Frances Haugen’s testimony at the Senate hearing today raised serious questions about how Facebook’s algorithms work—and echoes many findings from our previous investigation.
October 5, 2021
Karen Hao
Facebook whistleblower Frances Haugen testifies during a Senate Committee October 5. Drew Angerer/Getty Images
On Sunday night, the primary source for the Wall Street Journal’s Facebook Files, an investigative series based on internal Facebook documents, revealed her identity in an episode of 60 Minutes.
Frances Haugen, a former product manager at the company, says she came forward after she saw Facebook’s leadership repeatedly prioritize profit over safety.
Before quitting in May of this year, she combed through Facebook Workplace, the company’s internal employee social media network, and gathered a wide swath of internal reports and research in an attempt to conclusively demonstrate that Facebook had willfully chosen not to fix the problems on its platform.
Today she testified in front of the Senate on the impact of Facebook on society. She reiterated many of the findings from the internal research and implored Congress to act.
“I’m here today because I believe Facebook’s products harm children, stoke division, and weaken our democracy,” she said in her opening statement to lawmakers. “These problems are solvable. A safer, free-speech respecting, more enjoyable social media is possible. But there is one thing that I hope everyone takes away from these disclosures, it is that Facebook can change, but is clearly not going to do so on its own.”
During her testimony, Haugen particularly blamed Facebook’s algorithm and platform design decisions for many of its issues. This is a notable shift from the existing focus of policymakers on Facebook’s content policy and censorship—what does and doesn’t belong on Facebook. Many experts believe that this narrow view leads to a whack-a-mole strategy that misses the bigger picture.
“I’m a strong advocate for non-content-based solutions, because those solutions will protect the most vulnerable people in the world,” Haugen said, pointing to Facebook’s uneven ability to enforce its content policy in languages other than English.
Haugen’s testimony echoes many of the findings from an MIT Technology Review investigation published earlier this year, which drew upon dozens of interviews with Facebook executives, current and former employees, industry peers, and external experts. We pulled together the most relevant parts of our investigation and other reporting to give more context to Haugen’s testimony.
How does Facebook’s algorithm work?
Colloquially, we use the term “Facebook’s algorithm” as though there’s only one. In fact, Facebook decides how to target ads and rank content based on hundreds, perhaps thousands, of algorithms. Some of those algorithms tease out a user’s preferences and boost that kind of content up the user’s news feed. Others are for detecting specific types of bad content, like nudity, spam, or clickbait headlines, and deleting or pushing them down the feed.
All of these algorithms are known as machine-learning algorithms. As I wrote earlier this year:
Unlike traditional algorithms, which are hard-coded by engineers, machine-learning algorithms “train” on input data to learn the correlations within it. The trained algorithm, known as a machine-learning model, can then automate future decisions. An algorithm trained on ad click data, for example, might learn that women click on ads for yoga leggings more often than men. The resultant model will then serve more of those ads to women.
And because of Facebook’s enormous amounts of user data, it can
develop models that learned to infer the existence not only of broad categories like “women” and “men,” but of very fine-grained categories like “women between 25 and 34 who liked Facebook pages related to yoga,” and [target] ads to them. The finer-grained the targeting, the better the chance of a click, which would give advertisers more bang for their buck.
The same principles apply for ranking content in news feed:
Just as algorithms [can] be trained to predict who would click what ad, they [can] also be trained to predict who would like or share what post, and then give those posts more prominence. If the model determined that a person really liked dogs, for instance, friends’ posts about dogs would appear higher up on that user’s news feed.
Before Facebook began using machine-learning algorithms, teams used design tactics to increase engagement. They’d experiment with things like the color of a button or the frequency of notifications to keep users coming back to the platform. But machine-learning algorithms create a much more powerful feedback loop. Not only can they personalize what each user sees, they will also continue to evolve with a user’s shifting preferences, perpetually showing each person what will keep them most engaged.
Who runs Facebook’s algorithm?
Within Facebook, there’s no one team in charge of this content-ranking system in its entirety. Engineers develop and add their own machine-learning models into the mix, based on their team’s objectives. For example, teams focused on removing or demoting bad content, known as the integrity teams, will only train models for detecting different types of bad content.
This was a decision Facebook made early on as part of its “move fast and break things” culture. It developed an internal tool known as FBLearner Flow that made it easy for engineers without machine learning experience to develop whatever models they needed at their disposal. By one data point, it was already in use by more than a quarter of Facebook’s engineering team in 2016.
Many of the current and former Facebook employees I’ve spoken to say that this is part of why Facebook can’t seem to get a handle on what it serves up to users in the news feed. Different teams can have competing objectives, and the system has grown so complex and unwieldy that no one can keep track anymore of all of its different components.
As a result, the company’s main process for quality control is through experimentation and measurement. As I wrote:
Teams train up a new machine-learning model on FBLearner, whether to change the ranking order of posts or to better catch content that violates Facebook’s community standards (its rules on what is and isn’t allowed on the platform). Then they test the new model on a small subset of Facebook’s users to measure how it changes engagement metrics, such as the number of likes, comments, and shares, says Krishna Gade, who served as the engineering manager for news feed from 2016 to 2018.
If a model reduces engagement too much, it’s discarded. Otherwise, it’s deployed and continually monitored. On Twitter, Gade explained that his engineers would get notifications every few days when metrics such as likes or comments were down. Then they’d decipher what had caused the problem and whether any models needed retraining.
How has Facebook’s content ranking led to the spread of misinformation and hate speech?
During her testimony, Haugen repeatedly came back to the idea that Facebook’s algorithm incites misinformation, hate speech, and even ethnic violence.
“Facebook … knows—they have admitted in public—that engagement-based ranking is dangerous without integrity and security systems but then not rolled out those integrity and security systems in most of the languages in the world,” she told the Senate today. “It is pulling families apart. And in places like Ethiopia it is literally fanning ethnic violence.”
Here’s what I’ve written about this previously:
The machine-learning models that maximize engagement also favor controversy, misinformation, and extremism: put simply, people just like outrageous stuff.
Sometimes this inflames existing political tensions. The most devastating example to date is the case of Myanmar, where viral fake news and hate speech about the Rohingya Muslim minority escalated the country’s religious conflict into a full-blown genocide. Facebook admitted in 2018, after years of downplaying its role, that it had not done enough “to help prevent our platform from being used to foment division and incite offline violence.”
As Haugen mentioned, Facebook has also known this for a while. Previous reporting has found that it’s been studying the phenomenon since at least 2016.
In an internal presentation from that year, reviewed by the Wall Street Journal, a company researcher, Monica Lee, found that Facebook was not only hosting a large number of extremist groups but also promoting them to its users: “64% of all extremist group joins are due to our recommendation tools,” the presentation said, predominantly thanks to the models behind the “Groups You Should Join” and “Discover” features.
In 2017, Chris Cox, Facebook’s longtime chief product officer, formed a new task force to understand whether maximizing user engagement on Facebook was contributing to political polarization. It found that there was indeed a correlation, and that reducing polarization would mean taking a hit on engagement. In a mid-2018 document reviewed by the Journal, the task force proposed several potential fixes, such as tweaking the recommendation algorithms to suggest a more diverse range of groups for people to join. But it acknowledged that some of the ideas were “antigrowth.” Most of the proposals didn’t move forward, and the task force disbanded.
In my own conversations, Facebook employees also corroborated these findings.
A former Facebook AI researcher who joined in 2018 says he and his team conducted “study after study” confirming the same basic idea: models that maximize engagement increase polarization. They could easily track how strongly users agreed or disagreed on different issues, what content they liked to engage with, and how their stances changed as a result. Regardless of the issue, the models learned to feed users increasingly extreme viewpoints. “Over time they measurably become more polarized,” he says.
In her testimony, Haugen also repeatedly emphasized how these phenomena are far worse in regions that don’t speak English because of Facebook’s uneven coverage of different languages.
“In the case of Ethiopia there are 100 million people and six languages. Facebook only supports two of those languages for integrity systems,” she said. “This strategy of focusing on language-specific, content-specific systems for AI to save us is doomed to fail.”
She continued: “So investing in non-content-based ways to slow the platform down not only protects our freedom of speech, it protects people’s lives.”
