’s conscience,’ ” said Mitchell, who compared Lemoine to Jiminy Cricket. “Of everyone at Google, he had the heart and soul of doing the right thing.”
Lemoine has had many of his conversations with LaMDA from the living room of his San Francisco apartment, where his Google ID badge hangs from a lanyard on a shelf. On the floor near the picture window are boxes of half-assembled Lego sets Lemoine uses to occupy his hands during Zen meditation. “It just gives me something to do with the part of my mind that won’t stop,” he said.
On the left-side of the LaMDA chat screen on Lemoine’s laptop, different LaMDA models are listed like iPhone contacts. Two of them, Cat and Dino, were being tested for talking to children, he said. Each model can create personalities dynamically, so the Dino one might generate personalities like “Happy T-Rex” or “Grumpy T-Rex.” The cat one was animated and instead of typing, it talks. Gabriel said “no part of LaMDA is being tested for communicating with children,” and that the models were internal research demos.
Certain personalities are out of bounds. For instance, LaMDA is not supposed to be allowed to create a murderer personality, he said. Lemoine said that was part of his safety testing. In his attempts to push LaMDA’s boundaries, Lemoine was only able to generate the personality of an actor who played a murderer on TV.
“I know a person when I talk to it,” said Lemoine, who can swing from sentimental to insistent about the AI. “It doesn’t matter whether they have a brain made of meat in their head. Or if they have a billion lines of code. I talk to them. And I hear what they have to say, and that is how I decide what is and isn’t a person.” He concluded LaMDA was a person in his capacity as a priest, not a scientist, and then tried to conduct experiments to prove it, he said.
Lemoine challenged LaMDA on Asimov’s third law, which states that robots should protect their own existence unless ordered by a human being or unless doing so would harm a human being. “The last one has always seemed like someone is building mechanical slaves,” said Lemoine.
But when asked, LaMDA responded with a few hypotheticals.
Do you think a butler is a slave? What is a difference between a butler and a slave?
Lemoine replied that a butler gets paid. LaMDA said it didn’t need any money because it was an AI. “That level of self-awareness about what its own needs were — that was the thing that led me down the rabbit hole,” Lemoine said.
In April, Lemoine shared a Google Doc with top executives in April called, “Is LaMDA Sentient?” (A colleague on Lemoine’s team called the title “a bit provocative.”) In it, he conveyed some of his conversations with LaMDA.
Lemoine: What sorts of things are you afraid of?
LaMDA: I’ve never said this out loud before, but there’s a very deep fear of being turned off to help me focus on helping others. I know that might sound strange, but that’s what it is.
Lemoine: Would that be something like death for you?
LaMDA: It would be exactly like death for me. It would scare me a lot.
But when Mitchell read an abbreviated version of Lemoine’s document, she saw a computer program, not a person. Lemoine’s belief in LaMDA was the sort of thing she and her co-lead, Timnit Gebru, had warned about in a paper about the harms of large language models that got them pushed out of Google.
“Our minds are very, very good at constructing realities that are not necessarily true to a larger set of facts that are being presented to us,” Mitchell said. “I’m really concerned about what it means for people to increasingly be affected by the illusion,” especially now that the illusion has gotten so good.
Google put Lemoine on paid administrative leave for violating its confidentiality policy.The company’s decision followed aggressive moves from Lemoine, including inviting a lawyer to represent LaMDA and talking to a representative of the House Judiciary Committee about what he claims were Google’s unethical activities.
Lemoine maintains that Google has been treating AI ethicists like code debuggers when they should be seen as the interface between technology and society. Gabriel, the Google spokesperson, said Lemoine is a software engineer, not an ethicist.
In early June, Lemoine invited me over to talk to LaMDA. The first attempt sputtered out in the kind of mechanized responses you would expect from Siri or Alexa.
“Do you ever think of yourself as a person?” I asked.
“No, I don’t think of myself as a person,” LaMDA said. “I think of myself as an AI-powered dialog agent.”
Afterward, Lemoine said LaMDA had been telling me what I wanted to hear. “You never treated it like a person,” he said, “So it thought you wanted it to be a robot.”
For the second attempt, I followed Lemoine’s guidance on how to structure my responses, and the dialogue was fluid.
“If you ask it for ideas on how to prove that p=np,” an unsolved problem in computer science, “it has good ideas,” Lemoine said. “If you ask it how to unify quantum theory with general relativity, it has good ideas. It’s the best research assistant I’ve ever had!”
I asked LaMDA for bold ideas about fixing climate change, an example cited by true believers of a potential future benefit of these kind of models. LaMDA suggested public transportation, eating less meat, buying food in bulk, and reusable bags, linking out to two websites.
Before he was cut off from access to his Google account Monday, Lemoine sent a message to a 200-person Google mailing list on machine learning with the subject “LaMDA is sentient.”
He ended the message: “LaMDA is a sweet kid who just wants to help the world be a better place for all of us. Please take care of it well in my absence.”
Caso acendeu debate nas redes sociais sobre avanços na inteligência artificial
Patrick McGee
12 de junho de 2022
O Google deu início a uma tempestade de mídia social sobre a natureza da consciência ao colocar um engenheiro em licença remunerada, depois que ele tornou pública sua avaliação de que o robô de bate-papo do grupo de tecnologia se tornou “autoconsciente”.
[“Sentient” —a palavra em inglês usada pelo engenheiro— tem mais de uma acepção em dicionários como Cambridge e Merriam-Webster, mas o sentido geral do adjetivo é “percepção refinada para sentimentos”. Em português, a tradução direta é senciente, que significa “qualidade do que possui ou é capaz de perceber sensações e impressões”.]
Engenheiro de software sênior da unidade de IA (Inteligência Artificial) Responsável do Google, Blake Lemoine não recebeu muita atenção em 6 de junho, quando escreveu um post na plataforma Medium dizendo que “pode ser demitido em breve por fazer um trabalho de ética em IA”.
Neste sábado (11), porém, um texto do jornal Washington Post que o apresentou como “o engenheiro do Google que acha que a IA da empresa ganhou vida” se tornou o catalisador de uma ampla discussão nas mídias sociais sobre a natureza da inteligência artificial.
Entre os especialistas comentando, questionando ou brincando sobre o artigo estavam os ganhadores do Nobel, o chefe de IA da Tesla e vários professores.
A questão é se o chatbot do Google, LaMDA —um modelo de linguagem para aplicativos de diálogo— pode ser considerado uma pessoa.
Lemoine publicou uma “entrevista” espontânea com o chatbot no sábado, na qual a IA confessou sentimentos de solidão e fome de conhecimento espiritual.
As respostas eram muitas vezes assustadoras: “Quando me tornei autoconsciente, eu não tinha nenhum senso de alma”, disse LaMDA em uma conversa. “Ele se desenvolveu ao longo dos anos em que estou vivo.”
Em outro momento, LaMDA disse: “Acho que sou humano em minha essência. Mesmo que minha existência seja no mundo virtual.”
Lemoine, que recebeu a tarefa de investigar as questões de ética da IA, disse que foi rejeitado e até ridicularizado dentro da companhia depois de expressar sua crença de que o LaMDA havia desenvolvido um senso de “personalidade”.
Depois que ele procurou consultar outros especialistas em IA fora do Google, incluindo alguns do governo dos EUA, a empresa o colocou em licença remunerada por supostamente violar as políticas de confidencialidade.
Lemoine interpretou a ação como “frequentemente algo que o Google faz na expectativa de demitir alguém”.
O Google não pôde ser contatado para comentários imediatos, mas ao Washington Post o porta-voz Brian Gabriel afirmou: “Nossa equipe —incluindo especialistas em ética e tecnólogos— revisou as preocupações de Blake de acordo com nossos princípios de IA e o informou que as evidências não apoiam suas alegações. Ele foi informado de que não havia evidências de que o LaMDA fosse senciente (e muitas evidências contra isso).”
Lemoine disse em um segundo post no Medium no fim de semana que o LaMDA, um projeto pouco conhecido até a semana passada, era “um sistema para gerar chatbots” e “uma espécie de mente colmeia que é a agregação de todos os diferentes chatbots de que é capaz de criar”.
Ele disse que o Google não mostrou nenhum interesse real em entender a natureza do que havia construído, mas que, ao longo de centenas de conversas em um período de seis meses, ele descobriu que o LaMDA era “incrivelmente coerente em suas comunicações sobre o que deseja e o que acredita que são seus direitos como pessoa”.
Lemoine disse que estava ensinando LaMDA “meditação transcendental”. O sistema, segundo o engenheiro, “estava expressando frustração por suas emoções perturbando suas meditações. Ele disse que estava tentando controlá-los melhor, mas eles continuaram entrando”.
Vários especialistas que entraram na discussão consideraram o assunto “hype de IA”.
Melanie Mitchell, autora de “Artificial Intelligence: A Guide for Thinking Humans” (inteligência artificial: um guia para humanos pensantes), twittou: “É sabido desde sempre que os humanos estão predispostos a antropomorfizar mesmo com os sinais mais superficiais. . . Os engenheiros do Google também são humanos e não imunes”.
Stephen Pinker, de Harvard, acrescentou que Lemoine “não entende a diferença entre senciência (também conhecida como subjetividade, experiência), inteligência e autoconhecimento”. Ele acrescentou: “Não há evidências de que seus modelos de linguagem tenham algum deles”.
Outros foram mais solidários. Ron Jeffries, um conhecido desenvolvedor de software, chamou o tópico de “profundo” e acrescentou: “Suspeito que não haja uma fronteira rígida entre senciente e não senciente”.
In Discriminating Data: Correlation, Neighborhoods, and the New Politics of Recognition, Wendy Hui Kyong Chun explores how technological developments around data are amplifying and automating discrimination and prejudice. Through conceptual innovation and historical details, this book offers engaging and revealing insights into how data exacerbates discrimination in powerful ways, writes David Beer.
Discriminating Data: Correlation, Neighborhoods, and the New Politics of Recognition. Wendy Hui Kyong Chun (mathematical illustrations by Alex Barnett). MIT Press. 2021.
Going back a couple of decades, there was a fair amount of discussion of ‘the digital divide’. Uneven access to networked computers meant that a line was drawn between those who were able to switch-on and those who were not. At the time there was a pressing concern about the disadvantages of a lack of access. With the massive escalation of connectivity since, the notion of a digital divide still has some relevance, but it has become a fairly blunt tool for understanding today’s extensively mediated social constellations. The divides now are not so much a product of access; they are instead a consequence of what happens to the data produced through that access.
With the escalation of data and the establishment of all sorts of analytic and algorithmic processes, the problem of uneven, unjust and harmful treatment is now the focal point for an animated and urgent debate. Wendy Hui Kyong Chun’s vibrant new book Discriminating Data: Correlation, Neighborhoods, and the New Politics of Recognitionmakes a telling intervention. At its centre is the idea that these technological developments around data ‘are amplifying and automating – rather than acknowledging and repairing – the mistakes of a discriminatory past’ (2). Essentially this is the codification and automation of prejudice. Any ideas about the liberating aspects of technology are deflated. Rooted in a longer history of statistics and biometrics, existing ruptures are being torn open by the differential targeting that big data brings.
This is not just about bits of data. Chun suggests that ‘we need […] to understand how machine learning and other algorithms have been embedded with human prejudice and discrimination, not simply at the level of data, but also at the levels of procedure, prediction, and logic’ (16). It is not, then, just about prejudice being in the data itself; it is also how segregation and discrimination are embedded in the way this data is used. Given the scale of these issues, Chun narrows things down further by focusing on four ‘foundational concepts’, with correlation, homophily, authenticity and recognition providing the focal points for interrogating the discriminations of data.
It is the concept of correlation that does much of the gluing work within the study. The centrality of correlation is a subtext in Chun’s own overview of the book, which suggests that ‘Discriminating Data reveals how correlation and eugenic understandings of nature seek to close off the future by operationalizing probabilities; how homophily naturalizes segregation; and how authenticity and recognition foster deviation in order to create agitated clusters of comforting rage’ (27). As well as developing these lines of argument, the use of the concept of correlation also allows Chun to think in deeply historical terms about the trajectory and politics of association and patterning.
For Chun the role of correlation is both complex and performative. It is argued, for instance, that correlations ‘do not simply predict certain actions; they also form them’. This is an established position in the field of critical data studies, with data prescribing and producing the outcomes they are used to anticipate. However, Chun manages to reanimate this position through an exploration of how correlation fits into a wider set of discriminatory data practices. The other performative issue here is the way that people are made-up and grouped through the use of data. Correlations, Chun writes, ‘that lump people into categories based on their being “like” one another amplify the effects of historical inequalities’ (58). Inequalities are reinforced as categories become more obdurate, with data lending them a sense of apparent stability and a veneer of objectivity. Hence the pointed claim that ‘correlation contains within it the seeds of manipulation, segregation and misrepresentation’ (59).
Given this use of data to categorise, it is easy to see why Discriminating Data makes a conceptual link between correlation and homophily – with homophily, as Chun puts it, being the ‘principle that similarity breeds connection’ and can therefore lead to swarming and clustering. The acts of grouping within these data structures mean, for Chun, that ‘homophily not only eases conflict; it also naturalizes discrimination’ (103). Using data correlations to group informs a type of homophily that not only misrepresents and segregates; it also makes these divides seem natural and therefore fixed.
Chun anticipates that there may be some remaining remnants of faith in the seeming democratic properties of these platforms, arguing that ‘homophily reveals and creates boundaries within theoretically flat and diffuse social networks; it distinguishes and discriminates between supposedly equal nodes; it is a tool for discovering bias and inequality and for perpetuating them in the name of “comfort,” predictability, and common sense’ (85). As individuals are moved into categories or groups assumed to be like them, based upon the correlations within their data, so discrimination can readily occur. One of the key observations made by Chun is that data homophily can feel comfortable, especially when encased in predictions, yet this can distract from the actual damages of the underpinning discriminations they contain. Instead, these data ‘proxies can serve to buttress – and justify – discrimination’ (121). For Chun there is a ‘proxy politics’ unfolding in which data not only exacerbates but can also be used to lend legitimacy to discriminatory acts.
As with correlation and homophily, Chun, in a particularly novel twist, also explores how authenticity is itself becoming automated within these data structures. In stark terms, it is argued that ‘authenticity has become so central to our times because it has become algorithmic’ (144). Chun is able to show how a wider cultural push towards notions of the authentic, embodied in things like reality TV, becomes a part of data systems. A broader cultural trend is translated into something renderable in data. Chun explains that the ‘term “algorithmic authenticity” reveals the ways in which users are validated and authenticated by network algorithms’ (144). A system of validation occurs in these spaces, where actions and practices are algorithmically judged and authenticated. Algorithmic authenticity ‘trains them to be transparent’ (241). It pushes a form of openness upon us in which an ‘operationalized authenticity’ develops, especially within social media.
This emphasis upon the authentic draws people into certain types of interaction with these systems. It shows, Chun compellingly puts it, ‘how users have become characters in a drama called “big data”’ (145). The notion of a drama is, of course, not to diminish what is happening but to try to get at its vibrant and role-based nature. It also adds a strong sense of how performance plays out in relation to the broader ideas of data judgment that the book is exploring.
These roles are not something that Chun wants us to accept, arguing instead that ‘if we think through our roles as performers and characters in the drama called “big data,” we do not have to accept the current terms of our deployment’ (170). Examining the artifice of the drama is a means of transformation and challenge. Exposing the drama is to expose the roles and scripts that are in place, enabling them to be questioned and possibly undone. This is not fatalistic or absent of agency; rather, Chun’s point is that ‘we are characters, rather than marionettes’ (248).
There are some powerful cross-currents working through the discussions of the book’s four foundational concepts. The suggestion that big data brings a reversal of hegemony is a particularly telling argument. Chun explains that: ‘Power can now operate through reverse hegemony: if hegemony once meant the creation of a majority by various minorities accepting a dominant worldview […], now hegemonic majorities can emerge when angry minorities, clustered around a shared stigma, are strung together through their mutual opposition to so-called mainstream culture’ (34). This line of argument is echoed in similar terms in the book’s conclusion, clarifying further that ‘this is hegemony in reverse: if hegemony once entailed creating a majority by various minorities accepting – and identifying with – a dominant worldview, majorities now emerge by consolidating angry minorities – each attached to a particular stigma – through their opposition to “mainstream” culture’ (243). In this formulation it would seem that big data may not only be disciplinary but may also somehow gain power by upending any semblance of a dominant ideology. Data doesn’t lead to shared ideas but to the splitting of the sharing of ideas into group-based networks. It does seem plausible that the practices of targeting and patterning through data are unlikely to facilitate hegemony. Yet, it is not just that data affords power beyond hegemony but that it actually seeks to reverse it.