I explore this more in a different article from earlier this year on the limitations of large language models, or LLMs:
Despite LLMs having these linguistic deficiencies, Facebook relies heavily on them to automate its content moderation globally. When the war in Tigray[, Ethiopia] first broke out in November, [AI ethics researcher Timnit] Gebru saw the platform flounder to get a handle on the flurry of misinformation. This is emblematic of a persistent pattern that researchers have observed in content moderation. Communities that speak languages not prioritized by Silicon Valley suffer the most hostile digital environments.
Gebru noted that this isn’t where the harm ends, either. When fake news, hate speech, and even death threats aren’t moderated out, they are then scraped as training data to build the next generation of LLMs. And those models, parroting back what they’re trained on, end up regurgitating these toxic linguistic patterns on the internet.
How does Facebook’s content ranking relate to teen mental health?
One of the more shocking revelations from the Journal’s Facebook Files was Instagram’s internal research, which found that its platform is worsening mental health among teenage girls. “Thirty-two percent of teen girls said that when they felt bad about their bodies, Instagram made them feel worse,” researchers wrote in a slide presentation from March 2020.
Haugen connects this phenomenon to engagement-based ranking systems as well, which she told the Senate today “is causing teenagers to be exposed to more anorexia content.”
“If Instagram is such a positive force, have we seen a golden age of teenage mental health in the last 10 years? No, we have seen escalating rates of suicide and depression amongst teenagers,” she continued. “There’s a broad swath of research that supports the idea that the usage of social media amplifies the risk of these mental health harms.”
In my own reporting, I heard from a former AI researcher who also saw this effect extend to Facebook.
The researcher’s team…found that users with a tendency to post or engage with melancholy content—a possible sign of depression—could easily spiral into consuming increasingly negative material that risked further worsening their mental health.
But as with Haugen, the researcher found that leadership wasn’t interested in making fundamental algorithmic changes.
The team proposed tweaking the content-ranking models for these users to stop maximizing engagement alone, so they would be shown less of the depressing stuff. “The question for leadership was: Should we be optimizing for engagement if you find that somebody is in a vulnerable state of mind?” he remembers.
But anything that reduced engagement, even for reasons such as not exacerbating someone’s depression, led to a lot of hemming and hawing among leadership. With their performance reviews and salaries tied to the successful completion of projects, employees quickly learned to drop those that received pushback and continue working on those dictated from the top down….
That former employee, meanwhile, no longer lets his daughter use Facebook.
How do we fix this?
Haugen is against breaking up Facebook or repealing Section 230 of the US Communications Decency Act, which protects tech platforms from taking responsibility for the content it distributes.
Instead, she recommends carving out a more targeted exemption in Section 230 for algorithmic ranking, which she argues would “get rid of the engagement-based ranking.” She also advocates for a return to Facebook’s chronological news feed.
Ellery Roberts Biddle, a projects director at Ranking Digital Rights, a nonprofit that studies social media ranking systems and their impact on human rights, says a Section 230 carve-out would need to be vetted carefully: “I think it would have a narrow implication. I don’t think it would quite achieve what we might hope for.”
In order for such a carve-out to be actionable, she says, policymakers and the public would need to have a much greater level of transparency into how Facebook’s ad-targeting and content-ranking systems even work. “I understand Haugen’s intention—it makes sense,” she says. “But it’s tough. We haven’t actually answered the question of transparency around algorithms yet. There’s a lot more to do.”
Nonetheless, Haugen’s revelations and testimony have brought renewed attention to what many experts and Facebook employees have been saying for years: that unless Facebook changes the fundamental design of its algorithms, it will not make a meaningful dent in the platform’s issues.
Her intervention also raises the prospect that if Facebook cannot put its own house in order, policymakers may force the issue.
“Congress can change the rules that Facebook plays by and stop the many harms it is now causing,” Haugen told the Senate. “I came forward at great personal risk because I believe we still have time to act, but we must act now.”
The Facebook engineer was itching to know why his date hadn’t responded to his messages. Perhaps there was a simple explanation—maybe she was sick or on vacation.
So at 10 p.m. one night in the company’s Menlo Park headquarters, he brought up her Facebook profile on the company’s internal systems and began looking at her personal data. Her politics, her lifestyle, her interests—even her real-time location.
The engineer would be fired for his behavior, along with 51 other employees who had inappropriately abused their access to company data, a privilege that was then available to everyone who worked at Facebook, regardless of their job function or seniority. The vast majority of the 51 were just like him: men looking up information about the women they were interested in.
In September 2015, after Alex Stamos, the new chief security officer, brought the issue to Mark Zuckerberg’s attention, the CEO ordered a system overhaul to restrict employee access to user data. It was a rare victory for Stamos, one in which he convinced Zuckerberg that Facebook’s design was to blame, rather than individual behavior.
So begins An Ugly Truth, a new book about Facebook written by veteran New York Times reporters Sheera Frenkel and Cecilia Kang. With Frenkel’s expertise in cybersecurity, Kang’s expertise in technology and regulatory policy, and their deep well of sources, the duo provide a compelling account of Facebook’s years spanning the 2016 and 2020 elections.
Stamos would no longer be so lucky. The issues that derived from Facebook’s business model would only escalate in the years that followed but as Stamos unearthed more egregious problems, including Russian interference in US elections, he was pushed out for making Zuckerberg and Sheryl Sandberg face inconvenient truths. Once he left, the leadership continued to refuse to address a whole host of profoundly disturbing problems, including the Cambridge Analytica scandal, the genocide in Myanmar, and rampant covid misinformation.
The authors, Cecilia Kang and Sheera Frenkel
Frenkel and Kang argue that Facebook’s problems today are not the product of a company that lost its way. Instead they are part of its very design, built atop Zuckerberg’s narrow worldview, the careless privacy culture he cultivated, and the staggering ambitions he chased with Sandberg.
When the company was still small, perhaps such a lack of foresight and imagination could be excused. But since then, Zuckerberg’s and Sandberg’s decisions have shown that growth and revenue trump everything else.
In a chapter titled “Company Over Country,” for example, the authors chronicle how the leadership tried to bury the extent of Russian election interference on the platform from the US intelligence community, Congress, and the American public. They censored the Facebook security team’s multiple attempts to publish details of what they had found, and cherry-picked the data to downplay the severity and partisan nature of the problem. When Stamos proposed a redesign of the company’s organization to prevent a repeat of the issue, other leaders dismissed the idea as “alarmist” and focused their resources on getting control of the public narrative and keeping regulators at bay.
In 2014, a similar pattern began to play out in Facebook’s response to the escalating violence in Myanmar, detailed in the chapter “Think Before You Share.” A year prior, Myanmar-based activists had already begun to warn the company about the concerning levels of hate speech and misinformation on the platform being directed at the country’s Rohingya Muslim minority. But driven by Zuckerberg’s desire to expand globally, Facebook didn’t take the warnings seriously.
When riots erupted in the country, the company further underscored their priorities. It remained silent in the face of two deaths and fourteen injured but jumped in the moment the Burmese government cut off Facebook access for the country. Leadership then continued to delay investments and platform changes that could have prevented the violence from getting worse because it risked reducing user engagement. By 2017, ethnic tensions had devolved into a full-blown genocide, which the UN later found had been “substantively contributed to” by Facebook, resulting in the killing of more than 24,000 Rohingya Muslims.
This is what Frenkel and Kang call Facebook’s “ugly truth.” Its “irreconcilable dichotomy” of wanting to connect people to advance society but also enrich its bottom line. Chapter after chapter makes abundantly clear that it isn’t possible to satisfy both—and Facebook has time again chosen the latter at the expense of the former.
The book is as much a feat of storytelling as it is reporting. Whether you have followed Facebook’s scandals closely as I have, or only heard bits and pieces at a distance, Frenkel and Kang weave it together in a way that leaves something for everyone. The detailed anecdotes take readers behind the scenes into Zuckerberg’s conference room known as “Aquarium,” where key decisions shaped the course of the company. The pacing of each chapter guarantees fresh revelations with every turn of the page.
While I recognized each of the events that the authors referenced, the degree to which the company sought to protect itself at the cost of others was still worse than I had previously known. Meanwhile, my partner who read it side-by-side with me and squarely falls into the second category of reader repeatedly looked up stunned by what he had learned.