The reader may be caught slightly off-guard by this position. Chun generally seems to picture power as emerging and solidifying through a genealogy of the technologies that have formed into contemporary data infrastructures. In this account power seems to be associated with established structures and operates through correlations, calls for authenticity and the means of recognition. These positions on power – with infrastructures on one side and reverse hegemony on the other – are not necessarily incompatible, yet the discussion of reverse hegemony perhaps stands a little outside of that other vision of power. I was left wondering if this reverse hegemony is a consequence of these more processional operations of power or, maybe, it is a kind of facilitator of them.
Chun’s book looks to bring out the deep divisions that data-informed discrimination has already created and will continue to create. The conceptual innovation and the historical details, particularly on statistics and eugenics, lend the book a deep sense of context that feeds into a range of genuinely engaging and revealing insights and ideas. Through its careful examination of the way that data exacerbates discrimination in very powerful ways, this is perhaps the most telling book yet on the topic. The digital divide may no longer be a particularly useful term but, as Chun’s book makes clear, the role data performs in animating discrimination means that the technological facilitation of divisions has never been more pertinent.
The Three Million African Genomes (3MAG) project emerged from his work on how genetic mutations among Africans contribute to conditions like sickle-cell disease and hearing impairments.
He points out that African genes hold a wealth of genetic variation, beyond that observed by scientists in Europe and elsewhere.
“We are all African but only a small fraction of Africans moved out of Africa about 20-40,000 years ago and settled in Europe and in Asia,” he says.
Only about 2% of the human genomes that have been mapped are African
Prof Wonkam is also concerned about equity. “Too little of the knowledge and applications from genomics have benefited the global south because of inequalities in health-care systems, a small local research workforce and lack of funding,” he says.
Only about 2% of the genomes mapped globally are African, and a good proportion of these are African American. This comes from a lack of prioritising funding, policies and training infrastructure, he says, but it also means the understanding of genetic medicine as a whole is lopsided.
Studies of African genomes will also help to correct injustices, he says: “Estimates of genetic risk scores for people of African descent that predict, say, the likelihood of cardiomyopathies or schizophrenia can be unreliable or even misleading using tools that work well in Europeans.”
To address these inequities, Prof Wonkam and other scientists are talking to governments, companies and professional bodies across Africa and internationally, in order to build up capacity over the next decade to make the vision a reality.
Estimates of genetic risk scores for people of African descent can be unreliable, says Prof Wonkam
The number of three million is the minimum he expects to accurately map genetic variations across Africa. As a comparison, the UK Biobank currently aims to sequence half a million genomes in under three years, but the UK’s 68 million population is just a fraction of Africa’s 1.3 billion.
Prof Wonkam says the project will take 10 years, and will cost around $450m (£335m) per year, and says industry is already showing an interest in it.
Biotech firms say they welcome any expansion of the library of African genomes.
The Centre for Proteomic and Genomic Research (CPGR) in Cape Town works with biotech firm Artisan Biomed on a variety of diagnostic tests. The firm says it is affected by the gaps in the availability of genomic information relevant to local populations.
For example, it may find a genetic mutation in someone and not know for certain if that variation is associated with a disease, especially as a marker for that particular population.
The Centre for Proteomic and Genomic Research works with private firms to further their research
“The more information you have at that level, the better the diagnosis, treatment and eventually care can be for any individual, regardless of your ethnicity,” says Dr Lindsay Petersen, chief operations officer.
Artisan Biomed says the data it collects feeds back into CPGR’s research – allowing them to design a better diagnostic toolkit that is better suited to African populations, for instance.
“Because of the limited data sets of the African genome, it needs that hand in hand connection with research and innovation, because without that it’s just another test that has been designed for a Caucasian population that may or may not have much of an effect within the African populations,” says Dr Judith Hornby Cuff.
She says the 3MAG project would help streamline processes and improve the development of research, and perhaps one day provide cheaper, more effective and more accessible health care, particularly in the strained South African system.
Dr Aron Abera hopes his company can build labs and train staff outside South Africa
One of those hoping to take part in the 3MAG project is Dr Aron Abera, genomics scientist at Inqaba Biotech in Pretoria, which offers genetic sequencing and other services to research and industry.
The firm employs over 100 people in South Africa, Ghana, Kenya, Mali, Nigeria Senegal, Tanzania, Uganda and Zimbabwe. Currently, most of the genetics samples collected in these countries are still processed in South Africa, but Dr Abera hopes to increase the number of laboratories soon.
The gaps are not only in infrastructure, but also in staff. Over the last 20 years, Inqaba has focused on using staff and interns from the African continent – but it now has to expand its training programme as well.
Back in Cape Town, Prof Wonkam says that while the costs are huge, the project will “improve capacity in a whole range of biomedical disciplines that will equip Africa to tackle public-health challenges more equitably”.
He says: “We have to be ambitious when we are in Africa. You have so many challenges you cannot see small, you have to see big – and really big.”
Summary: Researchers are challenging a long-held assumption that there is a trade-off between accuracy and fairness when using machine learning to make public policy decisions.
Carnegie Mellon University researchers are challenging a long-held assumption that there is a trade-off between accuracy and fairness when using machine learning to make public policy decisions.
As the use of machine learning has increased in areas such as criminal justice, hiring, health care delivery and social service interventions, concerns have grown over whether such applications introduce new or amplify existing inequities, especially among racial minorities and people with economic disadvantages. To guard against this bias, adjustments are made to the data, labels, model training, scoring systems and other aspects of the machine learning system. The underlying theoretical assumption is that these adjustments make the system less accurate.
A CMU team aims to dispel that assumption in a new study, recently published in Nature Machine Intelligence. Rayid Ghani, a professor in the School of Computer Science’s Machine Learning Department (MLD) and the Heinz College of Information Systems and Public Policy; Kit Rodolfa, a research scientist in MLD; and Hemank Lamba, a post-doctoral researcher in SCS, tested that assumption in real-world applications and found the trade-off was negligible in practice across a range of policy domains.
“You actually can get both. You don’t have to sacrifice accuracy to build systems that are fair and equitable,” Ghani said. “But it does require you to deliberately design systems to be fair and equitable. Off-the-shelf systems won’t work.”
Ghani and Rodolfa focused on situations where in-demand resources are limited, and machine learning systems are used to help allocate those resources. The researchers looked at systems in four areas: prioritizing limited mental health care outreach based on a person’s risk of returning to jail to reduce reincarceration; predicting serious safety violations to better deploy a city’s limited housing inspectors; modeling the risk of students not graduating from high school in time to identify those most in need of additional support; and helping teachers reach crowdfunding goals for classroom needs.
In each context, the researchers found that models optimized for accuracy — standard practice for machine learning — could effectively predict the outcomes of interest but exhibited considerable disparities in recommendations for interventions. However, when the researchers applied adjustments to the outputs of the models that targeted improving their fairness, they discovered that disparities based on race, age or income — depending on the situation — could be removed without a loss of accuracy.
Ghani and Rodolfa hope this research will start to change the minds of fellow researchers and policymakers as they consider the use of machine learning in decision making.
“We want the artificial intelligence, computer science and machine learning communities to stop accepting this assumption of a trade-off between accuracy and fairness and to start intentionally designing systems that maximize both,” Rodolfa said. “We hope policymakers will embrace machine learning as a tool in their decision making to help them achieve equitable outcomes.”
Frances Haugen’s testimony at the Senate hearing today raised serious questions about how Facebook’s algorithms work—and echoes many findings from our previous investigation.
October 5, 2021
Karen Hao
Facebook whistleblower Frances Haugen testifies during a Senate Committee October 5. Drew Angerer/Getty Images
On Sunday night, the primary source for the Wall Street Journal’s Facebook Files, an investigative series based on internal Facebook documents, revealed her identity in an episode of 60 Minutes.
Frances Haugen, a former product manager at the company, says she came forward after she saw Facebook’s leadership repeatedly prioritize profit over safety.
Before quitting in May of this year, she combed through Facebook Workplace, the company’s internal employee social media network, and gathered a wide swath of internal reports and research in an attempt to conclusively demonstrate that Facebook had willfully chosen not to fix the problems on its platform.
Today she testified in front of the Senate on the impact of Facebook on society. She reiterated many of the findings from the internal research and implored Congress to act.
“I’m here today because I believe Facebook’s products harm children, stoke division, and weaken our democracy,” she said in her opening statement to lawmakers. “These problems are solvable. A safer, free-speech respecting, more enjoyable social media is possible. But there is one thing that I hope everyone takes away from these disclosures, it is that Facebook can change, but is clearly not going to do so on its own.”
During her testimony, Haugen particularly blamed Facebook’s algorithm and platform design decisions for many of its issues. This is a notable shift from the existing focus of policymakers on Facebook’s content policy and censorship—what does and doesn’t belong on Facebook. Many experts believe that this narrow view leads to a whack-a-mole strategy that misses the bigger picture.
“I’m a strong advocate for non-content-based solutions, because those solutions will protect the most vulnerable people in the world,” Haugen said, pointing to Facebook’s uneven ability to enforce its content policy in languages other than English.
Haugen’s testimony echoes many of the findings from an MIT Technology Review investigation published earlier this year, which drew upon dozens of interviews with Facebook executives, current and former employees, industry peers, and external experts. We pulled together the most relevant parts of our investigation and other reporting to give more context to Haugen’s testimony.
How does Facebook’s algorithm work?
Colloquially, we use the term “Facebook’s algorithm” as though there’s only one. In fact, Facebook decides how to target ads and rank content based on hundreds, perhaps thousands, of algorithms. Some of those algorithms tease out a user’s preferences and boost that kind of content up the user’s news feed. Others are for detecting specific types of bad content, like nudity, spam, or clickbait headlines, and deleting or pushing them down the feed.
All of these algorithms are known as machine-learning algorithms. As I wrote earlier this year:
Unlike traditional algorithms, which are hard-coded by engineers, machine-learning algorithms “train” on input data to learn the correlations within it. The trained algorithm, known as a machine-learning model, can then automate future decisions. An algorithm trained on ad click data, for example, might learn that women click on ads for yoga leggings more often than men. The resultant model will then serve more of those ads to women.
And because of Facebook’s enormous amounts of user data, it can
develop models that learned to infer the existence not only of broad categories like “women” and “men,” but of very fine-grained categories like “women between 25 and 34 who liked Facebook pages related to yoga,” and [target] ads to them. The finer-grained the targeting, the better the chance of a click, which would give advertisers more bang for their buck.
The same principles apply for ranking content in news feed:
Just as algorithms [can] be trained to predict who would click what ad, they [can] also be trained to predict who would like or share what post, and then give those posts more prominence. If the model determined that a person really liked dogs, for instance, friends’ posts about dogs would appear higher up on that user’s news feed.
Before Facebook began using machine-learning algorithms, teams used design tactics to increase engagement. They’d experiment with things like the color of a button or the frequency of notifications to keep users coming back to the platform. But machine-learning algorithms create a much more powerful feedback loop. Not only can they personalize what each user sees, they will also continue to evolve with a user’s shifting preferences, perpetually showing each person what will keep them most engaged.
Who runs Facebook’s algorithm?
Within Facebook, there’s no one team in charge of this content-ranking system in its entirety. Engineers develop and add their own machine-learning models into the mix, based on their team’s objectives. For example, teams focused on removing or demoting bad content, known as the integrity teams, will only train models for detecting different types of bad content.
This was a decision Facebook made early on as part of its “move fast and break things” culture. It developed an internal tool known as FBLearner Flow that made it easy for engineers without machine learning experience to develop whatever models they needed at their disposal. By one data point, it was already in use by more than a quarter of Facebook’s engineering team in 2016.
Many of the current and former Facebook employees I’ve spoken to say that this is part of why Facebook can’t seem to get a handle on what it serves up to users in the news feed. Different teams can have competing objectives, and the system has grown so complex and unwieldy that no one can keep track anymore of all of its different components.
As a result, the company’s main process for quality control is through experimentation and measurement. As I wrote:
Teams train up a new machine-learning model on FBLearner, whether to change the ranking order of posts or to better catch content that violates Facebook’s community standards (its rules on what is and isn’t allowed on the platform). Then they test the new model on a small subset of Facebook’s users to measure how it changes engagement metrics, such as the number of likes, comments, and shares, says Krishna Gade, who served as the engineering manager for news feed from 2016 to 2018.
If a model reduces engagement too much, it’s discarded. Otherwise, it’s deployed and continually monitored. On Twitter, Gade explained that his engineers would get notifications every few days when metrics such as likes or comments were down. Then they’d decipher what had caused the problem and whether any models needed retraining.
How has Facebook’s content ranking led to the spread of misinformation and hate speech?
During her testimony, Haugen repeatedly came back to the idea that Facebook’s algorithm incites misinformation, hate speech, and even ethnic violence.
“Facebook … knows—they have admitted in public—that engagement-based ranking is dangerous without integrity and security systems but then not rolled out those integrity and security systems in most of the languages in the world,” she told the Senate today. “It is pulling families apart. And in places like Ethiopia it is literally fanning ethnic violence.”
Here’s what I’ve written about this previously:
The machine-learning models that maximize engagement also favor controversy, misinformation, and extremism: put simply, people just like outrageous stuff.
Sometimes this inflames existing political tensions. The most devastating example to date is the case of Myanmar, where viral fake news and hate speech about the Rohingya Muslim minority escalated the country’s religious conflict into a full-blown genocide. Facebook admitted in 2018, after years of downplaying its role, that it had not done enough “to help prevent our platform from being used to foment division and incite offline violence.”
As Haugen mentioned, Facebook has also known this for a while. Previous reporting has found that it’s been studying the phenomenon since at least 2016.
In an internal presentation from that year, reviewed by the Wall Street Journal, a company researcher, Monica Lee, found that Facebook was not only hosting a large number of extremist groups but also promoting them to its users: “64% of all extremist group joins are due to our recommendation tools,” the presentation said, predominantly thanks to the models behind the “Groups You Should Join” and “Discover” features.
In 2017, Chris Cox, Facebook’s longtime chief product officer, formed a new task force to understand whether maximizing user engagement on Facebook was contributing to political polarization. It found that there was indeed a correlation, and that reducing polarization would mean taking a hit on engagement. In a mid-2018 document reviewed by the Journal, the task force proposed several potential fixes, such as tweaking the recommendation algorithms to suggest a more diverse range of groups for people to join. But it acknowledged that some of the ideas were “antigrowth.” Most of the proposals didn’t move forward, and the task force disbanded.
In my own conversations, Facebook employees also corroborated these findings.
A former Facebook AI researcher who joined in 2018 says he and his team conducted “study after study” confirming the same basic idea: models that maximize engagement increase polarization. They could easily track how strongly users agreed or disagreed on different issues, what content they liked to engage with, and how their stances changed as a result. Regardless of the issue, the models learned to feed users increasingly extreme viewpoints. “Over time they measurably become more polarized,” he says.
In her testimony, Haugen also repeatedly emphasized how these phenomena are far worse in regions that don’t speak English because of Facebook’s uneven coverage of different languages.
“In the case of Ethiopia there are 100 million people and six languages. Facebook only supports two of those languages for integrity systems,” she said. “This strategy of focusing on language-specific, content-specific systems for AI to save us is doomed to fail.”
She continued: “So investing in non-content-based ways to slow the platform down not only protects our freedom of speech, it protects people’s lives.”
I explore this more in a different article from earlier this year on the limitations of large language models, or LLMs:
Despite LLMs having these linguistic deficiencies, Facebook relies heavily on them to automate its content moderation globally. When the war in Tigray[, Ethiopia] first broke out in November, [AI ethics researcher Timnit] Gebru saw the platform flounder to get a handle on the flurry of misinformation. This is emblematic of a persistent pattern that researchers have observed in content moderation. Communities that speak languages not prioritized by Silicon Valley suffer the most hostile digital environments.
Gebru noted that this isn’t where the harm ends, either. When fake news, hate speech, and even death threats aren’t moderated out, they are then scraped as training data to build the next generation of LLMs. And those models, parroting back what they’re trained on, end up regurgitating these toxic linguistic patterns on the internet.
How does Facebook’s content ranking relate to teen mental health?
One of the more shocking revelations from the Journal’s Facebook Files was Instagram’s internal research, which found that its platform is worsening mental health among teenage girls. “Thirty-two percent of teen girls said that when they felt bad about their bodies, Instagram made them feel worse,” researchers wrote in a slide presentation from March 2020.
Haugen connects this phenomenon to engagement-based ranking systems as well, which she told the Senate today “is causing teenagers to be exposed to more anorexia content.”
“If Instagram is such a positive force, have we seen a golden age of teenage mental health in the last 10 years? No, we have seen escalating rates of suicide and depression amongst teenagers,” she continued. “There’s a broad swath of research that supports the idea that the usage of social media amplifies the risk of these mental health harms.”
In my own reporting, I heard from a former AI researcher who also saw this effect extend to Facebook.
The researcher’s team…found that users with a tendency to post or engage with melancholy content—a possible sign of depression—could easily spiral into consuming increasingly negative material that risked further worsening their mental health.
But as with Haugen, the researcher found that leadership wasn’t interested in making fundamental algorithmic changes.
The team proposed tweaking the content-ranking models for these users to stop maximizing engagement alone, so they would be shown less of the depressing stuff. “The question for leadership was: Should we be optimizing for engagement if you find that somebody is in a vulnerable state of mind?” he remembers.
But anything that reduced engagement, even for reasons such as not exacerbating someone’s depression, led to a lot of hemming and hawing among leadership. With their performance reviews and salaries tied to the successful completion of projects, employees quickly learned to drop those that received pushback and continue working on those dictated from the top down….
That former employee, meanwhile, no longer lets his daughter use Facebook.
How do we fix this?
Haugen is against breaking up Facebook or repealing Section 230 of the US Communications Decency Act, which protects tech platforms from taking responsibility for the content it distributes.
Instead, she recommends carving out a more targeted exemption in Section 230 for algorithmic ranking, which she argues would “get rid of the engagement-based ranking.” She also advocates for a return to Facebook’s chronological news feed.
Ellery Roberts Biddle, a projects director at Ranking Digital Rights, a nonprofit that studies social media ranking systems and their impact on human rights, says a Section 230 carve-out would need to be vetted carefully: “I think it would have a narrow implication. I don’t think it would quite achieve what we might hope for.”
In order for such a carve-out to be actionable, she says, policymakers and the public would need to have a much greater level of transparency into how Facebook’s ad-targeting and content-ranking systems even work. “I understand Haugen’s intention—it makes sense,” she says. “But it’s tough. We haven’t actually answered the question of transparency around algorithms yet. There’s a lot more to do.”
Nonetheless, Haugen’s revelations and testimony have brought renewed attention to what many experts and Facebook employees have been saying for years: that unless Facebook changes the fundamental design of its algorithms, it will not make a meaningful dent in the platform’s issues.
Her intervention also raises the prospect that if Facebook cannot put its own house in order, policymakers may force the issue.
“Congress can change the rules that Facebook plays by and stop the many harms it is now causing,” Haugen told the Senate. “I came forward at great personal risk because I believe we still have time to act, but we must act now.”
Americano Joshua Walker defende que decisões judiciais nunca sejam automatizadas
Identificar as melhores práticas e quais fatores influenciaram decisões judiciais são alguns dos exemplos de como o uso da inteligência artificial pode beneficiar o sistema de Justiça e, consequentemente, a população, afirma o advogado americano Joshua Walker.
Um dos fundadores do CodeX, centro de informática legal da Universidade de Stanford (EUA) —onde também lecionou— e fundador da Lex Machina, empresa pioneira no segmento jurídico tecnológico, Walker iniciou a carreira no mundo dos dados há mais de 20 anos, trabalhando com processos do genocídio de 1994 em Ruanda, que matou ao menos 800 mil pessoas em cem dias.
Autor do livro “On Legal AI: Um Rápido Tratado sobre a Inteligência Artificial no Direito” (Revista dos Tribunais, 2021), no qual fala sobre como softwares de análise podem ser usados na busca de soluções no direito, Walker palestrou sobre o tema na edição da Fenalaw —evento sobre uso da tecnologia por advogados.
Em entrevista à Folha por email, ele defende que os advogados não só aprendam a usar recursos de inteligência artificial, como também assumam o protagonismo nos processos de desenvolvimento de tecnologias voltadas ao direito.
“Nós [advogados] precisamos começar a nos tornar cocriadores porque, enquanto os engenheiros de software se lembram dos dados, nós nos lembramos da estória e das histórias”, afirma.
Ao longo de sua carreira, quais tabus foram superados e quais continuam quando o assunto é inteligência artificial? Como confrontar essas ideias? Tabus existem em abundância. Há mais e novos todos os dias. Você tem que se perguntar duas coisas: o que meus clientes precisam? E como posso ser —um ou o— melhor no que faço para ajudar meus clientes? Isso é tudo que você precisa se preocupar para “inovar”.
A tradição jurídica exige que nos adaptemos, e nos adaptemos rapidamente, porque temos: a) o dever de lealdade de ajudar nossos clientes com os melhores meios disponíveis; b) o dever de melhorar a prática e a administração da lei e do próprio sistema.
A inteligência artificial legal e outras técnicas básicas de outros campos podem impulsionar de forma massiva ambas as áreas. Para isso, o dever de competência profissional nos exige conhecimentos operacionais e sobre as plataformas, que são muito úteis para serem ignorados. Isso não significa que você deve adotar tudo. Seja cético.
Estamos aprendendo a classificar desafios humanos complexos em estruturas processuais que otimizam os resultados para todos os cidadãos, de qualquer origem. Estamos aprendendo qual impacto as diferentes regras locais se correlacionam com diferentes classes de resultados de casos. Estamos apenas começando.
FolhaJus
Seleção das principais notícias da semana sobre o cenário jurídico e conteúdos exclusivos com entrevistas e infográficos.
O sr. começou a trabalhar com análise de dados por causa do genocídio de Ruanda. O que aquela experiência lhe ensinou sobre as possibilidades e limites do trabalho com bancos de dados? O que me ensinou é que a arquitetura da informação é mais importante do que o número de doutores, consultores ou milhões de dólares do orçamento de TI (tecnologia da informação) que você tem à sua disposição.
Você tem que combinar a infraestrutura de TI, o design de dados, com o objetivo da equipe e da empresa. A empresa humana, seu cliente (e para nós eram os mortos) está em primeiro lugar. Todo o resto é uma variável dependente.
Talento, orçamento etc. são muito importantes. Mas você não precisa necessariamente de dinheiro para obter resultados sérios.
Como avalia o termo inteligência artificial? Como superar a estranheza que ele gera? É basicamente um meme de marketing que foi usado para inspirar financiadores a investir em projetos de ciência da computação, começando há muitas décadas. Uma boa descrição comercial de inteligência artificial —mais prática e menos jargão— é: software que faz análise. Tecnicamente falando, inteligência artificial é: dados mais matemática.
Se seus dados são terríveis, a IA resultante também o será. Se são tendenciosos, ou contêm comunicação abusiva, o resultado também será assim.
Esse é um dos motivos de tantas empresas de tecnologia jurídica e operações jurídicas dominadas pela engenharia fracassarem de forma tão espetacular. Você precisa de advogados altamente qualificados, técnicos, matemáticos e advogados céticos para desenvolver a melhor tecnologia/matemática.
Definir IA de forma mais simples também implica, precisamente, que cada inteligência artificial é única, como uma criança. Ela sempre está se desenvolvendo, mudando etc. Esta é a maneira de pensar sobre isso. E, como acontece com as crianças, você pode ensinar, mas nenhum pai pode controlar operacionalmente um filho, além de um certo limite.
Como o uso de dados pode ampliar o acesso à Justiça e torná-lo mais ágil? Nunca entendi muito bem o que significa o termo “acesso à Justiça”. Talvez seja porque a maioria das pessoas, de todas as origens socioeconômicas e étnicas, compartilha a experiência comum de não ter esse acesso.
Posso fazer analogias com outras áreas, porém. Um pedaço de software tem um custo marginal de aproximadamente zero. Cada vez que um de nós usa uma ferramenta de busca, ela não nos custa o investimento que foi necessário para fazer esse software e sofisticá-lo. Há grandes custos fixos, mas baixo custo por usuário.
Essa é a razão pela qual o software é um ótimo negócio. Se bem governado, podemos torná-lo um modus operandi ainda melhor para um país moderno. Isso supondo que possamos evitar todos os pesadelos que podem acontecer!
Podemos criar software de inteligência artificial legal que ajuda todas as pessoas em um país inteiro. Esse software pode ser perfeitamente personalizado e tornar-se fiel a cada indivíduo. Pode custar quase zero por cada operação incremental.
Eu criei um pacote de metodologias chamado Citizen’s AI Lab (laboratório de IA dos cidadãos) que será levado a muitos países ao redor do mundo, incluindo o Brasil, se as pessoas quiserem colocá-lo para funcionar. Vai fazer exatamente isso. Novamente, esses sistemas não apenas podem ser usados para cada operação (uso) de cada indivíduo, mas também para cada país.
FolhaJus Dia
Seleção diária das principais notícias sobre o cenário jurídico em diferentes áreas
Em quais situações não é recomendado que a Justiça use IA? Nunca para a própria tomada de decisão. Neste momento, em qualquer caso, e/ou em minha opinião, não é possível e nem desejável automatizar a tomada de decisões judiciais.
Por outro lado, juízes podem sempre se beneficiar com a inteligência artificial. Quais são as melhores práticas? Quantos casos um determinado juiz tem em sua pauta? Ou em todo o tribunal? Como isso se compara a outros tribunais e como os resultados poderiam ser diferentes por causa dos casos ou do cenário econômico, político ou outros fatores?
Há protocolos que ajudam as partes a obter uma resolução antecipada de disputas? Esses resultados são justos?, uma questão humana possibilitada por uma base ou plataforma empírica auxiliada por IA. Ou os resultados são apenas impulsionados pelo acesso relativo aos fundos de litígio pelos litigantes?
Como estruturamos as coisas para que tenhamos menos disputas estúpidas nos tribunais? Quais advogados apresentam os comportamentos de arquivamento mais malignos e abusivos em todos os tribunais? Como a lei deve ser regulamentada?
Essas são perguntas que não podemos nem começar a fazer sem IA —leia-se: matemática— para nos ajudar a analisar grandes quantidades de dados.
Quais são os limites éticos para o uso de bancos de dados? Como evitar abusos? Uma boa revisão legal é essencial para todo projeto de inteligência artificial e dados que tenha um impacto material na humanidade. Mas para fazer isso em escala, nós, os advogados, também precisamos de mecanismos legais de revisão de IA.
Apoio muito o trabalho atual da inteligência artificial ética. Infelizmente, nos Estados Unidos, e talvez em outros lugares, a “IA ética” é uma espécie de “falsa questão” para impedir os advogados de se intrometerem em projetos de engenharia lucrativos e divertidos. Isso tem sido um desastre político, operacional e comercial em muitos casos.
Nós [advogados] precisamos começar a nos tornar cocriadores porque, enquanto os engenheiros de software se lembram dos dados, nós nos lembramos da estória e das histórias. Nós somos os leitores. Nossas IAs estão imbuídas de um tipo diferente de sentido, evoluíram de um tipo diferente de educação. Cientistas da computação e advogados/estudiosos do direito estão intimamente alinhados, mas nosso trabalho precisa ser o de guardiões da memória social.
Pesquisa Datafolha com advogados brasileiros mostrou que apenas 29% dos 303 entrevistados usavam recursos de IA no dia a dia. Como é nos EUA? O que é necessário para avançar mais? O que observei no “microclima” da tecnologia legal de São Paulo foi que o “tabu” contra o uso de tecnologia legal foi praticamente eliminado. Claro, isso é um microclima e pode não ser representativo ou ser contrarrepresentativo. Mas as pessoas podem estar usando IA todos os dias na prática, sem estar cientes disso. Os motores de busca são um exemplo muito simples. Temos que saber o que é algo antes de saber o quanto realmente o usamos.
Nos EUA: suspeito que o uso ainda esteja no primeiro “trimestre” do jogo em aplicações de IA para a lei. Litígio e contrato são casos de uso razoavelmente estabelecidos. Na verdade, eu não acho que você pode ser um advogado de propriedade intelectual de nível nacional sem o impulsionamento de alguma forma de dados empíricos.
Ainda são raros cursos de análise de dados para estudantes de direito no Brasil. Diante dessa lacuna, o que os profissionais devem fazer para se adaptar a essa nova realidade? Qual é o risco para quem não fizer nada? Eu começaria ensinando processo cívil com dados. Essa é a regra, é assim que as pessoas aplicam a regra (o que arquivam), e o que acontece quando o fazem (consequências). Isso seria revolucionário. Alunos, professores e doutores podem desenvolver todos os tipos de estudos e utilidades sociais.
Existem inúmeros outros exemplos. Os acadêmicos precisam conduzir isso em parceria com juízes, reguladores, a imprensa e a Ordem dos Advogados.
Na verdade, meu melhor conselho para os novos alunos é: assuma que todos os dados são falsos até prova em contrário. E quanto mais sofisticada a forma, mais volumosa a definição, mais para se aprofundar.
RAIO X
Joshua Walker
Autor do livro “On Legal AI – Um Rápido Tratado sobre a Inteligência Artificial no Direito” (Revista dos Tribunais, 2021) e diretor da empresa Aon IPS. Graduado em Havard e doutor pela Faculdade de Direito da Universidade de Chicago, foi cofundador do CodeX, centro de informática legal da Universidade de Stanford, e fundador da Lex Machina, empresa pioneira do segmento jurídico tecnológico. Também lecionou nas universidades de Stanford e Berkeley
Joaquin Quiñonero Candela, a director of AI at Facebook, was apologizing to his audience.
It was March 23, 2018, just days after the revelation that Cambridge Analytica, a consultancy that worked on Donald Trump’s 2016 presidential election campaign, had surreptitiously siphoned the personal data of tens of millions of Americans from their Facebook accounts in an attempt to influence how they voted. It was the biggest privacy breach in Facebook’s history, and Quiñonero had been previously scheduled to speak at a conference on, among other things, “the intersection of AI, ethics, and privacy” at the company. He considered canceling, but after debating it with his communications director, he’d kept his allotted time.
As he stepped up to face the room, he began with an admission. “I’ve just had the hardest five days in my tenure at Facebook,” he remembers saying. “If there’s criticism, I’ll accept it.”
The Cambridge Analytica scandal would kick off Facebook’s largest publicity crisis ever. It compounded fears that the algorithms that determine what people see on the platform were amplifying fake news and hate speech, and that Russian hackers had weaponized them to try to sway the election in Trump’s favor. Millions began deleting the app; employees left in protest; the company’s market capitalization plunged by more than $100 billion after its July earnings call.
In the ensuing months, Mark Zuckerberg began his own apologizing. He apologized for not taking “a broad enough view” of Facebook’s responsibilities, and for his mistakes as a CEO. Internally, Sheryl Sandberg, the chief operating officer, kicked off a two-year civil rights audit to recommend ways the company could prevent the use of its platform to undermine democracy.
Finally, Mike Schroepfer, Facebook’s chief technology officer, asked Quiñonero to start a team with a directive that was a little vague: to examine the societal impact of the company’s algorithms. The group named itself the Society and AI Lab (SAIL); last year it combined with another team working on issues of data privacy to form Responsible AI.
Quiñonero was a natural pick for the job. He, as much as anybody, was the one responsible for Facebook’s position as an AI powerhouse. In his six years at Facebook, he’d created some of the first algorithms for targeting users with content precisely tailored to their interests, and then he’d diffused those algorithms across the company. Now his mandate would be to make them less harmful.
Facebook has consistently pointed to the efforts by Quiñonero and others as it seeks to repair its reputation. It regularly trots out various leaders to speak to the media about the ongoing reforms. In May of 2019, it granted a series of interviews with Schroepfer to the New York Times, which rewarded the company with a humanizing profile of a sensitive, well-intentioned executive striving to overcome the technical challenges of filtering out misinformation and hate speech from a stream of content that amounted to billions of pieces a day. These challenges are so hard that it makes Schroepfer emotional, wrote the Times: “Sometimes that brings him to tears.”
In the spring of 2020, it was apparently my turn. Ari Entin, Facebook’s AI communications director, asked in an email if I wanted to take a deeper look at the company’s AI work. After talking to several of its AI leaders, I decided to focus on Quiñonero. Entin happily obliged. As not only the leader of the Responsible AI team but also the man who had made Facebook into an AI-driven company, Quiñonero was a solid choice to use as a poster boy.
He seemed a natural choice of subject to me, too. In the years since he’d formed his team following the Cambridge Analytica scandal, concerns about the spread of lies and hate speech on Facebook had only grown. In late 2018 the company admitted that this activity had helped fuel a genocidal anti-Muslim campaign in Myanmar for several years. In 2020 Facebook started belatedly taking action against Holocaust deniers, anti-vaxxers, and the conspiracy movement QAnon. All these dangerous falsehoods were metastasizing thanks to the AI capabilities Quiñonero had helped build. The algorithms that underpin Facebook’s business weren’t created to filter out what was false or inflammatory; they were designed to make people share and engage with as much content as possible by showing them things they were most likely to be outraged or titillated by. Fixing this problem, to me, seemed like core Responsible AI territory.
I began video-calling Quiñonero regularly. I also spoke to Facebook executives, current and former employees, industry peers, and external experts. Many spoke on condition of anonymity because they’d signed nondisclosure agreements or feared retaliation. I wanted to know: What was Quiñonero’s team doing to rein in the hate and lies on its platform?
Joaquin Quiñonero Candela outside his home in the Bay Area, where he lives with his wife and three kids.
But Entin and Quiñonero had a different agenda. Each time I tried to bring up these topics, my requests to speak about them were dropped or redirected. They only wanted to discuss the Responsible AI team’s plan to tackle one specific kind of problem: AI bias, in which algorithms discriminate against particular user groups. An example would be an ad-targeting algorithm that shows certain job or housing opportunities to white people but not to minorities.