The authors keep their own analysis light, preferring to let the facts speak for themselves. In this spirit, they demur at the end of their account from making any hard conclusions about what to do with Facebook, or where this leaves us. “Even if the company undergoes a radical transformation in the coming year,” they write, “that change is unlikely to come from within.” But between the lines, the message is loud and clear: Facebook will never fix itself.
Joaquin Quiñonero Candela, a director of AI at Facebook, was apologizing to his audience.
It was March 23, 2018, just days after the revelation that Cambridge Analytica, a consultancy that worked on Donald Trump’s 2016 presidential election campaign, had surreptitiously siphoned the personal data of tens of millions of Americans from their Facebook accounts in an attempt to influence how they voted. It was the biggest privacy breach in Facebook’s history, and Quiñonero had been previously scheduled to speak at a conference on, among other things, “the intersection of AI, ethics, and privacy” at the company. He considered canceling, but after debating it with his communications director, he’d kept his allotted time.
As he stepped up to face the room, he began with an admission. “I’ve just had the hardest five days in my tenure at Facebook,” he remembers saying. “If there’s criticism, I’ll accept it.”
The Cambridge Analytica scandal would kick off Facebook’s largest publicity crisis ever. It compounded fears that the algorithms that determine what people see on the platform were amplifying fake news and hate speech, and that Russian hackers had weaponized them to try to sway the election in Trump’s favor. Millions began deleting the app; employees left in protest; the company’s market capitalization plunged by more than $100 billion after its July earnings call.
In the ensuing months, Mark Zuckerberg began his own apologizing. He apologized for not taking “a broad enough view” of Facebook’s responsibilities, and for his mistakes as a CEO. Internally, Sheryl Sandberg, the chief operating officer, kicked off a two-year civil rights audit to recommend ways the company could prevent the use of its platform to undermine democracy.
Finally, Mike Schroepfer, Facebook’s chief technology officer, asked Quiñonero to start a team with a directive that was a little vague: to examine the societal impact of the company’s algorithms. The group named itself the Society and AI Lab (SAIL); last year it combined with another team working on issues of data privacy to form Responsible AI.
Quiñonero was a natural pick for the job. He, as much as anybody, was the one responsible for Facebook’s position as an AI powerhouse. In his six years at Facebook, he’d created some of the first algorithms for targeting users with content precisely tailored to their interests, and then he’d diffused those algorithms across the company. Now his mandate would be to make them less harmful.
Facebook has consistently pointed to the efforts by Quiñonero and others as it seeks to repair its reputation. It regularly trots out various leaders to speak to the media about the ongoing reforms. In May of 2019, it granted a series of interviews with Schroepfer to the New York Times, which rewarded the company with a humanizing profile of a sensitive, well-intentioned executive striving to overcome the technical challenges of filtering out misinformation and hate speech from a stream of content that amounted to billions of pieces a day. These challenges are so hard that it makes Schroepfer emotional, wrote the Times: “Sometimes that brings him to tears.”
In the spring of 2020, it was apparently my turn. Ari Entin, Facebook’s AI communications director, asked in an email if I wanted to take a deeper look at the company’s AI work. After talking to several of its AI leaders, I decided to focus on Quiñonero. Entin happily obliged. As not only the leader of the Responsible AI team but also the man who had made Facebook into an AI-driven company, Quiñonero was a solid choice to use as a poster boy.
He seemed a natural choice of subject to me, too. In the years since he’d formed his team following the Cambridge Analytica scandal, concerns about the spread of lies and hate speech on Facebook had only grown. In late 2018 the company admitted that this activity had helped fuel a genocidal anti-Muslim campaign in Myanmar for several years. In 2020 Facebook started belatedly taking action against Holocaust deniers, anti-vaxxers, and the conspiracy movement QAnon. All these dangerous falsehoods were metastasizing thanks to the AI capabilities Quiñonero had helped build. The algorithms that underpin Facebook’s business weren’t created to filter out what was false or inflammatory; they were designed to make people share and engage with as much content as possible by showing them things they were most likely to be outraged or titillated by. Fixing this problem, to me, seemed like core Responsible AI territory.
I began video-calling Quiñonero regularly. I also spoke to Facebook executives, current and former employees, industry peers, and external experts. Many spoke on condition of anonymity because they’d signed nondisclosure agreements or feared retaliation. I wanted to know: What was Quiñonero’s team doing to rein in the hate and lies on its platform?
Joaquin Quiñonero Candela outside his home in the Bay Area, where he lives with his wife and three kids.
But Entin and Quiñonero had a different agenda. Each time I tried to bring up these topics, my requests to speak about them were dropped or redirected. They only wanted to discuss the Responsible AI team’s plan to tackle one specific kind of problem: AI bias, in which algorithms discriminate against particular user groups. An example would be an ad-targeting algorithm that shows certain job or housing opportunities to white people but not to minorities.
By the time thousands of rioters stormed the US Capitol in January, organized in part on Facebook and fueled by the lies about a stolen election that had fanned out across the platform, it was clear from my conversations that the Responsible AI team had failed to make headway against misinformation and hate speech because it had never made those problems its main focus. More important, I realized, if it tried to, it would be set up for failure.
The reason is simple. Everything the company does and chooses not to do flows from a single motivation: Zuckerberg’s relentless desire for growth. Quiñonero’s AI expertise supercharged that growth. His team got pigeonholed into targeting AI bias, as I learned in my reporting, because preventing such bias helps the company avoid proposed regulation that might, if passed, hamper that growth. Facebook leadership has also repeatedly weakened or halted many initiatives meant to clean up misinformation on the platform because doing so would undermine that growth.
In other words, the Responsible AI team’s work—whatever its merits on the specific problem of tackling AI bias—is essentially irrelevant to fixing the bigger problems of misinformation, extremism, and political polarization. And it’s all of us who pay the price.
“When you’re in the business of maximizing engagement, you’re not interested in truth. You’re not interested in harm, divisiveness, conspiracy. In fact, those are your friends,” says Hany Farid, a professor at the University of California, Berkeley who collaborates with Facebook to understand image- and video-based misinformation on the platform.
“They always do just enough to be able to put the press release out. But with a few exceptions, I don’t think it’s actually translated into better policies. They’re never really dealing with the fundamental problems.”
In March of 2012, Quiñonero visited a friend in the Bay Area. At the time, he was a manager in Microsoft Research’s UK office, leading a team using machine learning to get more visitors to click on ads displayed by the company’s search engine, Bing. His expertise was rare, and the team was less than a year old. Machine learning, a subset of AI, had yet to prove itself as a solution to large-scale industry problems. Few tech giants had invested in the technology.
Quiñonero’s friend wanted to show off his new employer, one of the hottest startups in Silicon Valley: Facebook, then eight years old and already with close to a billion monthly active users (i.e., those who have logged in at least once in the past 30 days). As Quiñonero walked around its Menlo Park headquarters, he watched a lone engineer make a major update to the website, something that would have involved significant red tape at Microsoft. It was a memorable introduction to Zuckerberg’s “Move fast and break things” ethos. Quiñonero was awestruck by the possibilities. Within a week, he had been through interviews and signed an offer to join the company.
His arrival couldn’t have been better timed. Facebook’s ads service was in the middle of a rapid expansion as the company was preparing for its May IPO. The goal was to increase revenue and take on Google, which had the lion’s share of the online advertising market. Machine learning, which could predict which ads would resonate best with which users and thus make them more effective, could be the perfect tool. Shortly after starting, Quiñonero was promoted to managing a team similar to the one he’d led at Microsoft.
Quiñonero started raising chickens in late 2019 as a way to unwind from the intensity of his job.
Unlike traditional algorithms, which are hard-coded by engineers, machine-learning algorithms “train” on input data to learn the correlations within it. The trained algorithm, known as a machine-learning model, can then automate future decisions. An algorithm trained on ad click data, for example, might learn that women click on ads for yoga leggings more often than men. The resultant model will then serve more of those ads to women. Today at an AI-based company like Facebook, engineers generate countless models with slight variations to see which one performs best on a given problem.
Facebook’s massive amounts of user data gave Quiñonero a big advantage. His team could develop models that learned to infer the existence not only of broad categories like “women” and “men,” but of very fine-grained categories like “women between 25 and 34 who liked Facebook pages related to yoga,” and targeted ads to them. The finer-grained the targeting, the better the chance of a click, which would give advertisers more bang for their buck.