By the time thousands of rioters stormed the US Capitol in January, organized in part on Facebook and fueled by the lies about a stolen election that had fanned out across the platform, it was clear from my conversations that the Responsible AI team had failed to make headway against misinformation and hate speech because it had never made those problems its main focus. More important, I realized, if it tried to, it would be set up for failure.
The reason is simple. Everything the company does and chooses not to do flows from a single motivation: Zuckerberg’s relentless desire for growth. Quiñonero’s AI expertise supercharged that growth. His team got pigeonholed into targeting AI bias, as I learned in my reporting, because preventing such bias helps the company avoid proposed regulation that might, if passed, hamper that growth. Facebook leadership has also repeatedly weakened or halted many initiatives meant to clean up misinformation on the platform because doing so would undermine that growth.
In other words, the Responsible AI team’s work—whatever its merits on the specific problem of tackling AI bias—is essentially irrelevant to fixing the bigger problems of misinformation, extremism, and political polarization. And it’s all of us who pay the price.
“When you’re in the business of maximizing engagement, you’re not interested in truth. You’re not interested in harm, divisiveness, conspiracy. In fact, those are your friends,” says Hany Farid, a professor at the University of California, Berkeley who collaborates with Facebook to understand image- and video-based misinformation on the platform.
“They always do just enough to be able to put the press release out. But with a few exceptions, I don’t think it’s actually translated into better policies. They’re never really dealing with the fundamental problems.”
In March of 2012, Quiñonero visited a friend in the Bay Area. At the time, he was a manager in Microsoft Research’s UK office, leading a team using machine learning to get more visitors to click on ads displayed by the company’s search engine, Bing. His expertise was rare, and the team was less than a year old. Machine learning, a subset of AI, had yet to prove itself as a solution to large-scale industry problems. Few tech giants had invested in the technology.
Quiñonero’s friend wanted to show off his new employer, one of the hottest startups in Silicon Valley: Facebook, then eight years old and already with close to a billion monthly active users (i.e., those who have logged in at least once in the past 30 days). As Quiñonero walked around its Menlo Park headquarters, he watched a lone engineer make a major update to the website, something that would have involved significant red tape at Microsoft. It was a memorable introduction to Zuckerberg’s “Move fast and break things” ethos. Quiñonero was awestruck by the possibilities. Within a week, he had been through interviews and signed an offer to join the company.
His arrival couldn’t have been better timed. Facebook’s ads service was in the middle of a rapid expansion as the company was preparing for its May IPO. The goal was to increase revenue and take on Google, which had the lion’s share of the online advertising market. Machine learning, which could predict which ads would resonate best with which users and thus make them more effective, could be the perfect tool. Shortly after starting, Quiñonero was promoted to managing a team similar to the one he’d led at Microsoft.
Quiñonero started raising chickens in late 2019 as a way to unwind from the intensity of his job.
Unlike traditional algorithms, which are hard-coded by engineers, machine-learning algorithms “train” on input data to learn the correlations within it. The trained algorithm, known as a machine-learning model, can then automate future decisions. An algorithm trained on ad click data, for example, might learn that women click on ads for yoga leggings more often than men. The resultant model will then serve more of those ads to women. Today at an AI-based company like Facebook, engineers generate countless models with slight variations to see which one performs best on a given problem.
Facebook’s massive amounts of user data gave Quiñonero a big advantage. His team could develop models that learned to infer the existence not only of broad categories like “women” and “men,” but of very fine-grained categories like “women between 25 and 34 who liked Facebook pages related to yoga,” and targeted ads to them. The finer-grained the targeting, the better the chance of a click, which would give advertisers more bang for their buck.
Within a year his team had developed these models, as well as the tools for designing and deploying new ones faster. Before, it had taken Quiñonero’s engineers six to eight weeks to build, train, and test a new model. Now it took only one.
News of the success spread quickly. The team that worked on determining which posts individual Facebook users would see on their personal news feeds wanted to apply the same techniques. Just as algorithms could be trained to predict who would click what ad, they could also be trained to predict who would like or share what post, and then give those posts more prominence. If the model determined that a person really liked dogs, for instance, friends’ posts about dogs would appear higher up on that user’s news feed.
Quiñonero’s success with the news feed—coupled with impressive new AI research being conducted outside the company—caught the attention of Zuckerberg and Schroepfer. Facebook now had just over 1 billion users, making it more than eight times larger than any other social network, but they wanted to know how to continue that growth. The executives decided to invest heavily in AI, internet connectivity, and virtual reality.
They created two AI teams. One was FAIR, a fundamental research lab that would advance the technology’s state-of-the-art capabilities. The other, Applied Machine Learning (AML), would integrate those capabilities into Facebook’s products and services. In December 2013, after months of courting and persuasion, the executives recruited Yann LeCun, one of the biggest names in the field, to lead FAIR. Three months later, Quiñonero was promoted again, this time to lead AML. (It was later renamed FAIAR, pronounced “fire.”)
“That’s how you know what’s on his mind. I was always, for a couple of years, a few steps from Mark’s desk.”
Joaquin Quiñonero Candela
In his new role, Quiñonero built a new model-development platform for anyone at Facebook to access. Called FBLearner Flow, it allowed engineers with little AI experience to train and deploy machine-learning models within days. By mid-2016, it was in use by more than a quarter of Facebook’s engineering team and had already been used to train over a million models, including models for image recognition, ad targeting, and content moderation.
Zuckerberg’s obsession with getting the whole world to use Facebook had found a powerful new weapon. Teams had previously used design tactics, like experimenting with the content and frequency of notifications, to try to hook users more effectively. Their goal, among other things, was to increase a metric called L6/7, the fraction of people who logged in to Facebook six of the previous seven days. L6/7 is just one of myriad ways in which Facebook has measured “engagement”—the propensity of people to use its platform in any way, whether it’s by posting things, commenting on them, liking or sharing them, or just looking at them. Now every user interaction once analyzed by engineers was being analyzed by algorithms. Those algorithms were creating much faster, more personalized feedback loops for tweaking and tailoring each user’s news feed to keep nudging up engagement numbers.
Zuckerberg, who sat in the center of Building 20, the main office at the Menlo Park headquarters, placed the new FAIR and AML teams beside him. Many of the original AI hires were so close that his desk and theirs were practically touching. It was “the inner sanctum,” says a former leader in the AI org (the branch of Facebook that contains all its AI teams), who recalls the CEO shuffling people in and out of his vicinity as they gained or lost his favor. “That’s how you know what’s on his mind,” says Quiñonero. “I was always, for a couple of years, a few steps from Mark’s desk.”
With new machine-learning models coming online daily, the company created a new system to track their impact and maximize user engagement. The process is still the same today. Teams train up a new machine-learning model on FBLearner, whether to change the ranking order of posts or to better catch content that violates Facebook’s community standards (its rules on what is and isn’t allowed on the platform). Then they test the new model on a small subset of Facebook’s users to measure how it changes engagement metrics, such as the number of likes, comments, and shares, says Krishna Gade, who served as the engineering manager for news feed from 2016 to 2018.
If a model reduces engagement too much, it’s discarded. Otherwise, it’s deployed and continually monitored. On Twitter, Gade explained that his engineers would get notifications every few days when metrics such as likes or comments were down. Then they’d decipher what had caused the problem and whether any models needed retraining.
But this approach soon caused issues. The models that maximize engagement also favor controversy, misinformation, and extremism: put simply, people just like outrageous stuff. Sometimes this inflames existing political tensions. The most devastating example to date is the case of Myanmar, where viral fake news and hate speech about the Rohingya Muslim minority escalated the country’s religious conflict into a full-blown genocide. Facebook admitted in 2018, after years of downplaying its role, that it had not done enough “to help prevent our platform from being used to foment division and incite offline violence.”
While Facebook may have been oblivious to these consequences in the beginning, it was studying them by 2016. In an internal presentation from that year, reviewed by the Wall Street Journal, a company researcher, Monica Lee, found that Facebook was not only hosting a large number of extremist groups but also promoting them to its users: “64% of all extremist group joins are due to our recommendation tools,” the presentation said, predominantly thanks to the models behind the “Groups You Should Join” and “Discover” features.
“The question for leadership was: Should we be optimizing for engagement if you find that somebody is in a vulnerable state of mind?”
A former AI researcher who joined in 2018
In 2017, Chris Cox, Facebook’s longtime chief product officer, formed a new task force to understand whether maximizing user engagement on Facebook was contributing to political polarization. It found that there was indeed a correlation, and that reducing polarization would mean taking a hit on engagement. In a mid-2018 document reviewed by the Journal, the task force proposed several potential fixes, such as tweaking the recommendation algorithms to suggest a more diverse range of groups for people to join. But it acknowledged that some of the ideas were “antigrowth.” Most of the proposals didn’t move forward, and the task force disbanded.
Since then, other employees have corroborated these findings. A former Facebook AI researcher who joined in 2018 says he and his team conducted “study after study” confirming the same basic idea: models that maximize engagement increase polarization. They could easily track how strongly users agreed or disagreed on different issues, what content they liked to engage with, and how their stances changed as a result. Regardless of the issue, the models learned to feed users increasingly extreme viewpoints. “Over time they measurably become more polarized,” he says.
The researcher’s team also found that users with a tendency to post or engage with melancholy content—a possible sign of depression—could easily spiral into consuming increasingly negative material that risked further worsening their mental health. The team proposed tweaking the content-ranking models for these users to stop maximizing engagement alone, so they would be shown less of the depressing stuff. “The question for leadership was: Should we be optimizing for engagement if you find that somebody is in a vulnerable state of mind?” he remembers. (A Facebook spokesperson said she could not find documentation for this proposal.)
But anything that reduced engagement, even for reasons such as not exacerbating someone’s depression, led to a lot of hemming and hawing among leadership. With their performance reviews and salaries tied to the successful completion of projects, employees quickly learned to drop those that received pushback and continue working on those dictated from the top down.
One such project heavily pushed by company leaders involved predicting whether a user might be at risk for something several people had already done: livestreaming their own suicide on Facebook Live. The task involved building a model to analyze the comments that other users were posting on a video after it had gone live, and bringing at-risk users to the attention of trained Facebook community reviewers who could call local emergency responders to perform a wellness check. It didn’t require any changes to content-ranking models, had negligible impact on engagement, and effectively fended off negative press. It was also nearly impossible, says the researcher: “It’s more of a PR stunt. The efficacy of trying to determine if somebody is going to kill themselves in the next 30 seconds, based on the first 10 seconds of video analysis—you’re not going to be very effective.”
Facebook disputes this characterization, saying the team that worked on this effort has since successfully predicted which users were at risk and increased the number of wellness checks performed. But the company does not release data on the accuracy of its predictions or how many wellness checks turned out to be real emergencies.
That former employee, meanwhile, no longer lets his daughter use Facebook.
Quiñonero should have been perfectly placed to tackle these problems when he created the SAIL (later Responsible AI) team in April 2018. His time as the director of Applied Machine Learning had made him intimately familiar with the company’s algorithms, especially the ones used for recommending posts, ads, and other content to users.
It also seemed that Facebook was ready to take these problems seriously. Whereas previous efforts to work on them had been scattered across the company, Quiñonero was now being granted a centralized team with leeway in his mandate to work on whatever he saw fit at the intersection of AI and society.
At the time, Quiñonero was engaging in his own reeducation about how to be a responsible technologist. The field of AI research was paying growing attention to problems of AI bias and accountability in the wake of high-profile studies showing that, for example, an algorithm was scoring Black defendants as more likely to be rearrested than white defendants who’d been arrested for the same or a more serious offense. Quiñonero began studying the scientific literature on algorithmic fairness, reading books on ethical engineering and the history of technology, and speaking with civil rights experts and moral philosophers.
Over the many hours I spent with him, I could tell he took this seriously. He had joined Facebook amid the Arab Spring, a series of revolutions against oppressive Middle Eastern regimes. Experts had lauded social media for spreading the information that fueled the uprisings and giving people tools to organize. Born in Spain but raised in Morocco, where he’d seen the suppression of free speech firsthand, Quiñonero felt an intense connection to Facebook’s potential as a force for good.
Six years later, Cambridge Analytica had threatened to overturn this promise. The controversy forced him to confront his faith in the company and examine what staying would mean for his integrity. “I think what happens to most people who work at Facebook—and definitely has been my story—is that there’s no boundary between Facebook and me,” he says. “It’s extremely personal.” But he chose to stay, and to head SAIL, because he believed he could do more for the world by helping turn the company around than by leaving it behind.
“I think if you’re at a company like Facebook, especially over the last few years, you really realize the impact that your products have on people’s lives—on what they think, how they communicate, how they interact with each other,” says Quiñonero’s longtime friend Zoubin Ghahramani, who helps lead the Google Brain team. “I know Joaquin cares deeply about all aspects of this. As somebody who strives to achieve better and improve things, he sees the important role that he can have in shaping both the thinking and the policies around responsible AI.”
At first, SAIL had only five people, who came from different parts of the company but were all interested in the societal impact of algorithms. One founding member, Isabel Kloumann, a research scientist who’d come from the company’s core data science team, brought with her an initial version of a tool to measure the bias in AI models.
The team also brainstormed many other ideas for projects. The former leader in the AI org, who was present for some of the early meetings of SAIL, recalls one proposal for combating polarization. It involved using sentiment analysis, a form of machine learning that interprets opinion in bits of text, to better identify comments that expressed extreme points of view. These comments wouldn’t be deleted, but they would be hidden by default with an option to reveal them, thus limiting the number of people who saw them.
And there were discussions about what role SAIL could play within Facebook and how it should evolve over time. The sentiment was that the team would first produce responsible-AI guidelines to tell the product teams what they should or should not do. But the hope was that it would ultimately serve as the company’s central hub for evaluating AI projects and stopping those that didn’t follow the guidelines.
Former employees described, however, how hard it could be to get buy-in or financial support when the work didn’t directly improve Facebook’s growth. By its nature, the team was not thinking about growth, and in some cases it was proposing ideas antithetical to growth. As a result, it received few resources and languished. Many of its ideas stayed largely academic.
On August 29, 2018, that suddenly changed. In the ramp-up to the US midterm elections, President Donald Trump and other Republican leaders ratcheted up accusations that Facebook, Twitter, and Google had anti-conservative bias. They claimed that Facebook’s moderators in particular, in applying the community standards, were suppressing conservative voices more than liberal ones. This charge would later be debunked, but the hashtag #StopTheBias, fueled by a Trump tweet, was rapidly spreading on social media.
For Trump, it was the latest effort to sow distrust in the country’s mainstream information distribution channels. For Zuckerberg, it threatened to alienate Facebook’s conservative US users and make the company more vulnerable to regulation from a Republican-led government. In other words, it threatened the company’s growth.
Facebook did not grant me an interview with Zuckerberg, but previousreporting has shown how he increasingly pandered to Trump and the Republican leadership. After Trump was elected, Joel Kaplan, Facebook’s VP of global public policy and its highest-ranking Republican, advised Zuckerberg to tread carefully in the new political environment.
On September 20, 2018, three weeks after Trump’s #StopTheBias tweet, Zuckerberg held a meeting with Quiñonero for the first time since SAIL’s creation. He wanted to know everything Quiñonero had learned about AI bias and how to quash it in Facebook’s content-moderation models. By the end of the meeting, one thing was clear: AI bias was now Quiñonero’s top priority. “The leadership has been very, very pushy about making sure we scale this aggressively,” says Rachad Alao, the engineering director of Responsible AI who joined in April 2019.
It was a win for everybody in the room. Zuckerberg got a way to ward off charges of anti-conservative bias. And Quiñonero now had more money and a bigger team to make the overall Facebook experience better for users. They could build upon Kloumann’s existing tool in order to measure and correct the alleged anti-conservative bias in content-moderation models, as well as to correct other types of bias in the vast majority of models across the platform.
This could help prevent the platform from unintentionally discriminating against certain users. By then, Facebook already had thousands of models running concurrently, and almost none had been measured for bias. That would get it into legal trouble a few months later with the US Department of Housing and Urban Development (HUD), which alleged that the company’s algorithms were inferring “protected” attributes like race from users’ data and showing them ads for housing based on those attributes—an illegal form of discrimination. (The lawsuit is still pending.) Schroepfer also predicted that Congress would soon pass laws to regulate algorithmic discrimination, so Facebook needed to make headway on these efforts anyway.
(Facebook disputes the idea that it pursued its work on AI bias to protect growth or in anticipation of regulation. “We built the Responsible AI team because it was the right thing to do,” a spokesperson said.)
But narrowing SAIL’s focus to algorithmic fairness would sideline all Facebook’s other long-standing algorithmic problems. Its content-recommendation models would continue pushing posts, news, and groups to users in an effort to maximize engagement, rewarding extremist content and contributing to increasingly fractured political discourse.
Zuckerberg even admitted this. Two months after the meeting with Quiñonero, in a public note outlining Facebook’s plans for content moderation, he illustrated the harmful effects of the company’s engagement strategy with a simplified chart. It showed that the more likely a post is to violate Facebook’s community standards, the more user engagement it receives, because the algorithms that maximize engagement reward inflammatory content.
But then he showed another chart with the inverse relationship. Rather than rewarding content that came close to violating the community standards, Zuckerberg wrote, Facebook could choose to start “penalizing” it, giving it “less distribution and engagement” rather than more. How would this be done? With more AI. Facebook would develop better content-moderation models to detect this “borderline content” so it could be retroactively pushed lower in the news feed to snuff out its virality, he said.
The problem is that for all Zuckerberg’s promises, this strategy is tenuous at best.
Misinformation and hate speech constantly evolve. New falsehoods spring up; new people and groups become targets. To catch things before they go viral, content-moderation models must be able to identify new unwanted content with high accuracy. But machine-learning models do not work that way. An algorithm that has learned to recognize Holocaust denial can’t immediately spot, say, Rohingya genocide denial. It must be trained on thousands, often even millions, of examples of a new type of content before learning to filter it out. Even then, users can quickly learn to outwit the model by doing things like changing the wording of a post or replacing incendiary phrases with euphemisms, making their message illegible to the AI while still obvious to a human. This is why new conspiracy theories can rapidly spiral out of control, and partly why, even after such content is banned, forms of it canpersist on the platform.
In his New York Times profile, Schroepfer named these limitations of the company’s content-moderation strategy. “Every time Mr. Schroepfer and his more than 150 engineering specialists create A.I. solutions that flag and squelch noxious material, new and dubious posts that the A.I. systems have never seen before pop up—and are thus not caught,” wrote the Times. “It’s never going to go to zero,” Schroepfer told the publication.
Meanwhile, the algorithms that recommend this content still work to maximize engagement. This means every toxic post that escapes the content-moderation filters will continue to be pushed higher up the news feed and promoted to reach a larger audience. Indeed, a study from New York University recently found that among partisan publishers’ Facebook pages, those that regularly posted political misinformation received the most engagement in the lead-up to the 2020 US presidential election and the Capitol riots. “That just kind of got me,” says a former employee who worked on integrity issues from 2018 to 2019. “We fully acknowledged [this], and yet we’re still increasing engagement.”
But Quiñonero’s SAIL team wasn’t working on this problem. Because of Kaplan’s and Zuckerberg’s worries about alienating conservatives, the team stayed focused on bias. And even after it merged into the bigger Responsible AI team, it was never mandated to work on content-recommendation systems that might limit the spread of misinformation. Nor has any other team, as I confirmed after Entin and another spokesperson gave me a full list of all Facebook’s other initiatives on integrity issues—the company’s umbrella term for problems including misinformation, hate speech, and polarization.
A Facebook spokesperson said, “The work isn’t done by one specific team because that’s not how the company operates.” It is instead distributed among the teams that have the specific expertise to tackle how content ranking affects misinformation for their part of the platform, she said. But Schroepfer told me precisely the opposite in an earlier interview. I had asked him why he had created a centralized Responsible AI team instead of directing existing teams to make progress on the issue. He said it was “best practice” at the company.
“[If] it’s an important area, we need to move fast on it, it’s not well-defined, [we create] a dedicated team and get the right leadership,” he said. “As an area grows and matures, you’ll see the product teams take on more work, but the central team is still needed because you need to stay up with state-of-the-art work.”
When I described the Responsible AI team’s work to other experts on AI ethics and human rights, they noted the incongruity between the problems it was tackling and those, like misinformation, for which Facebook is most notorious. “This seems to be so oddly removed from Facebook as a product—the things Facebook builds and the questions about impact on the world that Facebook faces,” said Rumman Chowdhury, whose startup, Parity, advises firms on the responsible use of AI, and was acquired by Twitter after our interview. I had shown Chowdhury the Quiñonero team’s documentation detailing its work. “I find it surprising that we’re going to talk about inclusivity, fairness, equity, and not talk about the very real issues happening today,” she said.
“It seems like the ‘responsible AI’ framing is completely subjective to what a company decides it wants to care about. It’s like, ‘We’ll make up the terms and then we’ll follow them,’” says Ellery Roberts Biddle, the editorial director of Ranking Digital Rights, a nonprofit that studies the impact of tech companies on human rights. “I don’t even understand what they mean when they talk about fairness. Do they think it’s fair to recommend that people join extremist groups, like the ones that stormed the Capitol? If everyone gets the recommendation, does that mean it was fair?”
“We’re at a place where there’s one genocide [Myanmar] that the UN has, with a lot of evidence, been able to specifically point to Facebook and to the way that the platform promotes content,” Biddle adds. “How much higher can the stakes get?”
Over the last two years, Quiñonero’s team has built out Kloumann’s original tool, called Fairness Flow. It allows engineers to measure the accuracy of machine-learning models for different user groups. They can compare a face-detection model’s accuracy across different ages, genders, and skin tones, or a speech-recognition algorithm’s accuracy across different languages, dialects, and accents.
Fairness Flow also comes with a set of guidelines to help engineers understand what it means to train a “fair” model. One of the thornier problems with making algorithms fair is that there are different definitions of fairness, which can be mutually incompatible. Fairness Flow lists four definitions that engineers can use according to which suits their purpose best, such as whether a speech-recognition model recognizes all accents with equal accuracy or with a minimum threshold of accuracy.
But testing algorithms for fairness is still largely optional at Facebook. None of the teams that work directly on Facebook’s news feed, ad service, or other products are required to do it. Pay incentives are still tied to engagement and growth metrics. And while there are guidelines about which fairness definition to use in any given situation, they aren’t enforced.
This last problem came to the fore when the company had to deal with allegations of anti-conservative bias.
In 2014, Kaplan was promoted from US policy head to global vice president for policy, and he began playing a more heavy-handed role in content moderation and decisions about how to rank posts in users’ news feeds. After Republicans started voicing claims of anti-conservative bias in 2016, his team began manually reviewing the impact of misinformation-detection models on users to ensure—among other things—that they didn’t disproportionately penalize conservatives.
All Facebook users have some 200 “traits” attached to their profile. These include various dimensions submitted by users or estimated by machine-learning models, such as race, political and religious leanings, socioeconomic class, and level of education. Kaplan’s team began using the traits to assemble custom user segments that reflected largely conservative interests: users who engaged with conservative content, groups, and pages, for example. Then they’d run special analyses to see how content-moderation decisions would affect posts from those segments, according to a former researcher whose work was subject to those reviews.
The Fairness Flow documentation, which the Responsible AI team wrote later, includes a case study on how to use the tool in such a situation. When deciding whether a misinformation model is fair with respect to political ideology, the team wrote, “fairness” does not mean the model should affect conservative and liberal users equally. If conservatives are posting a greater fraction of misinformation, as judged by public consensus, then the model should flag a greater fraction of conservative content. If liberals are posting more misinformation, it should flag their content more often too.
But members of Kaplan’s team followed exactly the opposite approach: they took “fairness” to mean that these models should not affect conservatives more than liberals. When a model did so, they would stop its deployment and demand a change. Once, they blocked a medical-misinformation detector that had noticeably reduced the reach of anti-vaccine campaigns, the former researcher told me. They told the researchers that the model could not be deployed until the team fixed this discrepancy. But that effectively made the model meaningless. “There’s no point, then,” the researcher says. A model modified in that way “would have literally no impact on the actual problem” of misinformation.
“I don’t even understand what they mean when they talk about fairness. Do they think it’s fair to recommend that people join extremist groups, like the ones that stormed the Capitol? If everyone gets the recommendation, does that mean it was fair?”
Ellery Roberts Biddle, editorial director of Ranking Digital Rights
This happened countless other times—and not just for content moderation. In 2020, the Washington Post reported that Kaplan’s team had undermined efforts to mitigate election interference and polarization within Facebook, saying they could contribute to anti-conservative bias. In 2018, it used the same argument to shelve a project to edit Facebook’s recommendation models even though researchers believed it would reduce divisiveness on the platform, according to the Wall Street Journal. His claims about political bias also weakened a proposal to edit the ranking models for the news feed that Facebook’s data scientists believed would strengthen the platform against the manipulation tactics Russia had used during the 2016 US election.
And ahead of the 2020 election, Facebook policy executives used this excuse, according to the New York Times, to veto or weaken several proposals that would have reduced the spread of hateful and damaging content.
Facebook disputed the Wall Street Journal’s reporting in a follow-up blog post, and challenged the New York Times’s characterization in an interview with the publication. A spokesperson for Kaplan’s team also denied to me that this was a pattern of behavior, saying the cases reported by the Post, the Journal, and the Times were “all individual instances that we believe are then mischaracterized.” He declined to comment about the retraining of misinformation models on the record.
Many of these incidents happened before Fairness Flow was adopted. But they show how Facebook’s pursuit of fairness in the service of growth had already come at a steep cost to progress on the platform’s other challenges. And if engineers used the definition of fairness that Kaplan’s team had adopted, Fairness Flow could simply systematize behavior that rewarded misinformation instead of helping to combat it.
Often “the whole fairness thing” came into play only as a convenient way to maintain the status quo, the former researcher says: “It seems to fly in the face of the things that Mark was saying publicly in terms of being fair and equitable.”
The last time I spoke with Quiñonero was a month after the US Capitol riots. I wanted to know how the storming of Congress had affected his thinking and the direction of his work.
In the video call, it was as it always was: Quiñonero dialing in from his home office in one window and Entin, his PR handler, in another. I asked Quiñonero what role he felt Facebook had played in the riots and whether it changed the task he saw for Responsible AI. After a long pause, he sidestepped the question, launching into a description of recent work he’d done to promote greater diversity and inclusion among the AI teams.
I asked him the question again. His Facebook Portal camera, which uses computer-vision algorithms to track the speaker, began to slowly zoom in on his face as he grew still. “I don’t know that I have an easy answer to that question, Karen,” he said. “It’s an extremely difficult question to ask me.”
Entin, who’d been rapidly pacing with a stoic poker face, grabbed a red stress ball.
I asked Quiñonero why his team hadn’t previously looked at ways to edit Facebook’s content-ranking models to tamp down misinformation and extremism. He told me it was the job of other teams (though none, as I confirmed, have been mandated to work on that task). “It’s not feasible for the Responsible AI team to study all those things ourselves,” he said. When I asked whether he would consider having his team tackle those issues in the future, he vaguely admitted, “I would agree with you that that is going to be the scope of these types of conversations.”
Near the end of our hour-long interview, he began to emphasize that AI was often unfairly painted as “the culprit.” Regardless of whether Facebook used AI or not, he said, people would still spew lies and hate speech, and that content would still spread across the platform.
I pressed him one more time. Certainly he couldn’t believe that algorithms had done absolutely nothing to change the nature of these issues, I said.
“I don’t know,” he said with a halting stutter. Then he repeated, with more conviction: “That’s my honest answer. Honest to God. I don’t know.”
Corrections:We amended a line that suggested that Joel Kaplan, Facebook’s vice president of global policy, had used Fairness Flow. He has not. But members of his team have used the notion of fairness to request the retraining of misinformation models in ways that directly contradict Responsible AI’s guidelines. We also clarified when Rachad Alao, the engineering director of Responsible AI, joined the company.
A ideia da inteligência artificial derrubar a humanidade tem sido discutida por muitas décadas, e os cientistas acabaram de dar seu veredicto sobre se seríamos capazes de controlar uma superinteligência de computador de alto nível. A resposta? Quase definitivamente não.
O problema é que controlar uma superinteligência muito além da compreensão humana exigiria uma simulação dessa superinteligência que podemos analisar. Mas se não formos capazes de compreendê-lo, é impossível criar tal simulação.
Regras como ‘não causar danos aos humanos’ não podem ser definidas se não entendermos o tipo de cenário que uma IA irá criar, sugerem os pesquisadores. Uma vez que um sistema de computador está trabalhando em um nível acima do escopo de nossos programadores, não podemos mais estabelecer limites.
“Uma superinteligência apresenta um problema fundamentalmente diferente daqueles normalmente estudados sob a bandeira da ‘ética do robô’”, escrevem os pesquisadores.
“Isso ocorre porque uma superinteligência é multifacetada e, portanto, potencialmente capaz de mobilizar uma diversidade de recursos para atingir objetivos que são potencialmente incompreensíveis para os humanos, quanto mais controláveis.”
Parte do raciocínio da equipe vem do problema da parada apresentado por Alan Turing em 1936. O problema centra-se em saber se um programa de computador chegará ou não a uma conclusão e responderá (para que seja interrompido), ou simplesmente ficar em um loop eterno tentando encontrar uma.
Como Turing provou por meio de uma matemática inteligente, embora possamos saber isso para alguns programas específicos, é logicamente impossível encontrar uma maneira que nos permita saber isso para cada programa potencial que poderia ser escrito. Isso nos leva de volta à IA, que, em um estado superinteligente, poderia armazenar todos os programas de computador possíveis em sua memória de uma vez.
Qualquer programa escrito para impedir que a IA prejudique humanos e destrua o mundo, por exemplo, pode chegar a uma conclusão (e parar) ou não – é matematicamente impossível para nós estarmos absolutamente seguros de qualquer maneira, o que significa que não pode ser contido.
“Na verdade, isso torna o algoritmo de contenção inutilizável”, diz o cientista da computação Iyad Rahwan, do Instituto Max-Planck para o Desenvolvimento Humano, na Alemanha.
A alternativa de ensinar alguma ética à IA e dizer a ela para não destruir o mundo – algo que nenhum algoritmo pode ter certeza absoluta de fazer, dizem os pesquisadores – é limitar as capacidades da superinteligência. Ele pode ser cortado de partes da Internet ou de certas redes, por exemplo.
O novo estudo também rejeita essa ideia, sugerindo que isso limitaria o alcance da inteligência artificial – o argumento é que se não vamos usá-la para resolver problemas além do escopo dos humanos, então por que criá-la?
Se vamos avançar com a inteligência artificial, podemos nem saber quando chega uma superinteligência além do nosso controle, tal é a sua incompreensibilidade. Isso significa que precisamos começar a fazer algumas perguntas sérias sobre as direções que estamos tomando.
“Uma máquina superinteligente que controla o mundo parece ficção científica”, diz o cientista da computação Manuel Cebrian, do Instituto Max-Planck para o Desenvolvimento Humano. “Mas já existem máquinas que executam certas tarefas importantes de forma independente, sem que os programadores entendam totalmente como as aprenderam.”
“Portanto, surge a questão de saber se isso poderia em algum momento se tornar incontrolável e perigoso para a humanidade.”
Brian Nord is an astrophysicist and machine learning researcher. Photo: Mark Lopez/Argonne National Laboratory
Machine learning algorithms serve us the news we read, the ads we see, and in some cases even drive our cars. But there’s an insidious layer to these algorithms: They rely on data collected by and about humans, and they spit our worst biases right back out at us. For example, job candidate screening algorithms may automatically reject names that sound like they belong to nonwhite people, while facial recognition software is often much worse at recognizing women or nonwhite faces than it is at recognizing white male faces. An increasing number of scientists and institutions are waking up to these issues, and speaking out about the potential for AI to cause harm.
Brian Nord is one such researcher weighing his own work against the potential to cause harm with AI algorithms. Nord is a cosmologist at Fermilab and the University of Chicago, where he uses artificial intelligence to study the cosmos, and he’s been researching a concept for a “self-driving telescope” that can write and test hypotheses with the help of a machine learning algorithm. At the same time, he’s struggling with the idea that the algorithms he’s writing may one day be biased against him—and even used against him—and is working to build a coalition of physicists and computer scientists to fight for more oversight in AI algorithm development.
This interview has been edited and condensed for clarity.
Gizmodo: How did you become a physicist interested in AI and its pitfalls?
Brian Nord: My Ph.d is in cosmology, and when I moved to Fermilab in 2012, I moved into the subfield of strong gravitational lensing. [Editor’s note: Gravitational lenses are places in the night sky where light from distant objects has been bent by the gravitational field of heavy objects in the foreground, making the background objects appear warped and larger.] I spent a few years doing strong lensing science in the traditional way, where we would visually search through terabytes of images, through thousands of candidates of these strong gravitational lenses, because they’re so weird, and no one had figured out a more conventional algorithm to identify them. Around 2015, I got kind of sad at the prospect of only finding these things with my eyes, so I started looking around and found deep learning.
Here we are a few years later—myself and a few other people popularized this idea of using deep learning—and now it’s the standard way to find these objects. People are unlikely to go back to using methods that aren’t deep learning to do galaxy recognition. We got to this point where we saw that deep learning is the thing, and really quickly saw the potential impact of it across astronomy and the sciences. It’s hitting every science now. That is a testament to the promise and peril of this technology, with such a relatively simple tool. Once you have the pieces put together right, you can do a lot of different things easily, without necessarily thinking through the implications.
Gizmodo: So what is deep learning? Why is it good and why is it bad?