Within a year his team had developed these models, as well as the tools for designing and deploying new ones faster. Before, it had taken Quiñonero’s engineers six to eight weeks to build, train, and test a new model. Now it took only one.
News of the success spread quickly. The team that worked on determining which posts individual Facebook users would see on their personal news feeds wanted to apply the same techniques. Just as algorithms could be trained to predict who would click what ad, they could also be trained to predict who would like or share what post, and then give those posts more prominence. If the model determined that a person really liked dogs, for instance, friends’ posts about dogs would appear higher up on that user’s news feed.
Quiñonero’s success with the news feed—coupled with impressive new AI research being conducted outside the company—caught the attention of Zuckerberg and Schroepfer. Facebook now had just over 1 billion users, making it more than eight times larger than any other social network, but they wanted to know how to continue that growth. The executives decided to invest heavily in AI, internet connectivity, and virtual reality.
They created two AI teams. One was FAIR, a fundamental research lab that would advance the technology’s state-of-the-art capabilities. The other, Applied Machine Learning (AML), would integrate those capabilities into Facebook’s products and services. In December 2013, after months of courting and persuasion, the executives recruited Yann LeCun, one of the biggest names in the field, to lead FAIR. Three months later, Quiñonero was promoted again, this time to lead AML. (It was later renamed FAIAR, pronounced “fire.”)
“That’s how you know what’s on his mind. I was always, for a couple of years, a few steps from Mark’s desk.”
Joaquin Quiñonero Candela
In his new role, Quiñonero built a new model-development platform for anyone at Facebook to access. Called FBLearner Flow, it allowed engineers with little AI experience to train and deploy machine-learning models within days. By mid-2016, it was in use by more than a quarter of Facebook’s engineering team and had already been used to train over a million models, including models for image recognition, ad targeting, and content moderation.
Zuckerberg’s obsession with getting the whole world to use Facebook had found a powerful new weapon. Teams had previously used design tactics, like experimenting with the content and frequency of notifications, to try to hook users more effectively. Their goal, among other things, was to increase a metric called L6/7, the fraction of people who logged in to Facebook six of the previous seven days. L6/7 is just one of myriad ways in which Facebook has measured “engagement”—the propensity of people to use its platform in any way, whether it’s by posting things, commenting on them, liking or sharing them, or just looking at them. Now every user interaction once analyzed by engineers was being analyzed by algorithms. Those algorithms were creating much faster, more personalized feedback loops for tweaking and tailoring each user’s news feed to keep nudging up engagement numbers.
Zuckerberg, who sat in the center of Building 20, the main office at the Menlo Park headquarters, placed the new FAIR and AML teams beside him. Many of the original AI hires were so close that his desk and theirs were practically touching. It was “the inner sanctum,” says a former leader in the AI org (the branch of Facebook that contains all its AI teams), who recalls the CEO shuffling people in and out of his vicinity as they gained or lost his favor. “That’s how you know what’s on his mind,” says Quiñonero. “I was always, for a couple of years, a few steps from Mark’s desk.”
With new machine-learning models coming online daily, the company created a new system to track their impact and maximize user engagement. The process is still the same today. Teams train up a new machine-learning model on FBLearner, whether to change the ranking order of posts or to better catch content that violates Facebook’s community standards (its rules on what is and isn’t allowed on the platform). Then they test the new model on a small subset of Facebook’s users to measure how it changes engagement metrics, such as the number of likes, comments, and shares, says Krishna Gade, who served as the engineering manager for news feed from 2016 to 2018.
If a model reduces engagement too much, it’s discarded. Otherwise, it’s deployed and continually monitored. On Twitter, Gade explained that his engineers would get notifications every few days when metrics such as likes or comments were down. Then they’d decipher what had caused the problem and whether any models needed retraining.
But this approach soon caused issues. The models that maximize engagement also favor controversy, misinformation, and extremism: put simply, people just like outrageous stuff. Sometimes this inflames existing political tensions. The most devastating example to date is the case of Myanmar, where viral fake news and hate speech about the Rohingya Muslim minority escalated the country’s religious conflict into a full-blown genocide. Facebook admitted in 2018, after years of downplaying its role, that it had not done enough “to help prevent our platform from being used to foment division and incite offline violence.”
While Facebook may have been oblivious to these consequences in the beginning, it was studying them by 2016. In an internal presentation from that year, reviewed by the Wall Street Journal, a company researcher, Monica Lee, found that Facebook was not only hosting a large number of extremist groups but also promoting them to its users: “64% of all extremist group joins are due to our recommendation tools,” the presentation said, predominantly thanks to the models behind the “Groups You Should Join” and “Discover” features.
“The question for leadership was: Should we be optimizing for engagement if you find that somebody is in a vulnerable state of mind?”
A former AI researcher who joined in 2018
In 2017, Chris Cox, Facebook’s longtime chief product officer, formed a new task force to understand whether maximizing user engagement on Facebook was contributing to political polarization. It found that there was indeed a correlation, and that reducing polarization would mean taking a hit on engagement. In a mid-2018 document reviewed by the Journal, the task force proposed several potential fixes, such as tweaking the recommendation algorithms to suggest a more diverse range of groups for people to join. But it acknowledged that some of the ideas were “antigrowth.” Most of the proposals didn’t move forward, and the task force disbanded.
Since then, other employees have corroborated these findings. A former Facebook AI researcher who joined in 2018 says he and his team conducted “study after study” confirming the same basic idea: models that maximize engagement increase polarization. They could easily track how strongly users agreed or disagreed on different issues, what content they liked to engage with, and how their stances changed as a result. Regardless of the issue, the models learned to feed users increasingly extreme viewpoints. “Over time they measurably become more polarized,” he says.
The researcher’s team also found that users with a tendency to post or engage with melancholy content—a possible sign of depression—could easily spiral into consuming increasingly negative material that risked further worsening their mental health. The team proposed tweaking the content-ranking models for these users to stop maximizing engagement alone, so they would be shown less of the depressing stuff. “The question for leadership was: Should we be optimizing for engagement if you find that somebody is in a vulnerable state of mind?” he remembers. (A Facebook spokesperson said she could not find documentation for this proposal.)
But anything that reduced engagement, even for reasons such as not exacerbating someone’s depression, led to a lot of hemming and hawing among leadership. With their performance reviews and salaries tied to the successful completion of projects, employees quickly learned to drop those that received pushback and continue working on those dictated from the top down.
One such project heavily pushed by company leaders involved predicting whether a user might be at risk for something several people had already done: livestreaming their own suicide on Facebook Live. The task involved building a model to analyze the comments that other users were posting on a video after it had gone live, and bringing at-risk users to the attention of trained Facebook community reviewers who could call local emergency responders to perform a wellness check. It didn’t require any changes to content-ranking models, had negligible impact on engagement, and effectively fended off negative press. It was also nearly impossible, says the researcher: “It’s more of a PR stunt. The efficacy of trying to determine if somebody is going to kill themselves in the next 30 seconds, based on the first 10 seconds of video analysis—you’re not going to be very effective.”
Facebook disputes this characterization, saying the team that worked on this effort has since successfully predicted which users were at risk and increased the number of wellness checks performed. But the company does not release data on the accuracy of its predictions or how many wellness checks turned out to be real emergencies.
That former employee, meanwhile, no longer lets his daughter use Facebook.
Quiñonero should have been perfectly placed to tackle these problems when he created the SAIL (later Responsible AI) team in April 2018. His time as the director of Applied Machine Learning had made him intimately familiar with the company’s algorithms, especially the ones used for recommending posts, ads, and other content to users.
It also seemed that Facebook was ready to take these problems seriously. Whereas previous efforts to work on them had been scattered across the company, Quiñonero was now being granted a centralized team with leeway in his mandate to work on whatever he saw fit at the intersection of AI and society.
At the time, Quiñonero was engaging in his own reeducation about how to be a responsible technologist. The field of AI research was paying growing attention to problems of AI bias and accountability in the wake of high-profile studies showing that, for example, an algorithm was scoring Black defendants as more likely to be rearrested than white defendants who’d been arrested for the same or a more serious offense. Quiñonero began studying the scientific literature on algorithmic fairness, reading books on ethical engineering and the history of technology, and speaking with civil rights experts and moral philosophers.