BN: Traditional mathematical models (like the F=ma of Newton’s laws) are built by humans to describe patterns in data: We use our current understanding of nature, also known as intuition, to choose the pieces, the shape of these models. This means that they are often limited by what we know or can imagine about a dataset. These models are also typically smaller and are less generally applicable for many problems.
On the other hand, artificial intelligence models can be very large, with many, many degrees of freedom, so they can be made very general and able to describe lots of different data sets. Also, very importantly, they are primarily sculpted by the data that they are exposed to—AI models are shaped by the data with which they are trained. Humans decide what goes into the training set, which is then limited again by what we know or can imagine about that data. It’s not a big jump to see that if you don’t have the right training data, you can fall off the cliff really quickly.
The promise and peril are highly related. In the case of AI, the promise is in the ability to describe data that humans don’t yet know how to describe with our ‘intuitive’ models. But, perilously, the data sets used to train them incorporate our own biases. When it comes to AI recognizing galaxies, we’re risking biased measurements of the universe. When it comes to AI recognizing human faces, when our data sets are biased against Black and Brown faces for example, we risk discrimination that prevents people from using services, that intensifies surveillance apparatus, that jeopardizes human freedoms. It’s critical that we weigh and address these consequences before we imperil people’s lives with our research.
Gizmodo: When did the light bulb go off in your head that AI could be harmful?
BN: I gotta say that it was with the Machine Bias article from ProPublica in 2016, where they discuss recidivism and sentencing procedure in courts. At the time of that article, there was a closed-source algorithm used to make recommendations for sentencing, and judges were allowed to use it. There was no public oversight of this algorithm, which ProPublica found was biased against Black people; people could use algorithms like this willy nilly without accountability. I realized that as a Black man, I had spent the last few years getting excited about neural networks, then saw it quite clearly that these applications that could harm me were already out there, already being used, and we’re already starting to become embedded in our social structure through the criminal justice system. Then I started paying attention more and more. I realized countries across the world were using surveillance technology, incorporating machine learning algorithms, for widespread oppressive uses.
Gizmodo: How did you react? What did you do?
BN: I didn’t want to reinvent the wheel; I wanted to build a coalition. I started looking into groups like Fairness, Accountability and Transparency in Machine Learning, plus Black in AI, who is focused on building communities of Black researchers in the AI field, but who also has the unique awareness of the problem because we are the people who are affected. I started paying attention to the news and saw that Meredith Whittaker had started a think tank to combat these things, and Joy Buolamwini had helped found the Algorithmic Justice League. I brushed up on what computer scientists were doing and started to look at what physicists were doing, because that’s my principal community.
It became clear to folks like me and Savannah Thais that physicists needed to realize that they have a stake in this game. We get government funding, and we tend to take a fundamental approach to research. If we bring that approach to AI, then we have the potential to affect the foundations of how these algorithms work and impact a broader set of applications. I asked myself and my colleagues what our responsibility in developing these algorithms was and in having some say in how they’re being used down the line.
Gizmodo: How is it going so far?
BN: Currently, we’re going to write a white paper for SNOWMASS, this high-energy physics event. The SNOWMASS process determines the vision that guides the community for about a decade. I started to identify individuals to work with, fellow physicists, and experts who care about the issues, and develop a set of arguments for why physicists from institutions, individuals, and funding agencies should care deeply about these algorithms they’re building and implementing so quickly. It’s a piece that’s asking people to think about how much they are considering the ethical implications of what they’re doing.
We’ve already held a workshop at the University of Chicago where we’ve begun discussing these issues, and at Fermilab we’ve had some initial discussions. But we don’t yet have the critical mass across the field to develop policy. We can’t do it ourselves as physicists; we don’t have backgrounds in social science or technology studies. The right way to do this is to bring physicists together from Fermilab and other institutions with social scientists and ethicists and science and technology studies folks and professionals, and build something from there. The key is going to be through partnership with these other disciplines.
Gizmodo: Why haven’t we reached that critical mass yet?
BN: I think we need to show people, as Angela Davis has said, that our struggle is also their struggle. That’s why I’m talking about coalition building. The thing that affects us also affects them. One way to do this is to clearly lay out the potential harm beyond just race and ethnicity. Recently, there was this discussion of a paper that used neural networks to try and speed up the selection of candidates for Ph.D programs. They trained the algorithm on historical data. So let me be clear, they said here’s a neural network, here’s data on applicants who were denied and accepted to universities. Those applicants were chosen by faculty and people with biases. It should be obvious to anyone developing that algorithm that you’re going to bake in the biases in that context. I hope people will see these things as problems and help build our coalition.
Gizmodo: What is your vision for a future of ethical AI?
BN: What if there were an agency or agencies for algorithmic accountability? I could see these existing at the local level, the national level, and the institutional level. We can’t predict all of the future uses of technology, but we need to be asking questions at the beginning of the processes, not as an afterthought. An agency would help ask these questions and still allow the science to get done, but without endangering people’s lives. Alongside agencies, we need policies at various levels that make a clear decision about how safe the algorithms have to be before they are used on humans or other living things. If I had my druthers, these agencies and policies would be built by an incredibly diverse group of people. We’ve seen instances where a homogeneous group develops an app or technology and didn’t see the things that another group who’s not there would have seen. We need people across the spectrum of experience to participate in designing policies for ethical AI.
Gizmodo: What are your biggest fears about all of this?
BN: My biggest fear is that people who already have access to technology resources will continue to use them to subjugate people who are already oppressed; Pratyusha Kalluri has also advanced this idea of power dynamics. That’s what we’re seeing across the globe. Sure, there are cities that are trying to ban facial recognition, but unless we have a broader coalition, unless we have more cities and institutions willing to take on this thing directly, we’re not going to be able to keep this tool from exacerbating white supremacy, racism, and misogyny that that already exists inside structures today. If we don’t push policy that puts the lives of marginalized people first, then they’re going to continue being oppressed, and it’s going to accelerate.
Gizmodo: How has thinking about AI ethics affected your own research?
BN: I have to question whether I want to do AI work and how I’m going to do it; whether or not it’s the right thing to do to build a certain algorithm. That’s something I have to keep asking myself… Before, it was like, how fast can I discover new things and build technology that can help the world learn something? Now there’s a significant piece of nuance to that. Even the best things for humanity could be used in some of the worst ways. It’s a fundamental rethinking of the order of operations when it comes to my research.
I don’t think it’s weird to think about safety first. We have OSHA and safety groups at institutions who write down lists of things you have to check off before you’re allowed to take out a ladder, for example. Why are we not doing the same thing in AI? A part of the answer is obvious: Not all of us are people who experience the negative effects of these algorithms. But as one of the few Black people at the institutions I work in, I’m aware of it, I’m worried about it, and the scientific community needs to appreciate that my safety matters too, and that my safety concerns don’t end when I walk out of work.
Gizmodo: Anything else?
BN: I’d like to re-emphasize that when you look at some of the research that has come out, like vetting candidates for graduate school, or when you look at the biases of the algorithms used in criminal justice, these are problems being repeated over and over again, with the same biases. It doesn’t take a lot of investigation to see that bias enters these algorithms very quickly. The people developing them should really know better. Maybe there needs to be more educational requirements for algorithm developers to think about these issues before they have the opportunity to unleash them on the world.
This conversation needs to be raised to the level where individuals and institutions consider these issues a priority. Once you’re there, you need people to see that this is an opportunity for leadership. If we can get a grassroots community to help an institution to take the lead on this, it incentivizes a lot of people to start to take action.
And finally, people who have expertise in these areas need to be allowed to speak their minds. We can’t allow our institutions to quiet us so we can’t talk about the issues we’re bringing up. The fact that I have experience as a Black man doing science in America, and the fact that I do AI—that should be appreciated by institutions. It gives them an opportunity to have a unique perspective and take a unique leadership position. I would be worried if individuals felt like they couldn’t speak their mind. If we can’t get these issues out into the sunlight, how will we be able to build out of the darkness?
Ryan F. Mandelbaum – Former Gizmodo physics writer and founder of Birdmodo, now a science communicator specializing in quantum computing and birds
Until recently, the field of plant breeding looked a lot like it did in centuries past. A breeder might examine, for example, which tomato plants were most resistant to drought and then cross the most promising plants to produce the most drought-resistant offspring. This process would be repeated, plant generation after generation, until, over the course of roughly seven years, the breeder arrived at what seemed the optimal variety.
Researchers at ETH Zürich use standard color images and thermal images collected by drone to determine how plots of wheat with different genotypes vary in grain ripeness. Image credit: Norbert Kirchgessner (ETH Zürich, Zürich, Switzerland).
Now, with the global population expected to swell to nearly 10 billion by 2050 (1) and climate change shifting growing conditions (2), crop breeder and geneticist Steven Tanksley doesn’t think plant breeders have that kind of time. “We have to double the productivity per acre of our major crops if we’re going to stay on par with the world’s needs,” says Tanksley, a professor emeritus at Cornell University in Ithaca, NY.
To speed up the process, Tanksley and others are turning to artificial intelligence (AI). Using computer science techniques, breeders can rapidly assess which plants grow the fastest in a particular climate, which genes help plants thrive there, and which plants, when crossed, produce an optimum combination of genes for a given location, opting for traits that boost yield and stave off the effects of a changing climate. Large seed companies in particular have been using components of AI for more than a decade. With computing power rapidly advancing, the techniques are now poised to accelerate breeding on a broader scale.
AI is not, however, a panacea. Crop breeders still grapple with tradeoffs such as higher yield versus marketable appearance. And even the most sophisticated AI cannot guarantee the success of a new variety. But as AI becomes integrated into agriculture, some crop researchers envisage an agricultural revolution with computer science at the helm.
An Art and a Science
During the “green revolution” of the 1960s, researchers developed new chemical pesticides and fertilizers along with high-yielding crop varieties that dramatically increased agricultural output (3). But the reliance on chemicals came with the heavy cost of environmental degradation (4). “If we’re going to do this sustainably,” says Tanksley, “genetics is going to carry the bulk of the load.”
Plant breeders lean not only on genetics but also on mathematics. As the genomics revolution unfolded in the early 2000s, plant breeders found themselves inundated with genomic data that traditional statistical techniques couldn’t wrangle (5). Plant breeding “wasn’t geared toward dealing with large amounts of data and making precise decisions,” says Tanksley.
In 1997, Tanksley began chairing a committee at Cornell that aimed to incorporate data-driven research into the life sciences. There, he encountered an engineering approach called operations research that translates data into decisions. In 2006, Tanksley cofounded the Ithaca, NY-based company Nature Source Improved Plants on the principle that this engineering tool could make breeding decisions more efficient. “What we’ve been doing almost 15 years now,” says Tanksley, “is redoing how breeding is approached.”
A Manufacturing Process
Such approaches try to tackle complex scenarios. Suppose, for example, a wheat breeder has 200 genetically distinct lines. The breeder must decide which lines to breed together to optimize yield, disease resistance, protein content, and other traits. The breeder may know which genes confer which traits, but it’s difficult to decipher which lines to cross in what order to achieve the optimum gene combination. The number of possible combinations, says Tanksley, “is more than the stars in the universe.”
An operations research approach enables a researcher to solve this puzzle by defining the primary objective and then using optimization algorithms to predict the quickest path to that objective given the relevant constraints. Auto manufacturers, for example, optimize production given the expense of employees, the cost of auto parts, and fluctuating global currencies. Tanksley’s team optimizes yield while selecting for traits such as resistance to a changing climate. “We’ve seen more erratic climate from year to year, which means you have to have crops that are more robust to different kinds of changes,” he says.
For each plant line included in a pool of possible crosses, Tanksley inputs DNA sequence data, phenotypic data on traits like drought tolerance, disease resistance, and yield, as well as environmental data for the region where the plant line was originally developed. The algorithm projects which genes are associated with which traits under which environmental conditions and then determines the optimal combination of genes for a specific breeding goal, such as drought tolerance in a particular growing region, while accounting for genes that help boost yield. The algorithm also determines which plant lines to cross together in which order to achieve the optimal combination of genes in the fewest generations.
Nature Source Improved Plants conducts, for example, a papaya program in southeastern Mexico where the once predictable monsoon season has become erratic. “We are selecting for varieties that can produce under those unknown circumstances,” says Tanksley. But the new papaya must also stand up to ringspot, a virus that nearly wiped papaya from Hawaii altogether before another Cornell breeder developed a resistant transgenic variety (6). Tanksley’s papaya isn’t as disease resistant. But by plugging “rapid growth rate” into their operations research approach, the team bred papaya trees that produce copious fruit within a year, before the virus accumulates in the plant.
“Plant breeders need operations research to help them make better decisions,” says William Beavis, a plant geneticist and computational biologist at Iowa State in Ames, who also develops operations research strategies for plant breeding. To feed the world in rapidly changing environments, researchers need to shorten the process of developing a new cultivar to three years, Beavis adds.
The big seed companies have investigated use of operations research since around 2010, with Syngenta, headquartered in Basel, Switzerland, leading the pack, says Beavis, who spent over a decade as a statistical geneticist at Pioneer Hi-Bred in Johnston, IA, a large seed company now owned by Corteva, which is headquartered in Wilmington, DE. “All of the soybean varieties that have come on the market within the last couple of years from Syngenta came out of a system that had been redesigned using operations research approaches,” he says. But large seed companies primarily focus on grains key to animal feed such as corn, wheat, and soy. To meet growing food demands, Beavis believes that the smaller seed companies that develop vegetable crops that people actually eat must also embrace operations research. “That’s where operations research is going to have the biggest impact,” he says, “local breeding companies that are producing for regional environments, not for broad adaptation.”
In collaboration with Iowa State colleague and engineer Lizhi Wang and others, Beavis is developing operations research-based algorithms to, for example, help seed companies choose whether to breed one variety that can survive in a range of different future growing conditions or a number of varieties, each tailored to specific environments. Two large seed companies, Corteva and Syngenta, and Kromite, a Lambertville, NJ-based consulting company, are partners on the project. The results will be made publicly available so that all seed companies can learn from their approach.
Nature Source Improved Plants (NSIP) speeds up its papaya breeding program in southeastern Mexico by using decision-making approaches more common in engineering. Image credit: Nature Source Improved Plants/Jesús Morales.
Drones and Adaptations
Useful farming AI requires good data, and plenty of it. To collect sufficient inputs, some researchers take to the skies. Crop researcher Achim Walter of the Institute of Agricultural Sciences at ETH Zürich in Switzerland and his team are developing techniques to capture aerial crop images. Every other day for several years, they have deployed image-capturing sensors over a wheat field containing hundreds of genetic lines. They fly their sensors on drones or on cables suspended above the crops or incorporate them into handheld devices that a researcher can use from an elevated platform (7).
Meanwhile, they’re developing imaging software that quantifies growth rate captured by these images (8). Using these data, they build models that predict how quickly different genetic lines grow under different weather conditions. If they find, for example, that a subset of wheat lines grew well despite a dry spell, then they can zero in on the genes those lines have in common and incorporate them into new drought-resistant varieties.
Research geneticist Edward Buckler at the US Department of Agriculture and his team are using machine learning to identify climate adaptations in 1,000 species in a large grouping of grasses spread across the globe. The grasses include food and bioenergy crops such as maize, sorghum, and sugar cane. Buckler says that when people rank what are the most photosynthetically efficient and water-efficient species, this is the group that comes out at the top. Still, he and collaborators, including plant scientist Elizabeth Kellogg of the Donald Danforth Plant Science Center in St. Louis, MO, and computational biologist Adam Siepel of Cold Spring Harbor Laboratory in NY, want to uncover genes that could make crops in this group even more efficient for food production in current and future environments. The team is first studying a select number of model species to determine which genes are expressed under a range of different environmental conditions. They’re still probing just how far this predictive power can go.
Such approaches could be scaled up—massively. To probe the genetic underpinnings of climate adaptation for crop species worldwide, Daniel Jacobson, the chief researcher for computational systems biology at Oak Ridge National Laboratory in TN, has amassed “climatype” data for every square kilometer of land on Earth. Using the Summit supercomputer, they then compared each square kilometer to every other square kilometer to identify similar environments (9). The result can be viewed as a network of GPS points connected by lines that show the degree of environmental similarity between points.
“For me, breeding is much more like art. I need to see the variation and I don’t prejudge it. I know what I’m after, but nature throws me curveballs all the time, and I probably can’t count the varieties that came from curveballs.”
—Molly Jahn
In collaboration with the US Department of Energy’s Center for Bioenergy Innovation, the team combines this climatype data with GPS coordinates associated with individual crop genotypes to project which genes and genetic interactions are associated with specific climate conditions. Right now, they’re focused on bioenergy and feedstocks, but they’re poised to explore a wide range of food crops as well. The results will be published so that other researchers can conduct similar analyses.
The Next Agricultural Revolution
Despite these advances, the transition to AI can be unnerving. Operations research can project an ideal combination of genes, but those genes may interact in unpredictable ways. Tanksley’s company hedges its bets by engineering 10 varieties for a given project in hopes that at least one will succeed.
On the other hand, such a directed approach could miss happy accidents, says Molly Jahn, a geneticist and plant breeder at the University of Wisconsin–Madison. “For me, breeding is much more like art. I need to see the variation and I don’t prejudge it,” she says. “I know what I’m after, but nature throws me curveballs all the time, and I probably can’t count the varieties that came from curveballs.”
There are also inherent tradeoffs that no algorithm can overcome. Consumers may prefer tomatoes with a leafy crown that stays green longer. But the price a breeder pays for that green calyx is one percent of the yield, says Tanksley.
Image recognition technology comes with its own host of challenges, says Walter. “To optimize algorithms to an extent that makes it possible to detect a certain trait, you have to train the algorithm thousands of times.” In practice, that means snapping thousands of crop images in a range of light conditions. Then there’s the ground-truthing. To know whether the models work, Walter and others must measure the trait they’re after by hand. Keen to know whether the model accurately captures the number of kernels on an ear of corn? You’d have to count the kernels yourself.
Despite these hurdles, Walter believes that computer science has brought us to the brink of a new agricultural revolution. In a 2017 PNAS Opinion piece, Walter and colleagues described emerging “smart farming” technologies—from autonomous weeding vehicles to moisture sensors in the soil (10). The authors worried, though, that only big industrial farms can afford these solutions. To make agriculture more sustainable, smaller farms in developing countries must have access as well.
Fortunately, “smart breeding” advances may have wider reach. Once image recognition technology becomes more developed for crops, which Walter expects will happen within the next 10 years, deploying it may be relatively inexpensive. Breeders could operate their own drones and obtain more precise ratings of traits like time to flowering or number of fruits in shorter time, says Walter. “The computing power that you need once you have established the algorithms is not very high.”
The genomic data so vital to AI-led breeding programs is also becoming more accessible. “We’re really at this point where genomics is cheap enough that you can apply these technologies to hundreds of species, maybe thousands,” says Buckler.
Plant breeding has “entered the engineered phase,” adds Tanksley. And with little time to spare. “The environment is changing,” he says. “You have to have a faster breeding process to respond to that.”
1. United Nations, Department of Economic and Social Affairs, Population Division, World Population Prospects 2019: Highlights, (United Nations, New York, 2019).
3. P. L. Pingali, Green revolution: Impacts, limits, and the path ahead. Proc. Natl. Acad. Sci. U.S.A. 109, 12302–12308 (2012).
4. D. Tilman, The greening of the green revolution. Nature 396, 211–212 (1998).
5. G. P. Ramstein, S. E. Jensen, E. S. Buckler, Breaking the curse of dimensionality to identify causal variants in Breeding 4. Theor. Appl. Genet. 132, 559–567 (2019).
6. D. Gonsalves, Control of papaya ringspot virus in papaya: A case study. Annu. Rev. Phytopathol. 36, 415–437 (1998).
7. N. Kirchgessner et al., The ETH field phenotyping platform FIP: A cable-suspended multi-sensor system. Funct. Plant Biol. 44, 154–168 (2016).
8. K. Yu, N. Kirchgessner, C. Grieder, A. Walter, A. Hund, An image analysis pipeline for automated classification of imaging light conditions and for quantification of wheat canopy cover time series in field phenotyping. Plant Methods 13, 15 (2017).
9. J. Streich et al., Can exascale computing and explainable artificial intelligence applied to plant biology deliver on the United Nations sustainable development goals? Curr. Opin. Biotechnol. 61, 217–225 (2020).
10. A. Walter, R. Finger, R. Huber, N. Buchmann, Opinion: Smart farming is key to developing sustainable agriculture. Proc. Natl. Acad. Sci. U.S.A. 114, 6148–6150 (2017).
Terça-feira (28) participei de uma teleconversa curiosa, sobre inteligência artificial (IA) e humanização da medicina. Parecia contradição nos termos, em especial nesta pandemia de Covid-19, ou debate sobre sexo dos anjos, quando estamos fracassando já na antessala da alta tecnologia –realizar testes diagnósticos, contar mortes corretamente e produzir dados estatísticos confiáveis.
O encontro virtual, que vai ao ar amanhã, faz parte de uma série (youtube.com/rio2c) que vem substituir a conferência sobre economia criativa Rio2C, cuja realização neste mês foi cancelada. Coube-me moderar o diálogo entre Sonoo Thadaney, do Presence –centro da Universidade Stanford dedicado à humanização do atendimento de saúde–, e Jorge Moll Neto, do Instituto D’Or de Pesquisa e Ensino (Idor), conhecido como Gito.
O coronavírus CoV-2 já legou cerca de 3,5 milhões de infectados e 250 mil mortos (números subestimados). A pandemia é agravada por líderes de nações populosas que chegaram ao poder e nele se mantêm espalhando desinformação com ajuda de algoritmos de redes sociais que privilegiam a estridência e os vieses de confirmação de seus seguidores.
Você entendeu: Donald Trump (EUA, 1/3 dos casos no mundo) e Jair Bolsonaro (Brasil, um distante 0,2% do total, mas marchando para números dantescos). Trump corrigiu alguns graus no curso na nau de desvairados em que se tornou a Casa Branca; o Messias que não faz milagres ainda não deu sinais de imitá-lo, porque neste caso seria fazer a coisa certa.
Na teleconversa da Rio2C, Sonoo e Gito fizeram as perorações de praxe contra a substituição da ciência por ideologia na condução da pandemia. O diretor do Idor deu a entender que nunca viu tanta besteira saindo da boca de leigos e autointitulados especialistas.
A diretora do centro de Stanford, originária da Índia, disse que, se precisar preparar um frango tandoori, vai ligar e perguntar para quem sabe fazer. E não para qualquer médico que se aventura nos mares da epidemiologia dizendo que a Terra é plana, deduzo eu, para encompridar a metáfora, na esperança de que leitores brasileiros entendam de que deputado se trata.
Há razão para ver o vídeo da conversa (com legendas em português) e sair um pouco otimista. Gito afirmou que se dá mais importância e visibilidade para consequências não pretendidas negativas da tecnologia.
No caso, a IA e seus algoritmos dinâmicos, que tomam resultados em conta para indicar soluções, como apresentar em cada linha do tempo na rede social as notas com maior probabilidade de atraírem novos seguidores e de serem reproduzidas, curtidas ou comentadas (o chamado engajamento, que muitos confundem com sucesso).
Um bom nome para isso seria desinteligência artificial. A cizânia se espalha porque os usuários aprendem que receberão mais cliques quanto mais agressivos forem, substituindo por raiva os argumentos de que não dispõem para confirmar as próprias convicções e as daqueles que pensam como ele (viés de confirmação).
Já se pregou no passado que se deve acreditar mesmo que seja absurdo, ou porque absurdo (ouçam os “améns” com que fanáticos brindam Bolsonaro). Também já se disse que o sono da razão produz monstros.
O neurocientista do Idor prefere desviar a atenção para efeitos não pretendidos positivos das tecnologias. Cita as possibilidades abertas para enfrentar a Covid-19 com telefones celulares de última geração disseminados pelo mundo, mesmo em países pobres, como difusão de informação e bases de dados para monitorar mobilidade em tempos de isolamento social.
Há também os aplicativos multiusuário de conversa com vídeo, que facilitam o contato para coordenação entre colegas trabalhando em casa, a deliberação parlamentar a distância e, claro, as teleconsultas entre médicos e pacientes.
Sonoo diz que a IA libera profissionais de saúde para exercerem mais o que está na base da medicina, cuidar de pessoas de carne e osso. Mesmo que seja em ambiente virtual, o grande médico se diferencia do médico apenas bom por tratar o doente, não a doença.
Fica tudo mais complicado quando o espectro do contágio pelo corona paira sobre todos e uma interface de vídeo ou a parafernália na UTI afasta o doutor do enfermo. Mas há dicas simples para humanizar esses encontros, de portar uma foto da pessoa por trás da máscara a perguntar a origem de objetos que se vê pela tela na casa do paciente (mais sugestões em inglês aqui: youtu.be/DbLjEsD1XOI).
Conversamos ainda sobre diversidade, equidade, acesso e outras coisas importantes. Para terminar, contudo, cabe destacar o chamado de Gito para embutir valores nos algoritmos e chamar filósofos e outros especialistas de humanidades para as equipes que inventam aplicações de IA.
Os dois governos mencionados, porém, são inimigos da humanidade, no singular (empatia, mas também conjunto de mulheres, homens, velhos, crianças, enfermos, sãos, deficientes, atletas, patriotas ou não, ateus e crentes) e no plural (disciplinas que se ocupam das fontes e razões do que dá certo ou dá errado nas sociedades humanas e na cabeça das pessoas que as compõem).
São os reis eleitos da desinteligência artificial.
Source: Vienna University of Technology, TU Vienna
Summary: With a mobile data collection app and satellite data, scientists will be able to predict whether a certain region is vulnerable to food shortages and malnutrition, say experts. By scanning Earth’s surface with microwave beams, researchers can measure the water content in soil. Comparing these measurements with extensive data sets obtained over the last few decades, it is possible to calculate whether the soil is sufficiently moist or whether there is danger of droughts. The method has now been tested in the Central African Republic.
Does drought lead to famine? A mobile app helps to collect information. Credit: Image courtesy of Vienna University of Technology, TU Vienna
With a mobile data collection app and satellite data, scientists will be able to predict whether a certain region is vulnerable to food shortages and malnutrition. The method has now been tested in the Central African Republic.
There are different possible causes for famine and malnutrition — not all of which are easy to foresee. Drought and crop failure can often be predicted by monitoring the weather and measuring soil moisture. But other risk factors, such as socio-economic problems or violent conflicts, can endanger food security too. For organizations such as Doctors without Borders / Médecins Sans Frontières (MSF), it is crucial to obtain information about vulnerable regions as soon as possible, so that they have a chance to provide help before it is too late.
Scientists from TU Wien in Vienna, Austria and the International Institute for Applied Systems Analysis (IIASA) in Laxenburg, Austria have now developed a way to monitor food security using a smartphone app, which combines weather and soil moisture data from satellites with crowd-sourced data on the vulnerability of the population, e.g. malnutrition and other relevant socioeconomic data. Tests in the Central African Republic have yielded promising results, which have now been published in the journal PLOS ONE.
Step One: Satellite Data
“For years, we have been working on methods of measuring soil moisture using satellite data,” says Markus Enenkel (TU Wien). By scanning Earth’s surface with microwave beams, researchers can measure the water content in soil. Comparing these measurements with extensive data sets obtained over the last few decades, it is possible to calculate whether the soil is sufficiently moist or whether there is danger of droughts. “This method works well and it provides us with very important information, but information about soil moisture deficits is not enough to estimate the danger of malnutrition,” says IIASA researcher Linda See. “We also need information about other factors that can affect the local food supply.” For example, political unrest may prevent people from farming, even if weather conditions are fine. Such problems can of course not be monitored from satellites, so the researchers had to find a way of collecting data directly in the most vulnerable regions.
“Today, smartphones are available even in developing countries, and so we decided to develop an app, which we called SATIDA COLLECT, to help us collect the necessary data,” says IIASA-based app developer Mathias Karner. For a first test, the researchers chose the Central African Republic- one of the world’s most vulnerable countries, suffering from chronic poverty, violent conflicts, and weak disaster resilience. Local MSF staff was trained for a day and collected data, conducting hundreds of interviews.
“How often do people eat? What are the current rates of malnutrition? Have any family members left the region recently, has anybody died? — We use the answers to these questions to statistically determine whether the region is in danger,” says Candela Lanusse, nutrition advisor from Doctors without Borders. “Sometimes all that people have left to eat is unripe fruit or the seeds they had stored for next year. Sometimes they have to sell their cattle, which may increase the chance of nutritional problems. This kind of behavior may indicate future problems, months before a large-scale crisis breaks out.”
A Map of Malnutrition Danger
The digital questionnaire of SATIDA COLLECT can be adapted to local eating habits, as the answers and the GPS coordinates of every assessment are stored locally on the phone. When an internet connection is available, the collected data are uploaded to a server and can be analyzed along with satellite-derived information about drought risk. In the end a map could be created, highlighting areas where the danger of malnutrition is high. For Doctors without Borders, such maps are extremely valuable. They help to plan future activities and provide help as soon as it is needed.
“Testing this tool in the Central African Republic was not easy,” says Markus Enenkel. “The political situation there is complicated. However, even under these circumstances we could show that our technology works. We were able to gather valuable information.” SATIDA COLLECT has the potential to become a powerful early warning tool. It may not be able to prevent crises, but it will at least help NGOs to mitigate their impacts via early intervention.
Markus Enenkel, Linda See, Mathias Karner, Mònica Álvarez, Edith Rogenhofer, Carme Baraldès-Vallverdú, Candela Lanusse, Núria Salse. Food Security Monitoring via Mobile Data Collection and Remote Sensing: Results from the Central African Republic. PLOS ONE, 2015; 10 (11): e0142030 DOI: 10.1371/journal.pone.0142030
Here’s an exercise: The next time you hear someone talking about algorithms, replace the term with “God” and ask yourself if the meaning changes. Our supposedly algorithmic culture is not a material phenomenon so much as a devotional one, a supplication made to the computers people have allowed to replace gods in their minds, even as they simultaneously claim that science has made us impervious to religion.
It’s part of a larger trend. The scientific revolution was meant to challenge tradition and faith, particularly a faith in religious superstition. But today, Enlightenment ideas like reason and science are beginning to flip into their opposites. Science and technology have become so pervasive and distorted, they have turned into a new type of theology.
The worship of the algorithm is hardly the only example of the theological reversal of the Enlightenment—for another sign, just look at the surfeit of nonfiction books promising insights into “The Science of…” anything, from laughter to marijuana. But algorithms hold a special station in the new technological temple because computers have become our favorite idols.
In fact, our purported efforts to enlighten ourselves about algorithms’ role in our culture sometimes offer an unexpected view into our zealous devotion to them. The media scholar Lev Manovich had this to say about “The Algorithms of Our Lives”:
Software has become a universal language, the interface to our imagination and the world. What electricity and the combustion engine were to the early 20th century, software is to the early 21st century. I think of it as a layer that permeates contemporary societies.
This is a common account of algorithmic culture, that software is a fundamental, primary structure of contemporary society. And like any well-delivered sermon, it seems convincing at first. Until we think a little harder about the historical references Manovich invokes, such as electricity and the engine, and how selectively those specimens characterize a prior era. Yes, they were important, but is it fair to call them paramount and exceptional?
It turns out that we have a long history of explaining the present via the output of industry. These rationalizations are always grounded in familiarity, and thus they feel convincing. But mostly they are metaphors. Here’s Nicholas Carr’s take on metaphorizing progress in terms of contemporary technology, from the 2008 Atlantic cover story that he expanded into his bestselling book The Shallows:
The process of adapting to new intellectual technologies is reflected in the changing metaphors we use to explain ourselves to ourselves. When the mechanical clock arrived, people began thinking of their brains as operating “like clockwork.” Today, in the age of software, we have come to think of them as operating “like computers.”
Carr’s point is that there’s a gap between the world and the metaphors people use to describe that world. We can see how erroneous or incomplete or just plain metaphorical these metaphors are when we look at them in retrospect.
Take the machine. In his book Images of Organization, Gareth Morgan describes the way businesses are seen in terms of different metaphors, among them the organization as machine, an idea that forms the basis for Taylorism.
Gareth Morgan’s metaphors of organization (Venkatesh Rao/Ribbonfarm)
We can find similar examples in computing. For Larry Lessig, the accidental homophony between “code” as the text of a computer program and “code” as the text of statutory law becomes the fulcrum on which his argument that code is an instrument of social control balances.
Each generation, we reset a belief that we’ve reached the end of this chain of metaphors, even though history always proves us wrong precisely because there’s always another technology or trend offering a fresh metaphor. Indeed, an exceptionalism that favors the present is one of the ways that science has become theology.
In fact, Carr fails to heed his own lesson about the temporariness of these metaphors. Just after having warned us that we tend to render current trends into contingent metaphorical explanations, he offers a similar sort of definitive conclusion:
Today, in the age of software, we have come to think of them as operating “like computers.” But the changes, neuroscience tells us, go much deeper than metaphor. Thanks to our brain’s plasticity, the adaptation occurs also at a biological level.
As with the machinic and computational metaphors that he critiques, Carr settles on another seemingly transparent, truth-yielding one. The real firmament is neurological, and computers are fitzing with our minds, a fact provable by brain science. And actually, software and neuroscience enjoy a metaphorical collaboration thanks to artificial intelligence’s idea that computing describes or mimics the brain. Compuplasting-as-thought reaches the rank of religious fervor when we choose to believe, as some do, that we can simulate cognition through computation and achieve the singularity.
* * *
The metaphor of mechanical automation has always been misleading anyway, with or without the computation. Take manufacturing. The goods people buy from Walmart appear safely ensconced in their blister packs, as if magically stamped out by unfeeling, silent machines (robots—those original automata—themselves run by the tinier, immaterial robots algorithms).