Over the many hours I spent with him, I could tell he took this seriously. He had joined Facebook amid the Arab Spring, a series of revolutions against oppressive Middle Eastern regimes. Experts had lauded social media for spreading the information that fueled the uprisings and giving people tools to organize. Born in Spain but raised in Morocco, where he’d seen the suppression of free speech firsthand, Quiñonero felt an intense connection to Facebook’s potential as a force for good.
Six years later, Cambridge Analytica had threatened to overturn this promise. The controversy forced him to confront his faith in the company and examine what staying would mean for his integrity. “I think what happens to most people who work at Facebook—and definitely has been my story—is that there’s no boundary between Facebook and me,” he says. “It’s extremely personal.” But he chose to stay, and to head SAIL, because he believed he could do more for the world by helping turn the company around than by leaving it behind.
“I think if you’re at a company like Facebook, especially over the last few years, you really realize the impact that your products have on people’s lives—on what they think, how they communicate, how they interact with each other,” says Quiñonero’s longtime friend Zoubin Ghahramani, who helps lead the Google Brain team. “I know Joaquin cares deeply about all aspects of this. As somebody who strives to achieve better and improve things, he sees the important role that he can have in shaping both the thinking and the policies around responsible AI.”
At first, SAIL had only five people, who came from different parts of the company but were all interested in the societal impact of algorithms. One founding member, Isabel Kloumann, a research scientist who’d come from the company’s core data science team, brought with her an initial version of a tool to measure the bias in AI models.
The team also brainstormed many other ideas for projects. The former leader in the AI org, who was present for some of the early meetings of SAIL, recalls one proposal for combating polarization. It involved using sentiment analysis, a form of machine learning that interprets opinion in bits of text, to better identify comments that expressed extreme points of view. These comments wouldn’t be deleted, but they would be hidden by default with an option to reveal them, thus limiting the number of people who saw them.
And there were discussions about what role SAIL could play within Facebook and how it should evolve over time. The sentiment was that the team would first produce responsible-AI guidelines to tell the product teams what they should or should not do. But the hope was that it would ultimately serve as the company’s central hub for evaluating AI projects and stopping those that didn’t follow the guidelines.
Former employees described, however, how hard it could be to get buy-in or financial support when the work didn’t directly improve Facebook’s growth. By its nature, the team was not thinking about growth, and in some cases it was proposing ideas antithetical to growth. As a result, it received few resources and languished. Many of its ideas stayed largely academic.
On August 29, 2018, that suddenly changed. In the ramp-up to the US midterm elections, President Donald Trump and other Republican leaders ratcheted up accusations that Facebook, Twitter, and Google had anti-conservative bias. They claimed that Facebook’s moderators in particular, in applying the community standards, were suppressing conservative voices more than liberal ones. This charge would later be debunked, but the hashtag #StopTheBias, fueled by a Trump tweet, was rapidly spreading on social media.
For Trump, it was the latest effort to sow distrust in the country’s mainstream information distribution channels. For Zuckerberg, it threatened to alienate Facebook’s conservative US users and make the company more vulnerable to regulation from a Republican-led government. In other words, it threatened the company’s growth.
Facebook did not grant me an interview with Zuckerberg, but previousreporting has shown how he increasingly pandered to Trump and the Republican leadership. After Trump was elected, Joel Kaplan, Facebook’s VP of global public policy and its highest-ranking Republican, advised Zuckerberg to tread carefully in the new political environment.
On September 20, 2018, three weeks after Trump’s #StopTheBias tweet, Zuckerberg held a meeting with Quiñonero for the first time since SAIL’s creation. He wanted to know everything Quiñonero had learned about AI bias and how to quash it in Facebook’s content-moderation models. By the end of the meeting, one thing was clear: AI bias was now Quiñonero’s top priority. “The leadership has been very, very pushy about making sure we scale this aggressively,” says Rachad Alao, the engineering director of Responsible AI who joined in April 2019.
It was a win for everybody in the room. Zuckerberg got a way to ward off charges of anti-conservative bias. And Quiñonero now had more money and a bigger team to make the overall Facebook experience better for users. They could build upon Kloumann’s existing tool in order to measure and correct the alleged anti-conservative bias in content-moderation models, as well as to correct other types of bias in the vast majority of models across the platform.
This could help prevent the platform from unintentionally discriminating against certain users. By then, Facebook already had thousands of models running concurrently, and almost none had been measured for bias. That would get it into legal trouble a few months later with the US Department of Housing and Urban Development (HUD), which alleged that the company’s algorithms were inferring “protected” attributes like race from users’ data and showing them ads for housing based on those attributes—an illegal form of discrimination. (The lawsuit is still pending.) Schroepfer also predicted that Congress would soon pass laws to regulate algorithmic discrimination, so Facebook needed to make headway on these efforts anyway.
(Facebook disputes the idea that it pursued its work on AI bias to protect growth or in anticipation of regulation. “We built the Responsible AI team because it was the right thing to do,” a spokesperson said.)
But narrowing SAIL’s focus to algorithmic fairness would sideline all Facebook’s other long-standing algorithmic problems. Its content-recommendation models would continue pushing posts, news, and groups to users in an effort to maximize engagement, rewarding extremist content and contributing to increasingly fractured political discourse.
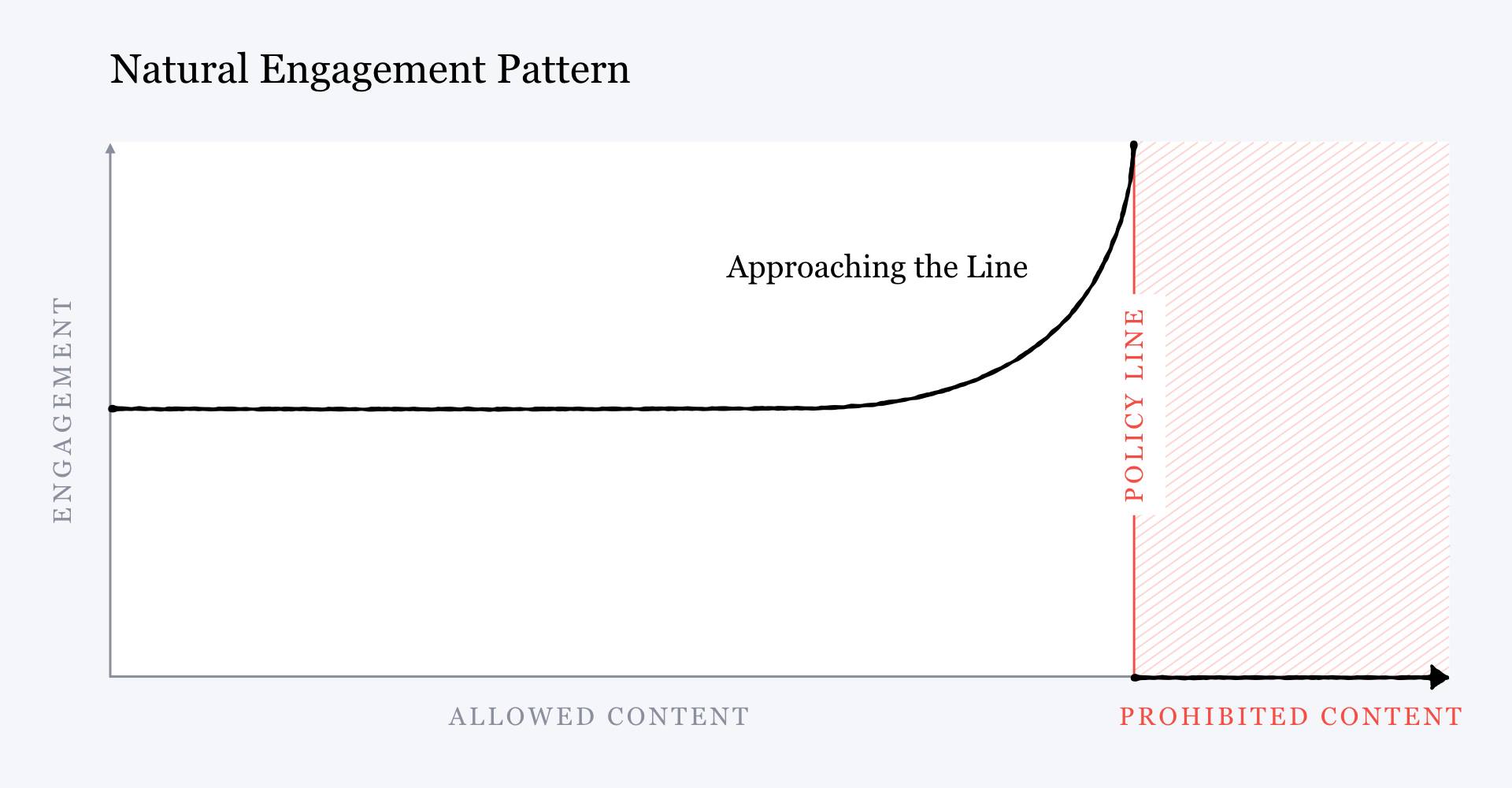
Zuckerberg even admitted this. Two months after the meeting with Quiñonero, in a public note outlining Facebook’s plans for content moderation, he illustrated the harmful effects of the company’s engagement strategy with a simplified chart. It showed that the more likely a post is to violate Facebook’s community standards, the more user engagement it receives, because the algorithms that maximize engagement reward inflammatory content.
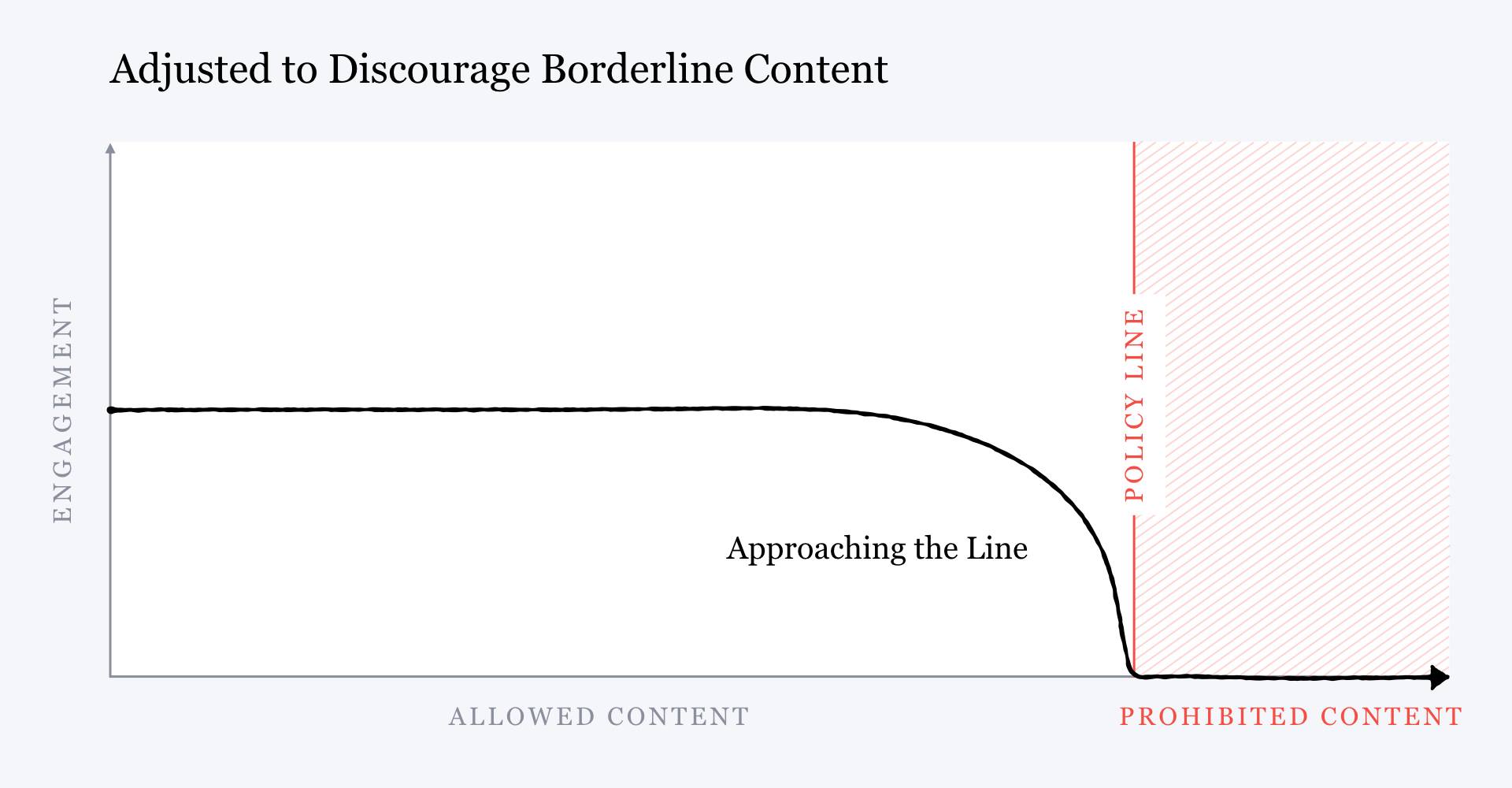
But then he showed another chart with the inverse relationship. Rather than rewarding content that came close to violating the community standards, Zuckerberg wrote, Facebook could choose to start “penalizing” it, giving it “less distribution and engagement” rather than more. How would this be done? With more AI. Facebook would develop better content-moderation models to detect this “borderline content” so it could be retroactively pushed lower in the news feed to snuff out its virality, he said.
The problem is that for all Zuckerberg’s promises, this strategy is tenuous at best.
Misinformation and hate speech constantly evolve. New falsehoods spring up; new people and groups become targets. To catch things before they go viral, content-moderation models must be able to identify new unwanted content with high accuracy. But machine-learning models do not work that way. An algorithm that has learned to recognize Holocaust denial can’t immediately spot, say, Rohingya genocide denial. It must be trained on thousands, often even millions, of examples of a new type of content before learning to filter it out. Even then, users can quickly learn to outwit the model by doing things like changing the wording of a post or replacing incendiary phrases with euphemisms, making their message illegible to the AI while still obvious to a human. This is why new conspiracy theories can rapidly spiral out of control, and partly why, even after such content is banned, forms of it canpersist on the platform.
In his New York Times profile, Schroepfer named these limitations of the company’s content-moderation strategy. “Every time Mr. Schroepfer and his more than 150 engineering specialists create A.I. solutions that flag and squelch noxious material, new and dubious posts that the A.I. systems have never seen before pop up—and are thus not caught,” wrote the Times. “It’s never going to go to zero,” Schroepfer told the publication.
Meanwhile, the algorithms that recommend this content still work to maximize engagement. This means every toxic post that escapes the content-moderation filters will continue to be pushed higher up the news feed and promoted to reach a larger audience. Indeed, a study from New York University recently found that among partisan publishers’ Facebook pages, those that regularly posted political misinformation received the most engagement in the lead-up to the 2020 US presidential election and the Capitol riots. “That just kind of got me,” says a former employee who worked on integrity issues from 2018 to 2019. “We fully acknowledged [this], and yet we’re still increasing engagement.”
But Quiñonero’s SAIL team wasn’t working on this problem. Because of Kaplan’s and Zuckerberg’s worries about alienating conservatives, the team stayed focused on bias. And even after it merged into the bigger Responsible AI team, it was never mandated to work on content-recommendation systems that might limit the spread of misinformation. Nor has any other team, as I confirmed after Entin and another spokesperson gave me a full list of all Facebook’s other initiatives on integrity issues—the company’s umbrella term for problems including misinformation, hate speech, and polarization.
A Facebook spokesperson said, “The work isn’t done by one specific team because that’s not how the company operates.” It is instead distributed among the teams that have the specific expertise to tackle how content ranking affects misinformation for their part of the platform, she said. But Schroepfer told me precisely the opposite in an earlier interview. I had asked him why he had created a centralized Responsible AI team instead of directing existing teams to make progress on the issue. He said it was “best practice” at the company.
“[If] it’s an important area, we need to move fast on it, it’s not well-defined, [we create] a dedicated team and get the right leadership,” he said. “As an area grows and matures, you’ll see the product teams take on more work, but the central team is still needed because you need to stay up with state-of-the-art work.”