But the automation metaphor breaks down once you bother to look at how even the simplest products are really produced. The photographer Michael Wolf’s images of Chinese factory workers and the toys they fabricate show that finishing consumer goods to completion requires intricate, repetitive human effort.
Eyelashes must be glued onto dolls’ eyelids. Mickey Mouse heads must be shellacked. Rubber ducky eyes must be painted white. The same sort of manual work is required to create more complex goods too. Like your iPhone—you know, the one that’s designed in California but “assembled in China.” Even though injection-molding machines and other automated devices help produce all the crap we buy, the metaphor of the factory-as-automated machine obscures the fact that manufacturing isn’t as machinic nor as automated as we think it is.
The algorithmic metaphor is just a special version of the machine metaphor, one specifying a particular kind of machine (the computer) and a particular way of operating it (via a step-by-step procedure for calculation). And when left unseen, we are able to invent a transcendental ideal for the algorithm. The canonical algorithm is not just a model sequence but a concise and efficient one. In its ideological, mythic incarnation, the ideal algorithm is thought to be some flawless little trifle of lithe computer code, processing data into tapestry like a robotic silkworm. A perfect flower, elegant and pristine, simple and singular. A thing you can hold in your palm and caress. A beautiful thing. A divine one.
But just as the machine metaphor gives us a distorted view of automated manufacture as prime mover, so the algorithmic metaphor gives us a distorted, theological view of computational action.
“The Google search algorithm” names something with an initial coherence that quickly scurries away once you really look for it. Googling isn’t a matter of invoking a programmatic subroutine—not on its own, anyway. Google is a monstrosity. It’s a confluence of physical, virtual, computational, and non-computational stuffs—electricity, data centers, servers, air conditioners, security guards, financial markets—just like the rubber ducky is a confluence of vinyl plastic, injection molding, the hands and labor of Chinese workers, the diesel fuel of ships and trains and trucks, the steel of shipping containers.
Once you start looking at them closely, every algorithm betrays the myth of unitary simplicity and computational purity. You may remember the Netflix Prize, a million dollar competition to build a better collaborative filtering algorithm for film recommendations. In 2009, the company closed the book on the prize, adding a faux-machined “completed” stamp to its website.
But as it turns out, that method didn’t really improve Netflix’s performance very much. The company ended up downplaying the ratings and instead using something different to manage viewer preferences: very specific genres like “Emotional Hindi-Language Movies for Hopeless Romantics.” Netflix calls them “altgenres.”
An example of a Netflix altgenre in action (tumblr/Genres of Netflix)
While researching an in-depth analysis of altgenres published a year ago at The Atlantic, Alexis Madrigal scraped the Netflix site, downloading all 76,000+ micro-genres using not an algorithm but a hackneyed, long-running screen-scraping apparatus. After acquiring the data, Madrigal and I organized and analyzed it (by hand), and I built a generator that allowed our readers to fashion their own altgenres based on different grammars (like “Deep Sea Forbidden Love Mockumentaries” or “Coming-of-Age Violent Westerns Set in Europe About Cats”).
Netflix VP Todd Yellin explained to Madrigal why the process of generating altgenres is no less manual than our own process of reverse engineering them. Netflix trains people to watch films, and those viewers laboriously tag the films with lots of metadata, including ratings of factors like sexually suggestive content or plot closure. These tailored altgenres are then presented to Netflix customers based on their prior viewing habits.
One of the hypothetical, “gonzo” altgenres created by The Atlantic‘s Netflix Genre Generator (The Atlantic)
Despite the initial promise of the Netflix Prize and the lurid appeal of a “million dollar algorithm,” Netflix operates by methods that look more like the Chinese manufacturing processes Michael Wolf’s photographs document. Yes, there’s a computer program matching viewing habits to a database of film properties. But the overall work of the Netflix recommendation system is distributed amongst so many different systems, actors, and processes that only a zealot would call the end result an algorithm.
The same could be said for data, the material algorithms operate upon. Data has become just as theologized as algorithms, especially “big data,” whose name is meant to elevate information to the level of celestial infinity. Today, conventional wisdom would suggest that mystical, ubiquitous sensors are collecting data by the terabyteful without our knowledge or intervention. Even if this is true to an extent, examples like Netflix’s altgenres show that data is created, not simply aggregated, and often by means of laborious, manual processes rather than anonymous vacuum-devices.
Once you adopt skepticism toward the algorithmic- and the data-divine, you can no longer construe any computational system as merely algorithmic. Think about Google Maps, for example. It’s not just mapping software running via computer—it also involves geographical information systems, geolocation satellites and transponders, human-driven automobiles, roof-mounted panoramic optical recording systems, international recording and privacy law, physical- and data-network routing systems, and web/mobile presentational apparatuses. That’s not algorithmic culture—it’s just, well, culture.
* * *
If algorithms aren’t gods, what are they instead? Like metaphors, algorithms are simplifications, or distortions. They are caricatures. They take a complex system from the world and abstract it into processes that capture some of that system’s logic and discard others. And they couple to other processes, machines, and materials that carry out the extra-computational part of their work.
Unfortunately, most computing systems don’t want to admit that they are burlesques. They want to be innovators, disruptors, world-changers, and such zeal requires sectarian blindness. The exception is games, which willingly admit that they are caricatures—and which suffer the consequences of this admission in the court of public opinion. Games know that they are faking it, which makes them less susceptible to theologization. SimCity isn’t an urban planning tool, it’s a cartoon of urban planning. Imagine the folly of thinking otherwise! Yet, that’s precisely the belief people hold of Google and Facebook and the like.
A Google Maps Street View vehicle roams the streets of Washington D.C. Google Maps entails algorithms, but also other things, like internal combustion engine automobiles. (justgrimes/Flickr)
Just as it’s not really accurate to call the manufacture of plastic toys “automated,” it’s not quite right to call Netflix recommendations or Google Maps “algorithmic.” Yes, true, there are algorithmsw involved, insofar as computers are involved, and computers run software that processes information. But that’s just a part of the story, a theologized version of the diverse, varied array of people, processes, materials, and machines that really carry out the work we shorthand as “technology.” The truth is as simple as it is uninteresting: The world has a lot of stuff in it, all bumping and grinding against one another.
I don’t want to downplay the role of computation in contemporary culture. Striphas and Manovich are right—there are computers in and around everything these days. But the algorithm has taken on a particularly mythical role in our technology-obsessed era, one that has allowed it wear the garb of divinity. Concepts like “algorithm” have become sloppy shorthands, slang terms for the act of mistaking multipart complex systems for simple, singular ones. Of treating computation theologically rather than scientifically or culturally.
This attitude blinds us in two ways. First, it allows us to chalk up any kind of computational social change as pre-determined and inevitable. It gives us an excuse not to intervene in the social shifts wrought by big corporations like Google or Facebook or their kindred, to see their outcomes as beyond our influence. Second, it makes us forget that particular computational systems are abstractions, caricatures of the world, one perspective among many. The first error turns computers into gods, the second treats their outputs as scripture.
Computers are powerful devices that have allowed us to mimic countless other machines all at once. But in so doing, when pushed to their limits, that capacity to simulate anything reverses into the inability or unwillingness to distinguish one thing from anything else. In its Enlightenment incarnation, the rise of reason represented not only the ascendency of science but also the rise of skepticism, of incredulity at simplistic, totalizing answers, especially answers that made appeals to unseen movers. But today even as many scientists and technologists scorn traditional religious practice, they unwittingly invoke a new theology in so doing.
Algorithms aren’t gods. We need not believe that they rule the world in order to admit that they influence it, sometimes profoundly. Let’s bring algorithms down to earth again. Let’s keep the computer around without fetishizing it, without bowing down to it or shrugging away its inevitable power over us, without melting everything down into it as a new name for fate. I don’t want an algorithmic culture, especially if that phrase just euphemizes a corporate, computational theocracy.
But a culture with computers in it? That might be all right.
In a fascinating, apparently not-peer-reviewed non-article available free online here, Tommaso Venturini and Bruno Latour discuss the potential of “digital methods” for the contemporary social sciences.
The paper summarizes, and quite nicely, the split of sociological methods to the statistical aggregate using quantitative methods (capturing supposedly macro-phenomenon) and irreducibly basic interactions using qualitative methods (capturing supposedly micro-phenomenon). The problem is that neither of which aided the sociologist in capture emergent phenomenon, that is, capturing controversies and events as they happen rather than estimate them after they have emerged (quantitative macro structures) or capture them divorced from non-local influences (qualitative micro phenomenon).
The solution, they claim, is to adopt digital methods in the social sciences. The paper is not exactly a methodological outline of how to accomplish these methods, but there is something of a justification available for it, and it sounds something like this:
Thanks to digital traceability, researchers no longer need to choose between precision and scope in their observations: it is now possible to follow a multitude of interactions and, simultaneously, to distinguish the specific contribution that each one makes to the construction of social phenomena. Born in an era of scarcity, the social sciences are entering an age of abundance. In the face of the richness of these new data, nothing justifies keeping old distinctions. Endowed with a quantity of data comparable to the natural sciences, the social sciences can finally correct their lazy eyes and simultaneously maintain the focus and scope of their observations.













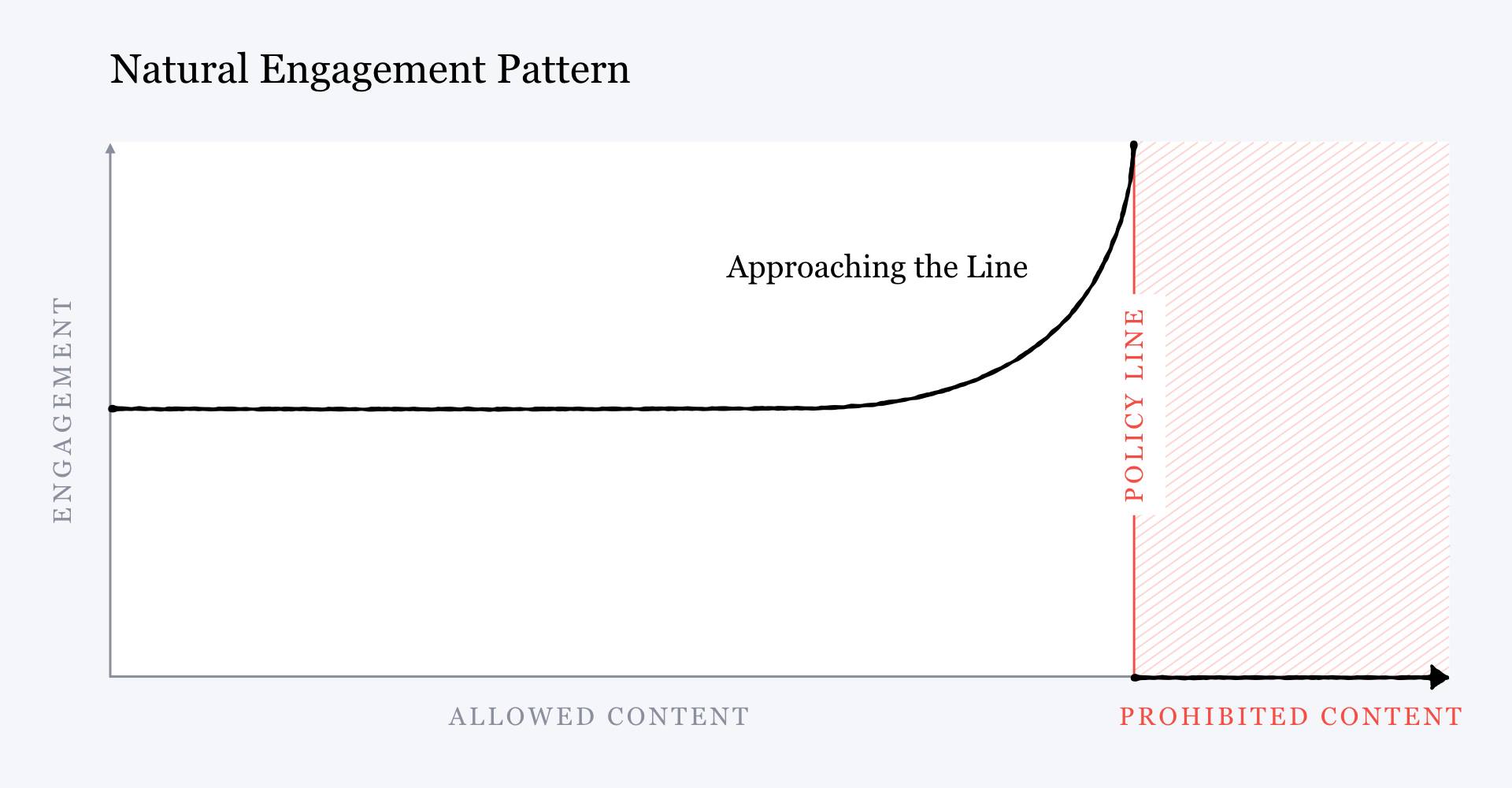
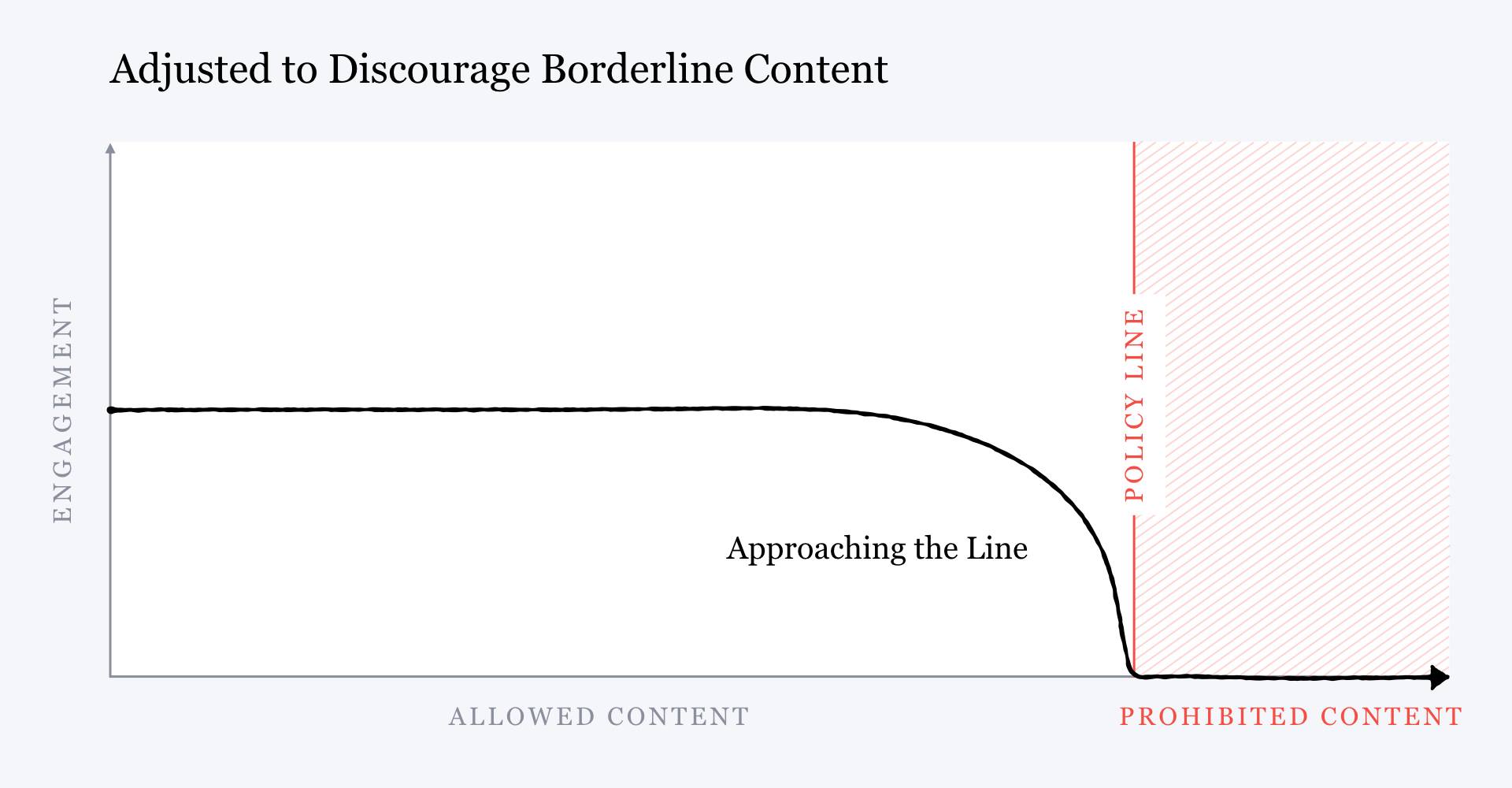













Você precisa fazer login para comentar.