When I described the Responsible AI team’s work to other experts on AI ethics and human rights, they noted the incongruity between the problems it was tackling and those, like misinformation, for which Facebook is most notorious. “This seems to be so oddly removed from Facebook as a product—the things Facebook builds and the questions about impact on the world that Facebook faces,” said Rumman Chowdhury, whose startup, Parity, advises firms on the responsible use of AI, and was acquired by Twitter after our interview. I had shown Chowdhury the Quiñonero team’s documentation detailing its work. “I find it surprising that we’re going to talk about inclusivity, fairness, equity, and not talk about the very real issues happening today,” she said.
“It seems like the ‘responsible AI’ framing is completely subjective to what a company decides it wants to care about. It’s like, ‘We’ll make up the terms and then we’ll follow them,’” says Ellery Roberts Biddle, the editorial director of Ranking Digital Rights, a nonprofit that studies the impact of tech companies on human rights. “I don’t even understand what they mean when they talk about fairness. Do they think it’s fair to recommend that people join extremist groups, like the ones that stormed the Capitol? If everyone gets the recommendation, does that mean it was fair?”
“We’re at a place where there’s one genocide [Myanmar] that the UN has, with a lot of evidence, been able to specifically point to Facebook and to the way that the platform promotes content,” Biddle adds. “How much higher can the stakes get?”
Over the last two years, Quiñonero’s team has built out Kloumann’s original tool, called Fairness Flow. It allows engineers to measure the accuracy of machine-learning models for different user groups. They can compare a face-detection model’s accuracy across different ages, genders, and skin tones, or a speech-recognition algorithm’s accuracy across different languages, dialects, and accents.
Fairness Flow also comes with a set of guidelines to help engineers understand what it means to train a “fair” model. One of the thornier problems with making algorithms fair is that there are different definitions of fairness, which can be mutually incompatible. Fairness Flow lists four definitions that engineers can use according to which suits their purpose best, such as whether a speech-recognition model recognizes all accents with equal accuracy or with a minimum threshold of accuracy.
But testing algorithms for fairness is still largely optional at Facebook. None of the teams that work directly on Facebook’s news feed, ad service, or other products are required to do it. Pay incentives are still tied to engagement and growth metrics. And while there are guidelines about which fairness definition to use in any given situation, they aren’t enforced.
This last problem came to the fore when the company had to deal with allegations of anti-conservative bias.
In 2014, Kaplan was promoted from US policy head to global vice president for policy, and he began playing a more heavy-handed role in content moderation and decisions about how to rank posts in users’ news feeds. After Republicans started voicing claims of anti-conservative bias in 2016, his team began manually reviewing the impact of misinformation-detection models on users to ensure—among other things—that they didn’t disproportionately penalize conservatives.
All Facebook users have some 200 “traits” attached to their profile. These include various dimensions submitted by users or estimated by machine-learning models, such as race, political and religious leanings, socioeconomic class, and level of education. Kaplan’s team began using the traits to assemble custom user segments that reflected largely conservative interests: users who engaged with conservative content, groups, and pages, for example. Then they’d run special analyses to see how content-moderation decisions would affect posts from those segments, according to a former researcher whose work was subject to those reviews.
The Fairness Flow documentation, which the Responsible AI team wrote later, includes a case study on how to use the tool in such a situation. When deciding whether a misinformation model is fair with respect to political ideology, the team wrote, “fairness” does not mean the model should affect conservative and liberal users equally. If conservatives are posting a greater fraction of misinformation, as judged by public consensus, then the model should flag a greater fraction of conservative content. If liberals are posting more misinformation, it should flag their content more often too.
But members of Kaplan’s team followed exactly the opposite approach: they took “fairness” to mean that these models should not affect conservatives more than liberals. When a model did so, they would stop its deployment and demand a change. Once, they blocked a medical-misinformation detector that had noticeably reduced the reach of anti-vaccine campaigns, the former researcher told me. They told the researchers that the model could not be deployed until the team fixed this discrepancy. But that effectively made the model meaningless. “There’s no point, then,” the researcher says. A model modified in that way “would have literally no impact on the actual problem” of misinformation.
“I don’t even understand what they mean when they talk about fairness. Do they think it’s fair to recommend that people join extremist groups, like the ones that stormed the Capitol? If everyone gets the recommendation, does that mean it was fair?”
Ellery Roberts Biddle, editorial director of Ranking Digital Rights
This happened countless other times—and not just for content moderation. In 2020, the Washington Post reported that Kaplan’s team had undermined efforts to mitigate election interference and polarization within Facebook, saying they could contribute to anti-conservative bias. In 2018, it used the same argument to shelve a project to edit Facebook’s recommendation models even though researchers believed it would reduce divisiveness on the platform, according to the Wall Street Journal. His claims about political bias also weakened a proposal to edit the ranking models for the news feed that Facebook’s data scientists believed would strengthen the platform against the manipulation tactics Russia had used during the 2016 US election.
And ahead of the 2020 election, Facebook policy executives used this excuse, according to the New York Times, to veto or weaken several proposals that would have reduced the spread of hateful and damaging content.
Facebook disputed the Wall Street Journal’s reporting in a follow-up blog post, and challenged the New York Times’s characterization in an interview with the publication. A spokesperson for Kaplan’s team also denied to me that this was a pattern of behavior, saying the cases reported by the Post, the Journal, and the Times were “all individual instances that we believe are then mischaracterized.” He declined to comment about the retraining of misinformation models on the record.
Many of these incidents happened before Fairness Flow was adopted. But they show how Facebook’s pursuit of fairness in the service of growth had already come at a steep cost to progress on the platform’s other challenges. And if engineers used the definition of fairness that Kaplan’s team had adopted, Fairness Flow could simply systematize behavior that rewarded misinformation instead of helping to combat it.
Often “the whole fairness thing” came into play only as a convenient way to maintain the status quo, the former researcher says: “It seems to fly in the face of the things that Mark was saying publicly in terms of being fair and equitable.”
The last time I spoke with Quiñonero was a month after the US Capitol riots. I wanted to know how the storming of Congress had affected his thinking and the direction of his work.
In the video call, it was as it always was: Quiñonero dialing in from his home office in one window and Entin, his PR handler, in another. I asked Quiñonero what role he felt Facebook had played in the riots and whether it changed the task he saw for Responsible AI. After a long pause, he sidestepped the question, launching into a description of recent work he’d done to promote greater diversity and inclusion among the AI teams.
I asked him the question again. His Facebook Portal camera, which uses computer-vision algorithms to track the speaker, began to slowly zoom in on his face as he grew still. “I don’t know that I have an easy answer to that question, Karen,” he said. “It’s an extremely difficult question to ask me.”
Entin, who’d been rapidly pacing with a stoic poker face, grabbed a red stress ball.
I asked Quiñonero why his team hadn’t previously looked at ways to edit Facebook’s content-ranking models to tamp down misinformation and extremism. He told me it was the job of other teams (though none, as I confirmed, have been mandated to work on that task). “It’s not feasible for the Responsible AI team to study all those things ourselves,” he said. When I asked whether he would consider having his team tackle those issues in the future, he vaguely admitted, “I would agree with you that that is going to be the scope of these types of conversations.”
Near the end of our hour-long interview, he began to emphasize that AI was often unfairly painted as “the culprit.” Regardless of whether Facebook used AI or not, he said, people would still spew lies and hate speech, and that content would still spread across the platform.
I pressed him one more time. Certainly he couldn’t believe that algorithms had done absolutely nothing to change the nature of these issues, I said.
“I don’t know,” he said with a halting stutter. Then he repeated, with more conviction: “That’s my honest answer. Honest to God. I don’t know.”
Corrections:We amended a line that suggested that Joel Kaplan, Facebook’s vice president of global policy, had used Fairness Flow. He has not. But members of his team have used the notion of fairness to request the retraining of misinformation models in ways that directly contradict Responsible AI’s guidelines. We also clarified when Rachad Alao, the engineering director of Responsible AI, joined the company.
During the initial phase of the internet, a “crowding-out” of political information occurred, which has affected voter turnout, new research shows.
The internet has transformed the way in which voters access and receive political information. It has allowed politicians to directly communicate their message to voters, circumventing the mainstream media which would traditionally filter information.
Writing in IZA World of Labor, Dr Heblich from the Department of Economics, presents research from a number of countries, comparing voter behaviour of municipalities with internet access to the ones without in the early 2000s. It shows municipalities with broadband internet access faced a decrease in voter turnout, due to voters suddenly facing an overwhelmingly large pool of information and not knowing how to filter relevant knowledge efficiently. Similarly, the internet seemed to have crowded out other media at the expense of information quality.
However, the introduction of interactive social media and “user-defined” content appears to have reversed this. It helped voters to collect information more efficiently. Barack Obama’s successful election campaign in 2008 set the path for this development. In the so-called “Facebook election,” Obama successfully employed Chris Hughes, a Facebook co-founder, to lead his highly effective election campaign.
Using a combination of social networks, podcasts, and mobile messages, Obama connected directly with (young) American voters. In doing so, he gained nearly 70 per cent of the votes among Americans under the age of 25.
But there is a downside: voters can now be personally identified and strategically influenced by targeted information. What if politicians use this information in election campaigns to target voters that are easy to mobilize?
Dr Heblich’s research shows there is a thin line between desirable benefits of more efficient information dissemination and undesirable possibilities of voter manipulation. Therefore, policymakers need to consider introducing measures to educate voters to become more discriminating in their use of the internet.
Dr Heblich said: “To the extent that online consumption replaces the consumption of other media (newspapers, radio, or television) with a higher information content, there may be no information gains for the average voter and, in the worst case, even a crowding- out of information.
“One potential risk relates to the increasing possibilities to collect personal information known as ‘big data’. This development could result in situations in which individual rights are violated, since the personal information could be used, for example, to selectively disseminate information in election campaigns and in influence voters strategically.”
Today, three researchers at Facebook published an article in Science on how Facebook’s newsfeed algorithm suppresses the amount of “cross-cutting” (i.e. likely to cause disagreement) news articles a person sees. I read a lot of academic research, and usually, the researchers are at a pains to highlight their findings. This one buries them as deep as it could, using a mix of convoluted language and irrelevant comparisons. So, first order of business is spelling out what they found. Also, for another important evaluation — with some overlap to this one — go read this post by University of Michigan professor Christian Sandvig.
The most important finding, if you ask me, is buried in an appendix. Here’s the chart showing that the higher an item is in the newsfeed, the more likely it is clicked on.
Notice how steep the curve is. The higher the link, more (a lot more) likely it will be clicked on. You live and die by placement, determined by the newsfeed algorithm. (The effect, as Sean J. Taylor correctly notes, is a combination of placement, and the fact that the algorithm is guessing what you would like). This was already known, mostly, but it’s great to have it confirmed by Facebook researchers (the study was solely authored by Facebook employees).
The most important caveat that is buried is that this study is not about all of Facebook users, despite language at the end that’s quite misleading. The researchers end their paper with: “Finally, we conclusively establish that on average in the context of Facebook…” No. The research was conducted on a small, skewed subset of Facebook users who chose to self-identify their political affiliation on Facebook and regularly log on to Facebook, about ~4% of the population available for the study. This is super important because this sampling confounds the dependent variable.
The gold standard of sampling is random, where every unit has equal chance of selection, which allows us to do amazing things like predict elections with tiny samples of thousands. Sometimes, researchers use convenience samples — whomever they can find easily — and those can be okay, or not, depending on how typical the sample ends up being compared to the universe. Sometimes, in cases like this, the sampling affects behavior: people who self-identify their politics are almost certainly going to behave quite differently, on average, than people who do not, when it comes to the behavior in question which is sharing and clicking through ideologically challenging content. So, everything in this study applies only to that small subsample of unusual people. (Here’s a post by the always excellent Eszter Hargittai unpacking the sampling issue further.) The study is still interesting, and important, but it is not a study that can generalize to Facebook users. Hopefully that can be a future study.
What does the study actually say?
Here’s the key finding: Facebook researchers conclusively show that Facebook’s newsfeed algorithm decreases ideologically diverse, cross-cutting content people see from their social networks on Facebook by a measurable amount. The researchers report that exposure to diverse content is suppressed by Facebook’s algorithm by 8% for self-identified liberals and by 5% for self-identified conservatives. Or, as Christian Sandvig puts it, “the algorithm filters out 1 in 20 cross-cutting hard news stories that a self-identified conservative sees (or 5%) and 1 in 13cross-cutting hard news stories that a self-identified liberal sees (8%).” You are seeing fewer news items that you’d disagree with which are shared by your friends because the algorithm is not showing them to you.
Now, here’s the part which will likely confuse everyone, but it should not. The researchers also report a separate finding that individual choice to limit exposure through clicking behavior results in exposure to 6% less diverse content for liberals and 17% less diverse content for conservatives.
Are you with me? One novel finding is that the newsfeed algorithm (modestly) suppresses diverse content, and another crucial and also novel finding is that placement in the feed is (strongly) influential of click-through rates.
Researchers then replicate and confirm a well-known, uncontested and long-established finding which is that people have a tendency to avoid content that challenges their beliefs. Then, confusingly, the researchers compare whether algorithm suppression effect size is stronger than people choosing what to click, and have a lot of language that leads Christian Sandvig to call this the “it’s not our fault” study. I cannot remember a worse apples to oranges comparison I’ve seen recently, especially since these two dynamics, algorithmic suppression and individual choice, have cumulative effects.
Comparing the individual choice to algorithmic suppression is like asking about the amount of trans fatty acids in french fries, a newly-added ingredient to the menu, and being told that hamburgers, which have long been on the menu, also have trans-fatty acids — an undisputed, scientifically uncontested and non-controversial fact. Individual self-selection in news sources long predates the Internet, and is a well-known, long-identified and well-studied phenomenon. Its scientific standing has never been in question. However, the role of Facebook’s algorithm in this process is a new — and important — issue. Just as the medical profession would be concerned about the amount of trans-fatty acids in the new item, french fries, as well as in the existing hamburgers, researchers should obviously be interested in algorithmic effects in suppressing diversity, in addition to long-standing research on individual choice, since the effects are cumulative. An addition, not a comparison, is warranted.
Imagine this (imperfect) analogy where many people were complaining, say, a washing machine has a faulty mechanism that sometimes destroys clothes. Now imagine washing machine company research paper which finds this claim is correct for a small subsample of these washing machines, and quantifies that effect, but also looks into how many people throw out their clothes before they are totally worn out, a well-established, undisputed fact in the scientific literature. The correct headline would not be “people throwing out used clothes damages more dresses than the the faulty washing machine mechanism.” And if this subsample was drawn from one small factory located everywhere else than all the other factories that manufacture the same brand, and produced only 4% of the devices, the headline would not refer to all washing machines, and the paper would not (should not) conclude with a claim about the average washing machine.
Also, in passing the paper’s conclusion appears misstated. Even though the comparison between personal choice and algorithmic effects is not very relevant, the result is mixed, rather than “conclusively establish[ing] that on average in the context of Facebook individual choices more than algorithms limit exposure to attitude-challenging content”. For self-identified liberals, the algorithm was a stronger suppressor of diversity (8% vs. 6%) while for self-identified conservatives, it was a weaker one (5% vs 17%).)
Also, as Christian Sandvig states in this post, and Nathan Jurgenson in this important post here, and David Lazer in the introduction to the piece in Science explore deeply, the Facebook researchers are not studying some neutral phenomenon that exists outside of Facebook’s control. The algorithm is designed by Facebook, and is occasionally re-arranged, sometimes to the devastation of groups who cannot pay-to-play for that all important positioning. I’m glad that Facebook is choosing to publish such findings, but I cannot but shake my head about how the real findings are buried, and irrelevant comparisons take up the conclusion. Overall, from all aspects, this study confirms that for this slice of politically-engaged sub-population, Facebook’s algorithm is a modest suppressor of diversity of content people see on Facebook, and that newsfeed placement is a profoundly powerful gatekeeper for click-through rates. This, not all the roundabout conversation about people’s choices, is the news.
Late Addition: Contrary to some people’s impressions, I am not arguing against all uses of algorithms in making choices in what we see online. The questions that concern me are how these algorithms work, what their effects are, who controls them, and what are the values that go into the design choices. At a personal level, I’d love to have the choice to set my newsfeed algorithm to “please show me more content I’d likely disagree with” — something the researchers prove that Facebook is able to do.