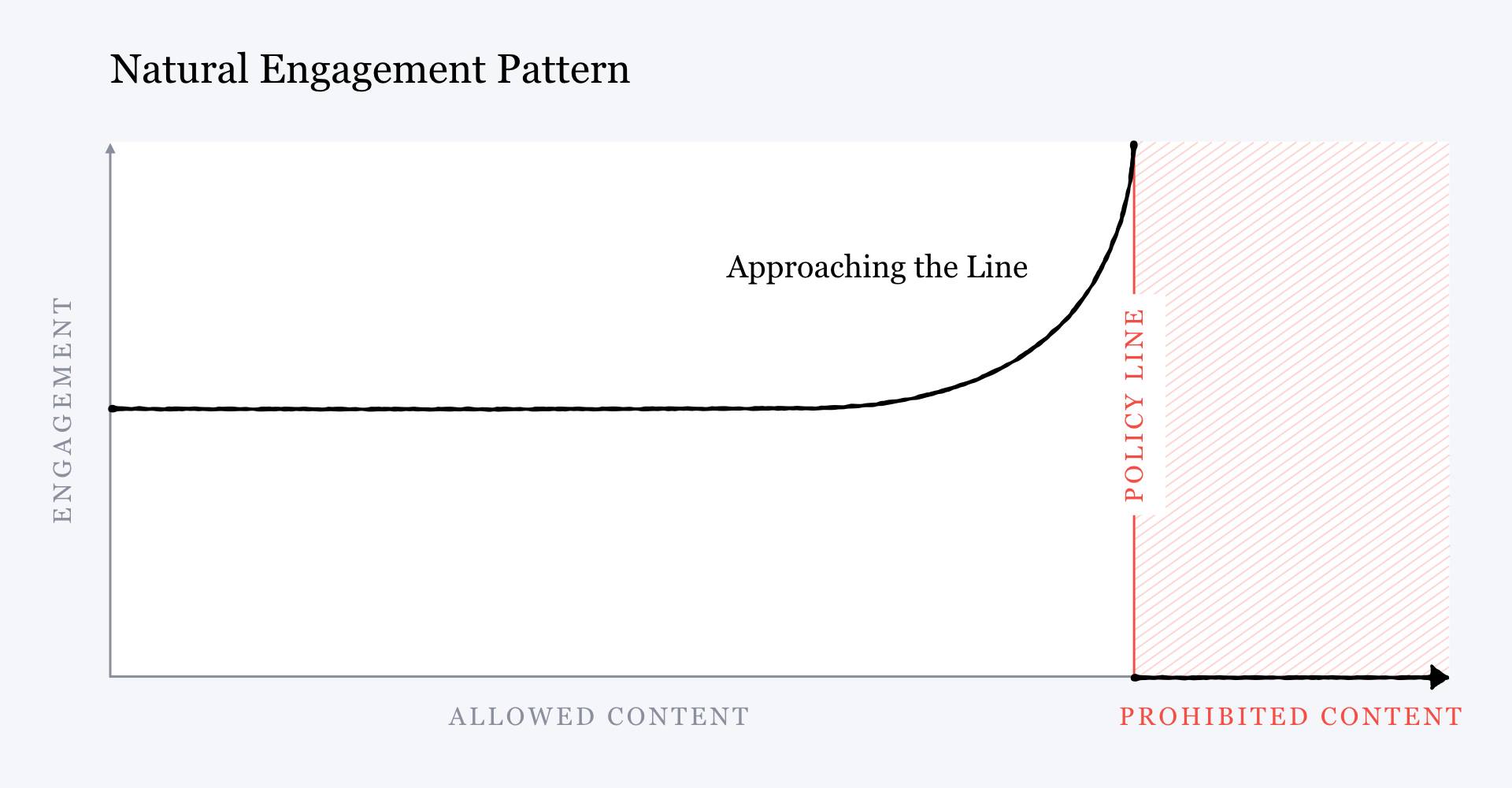
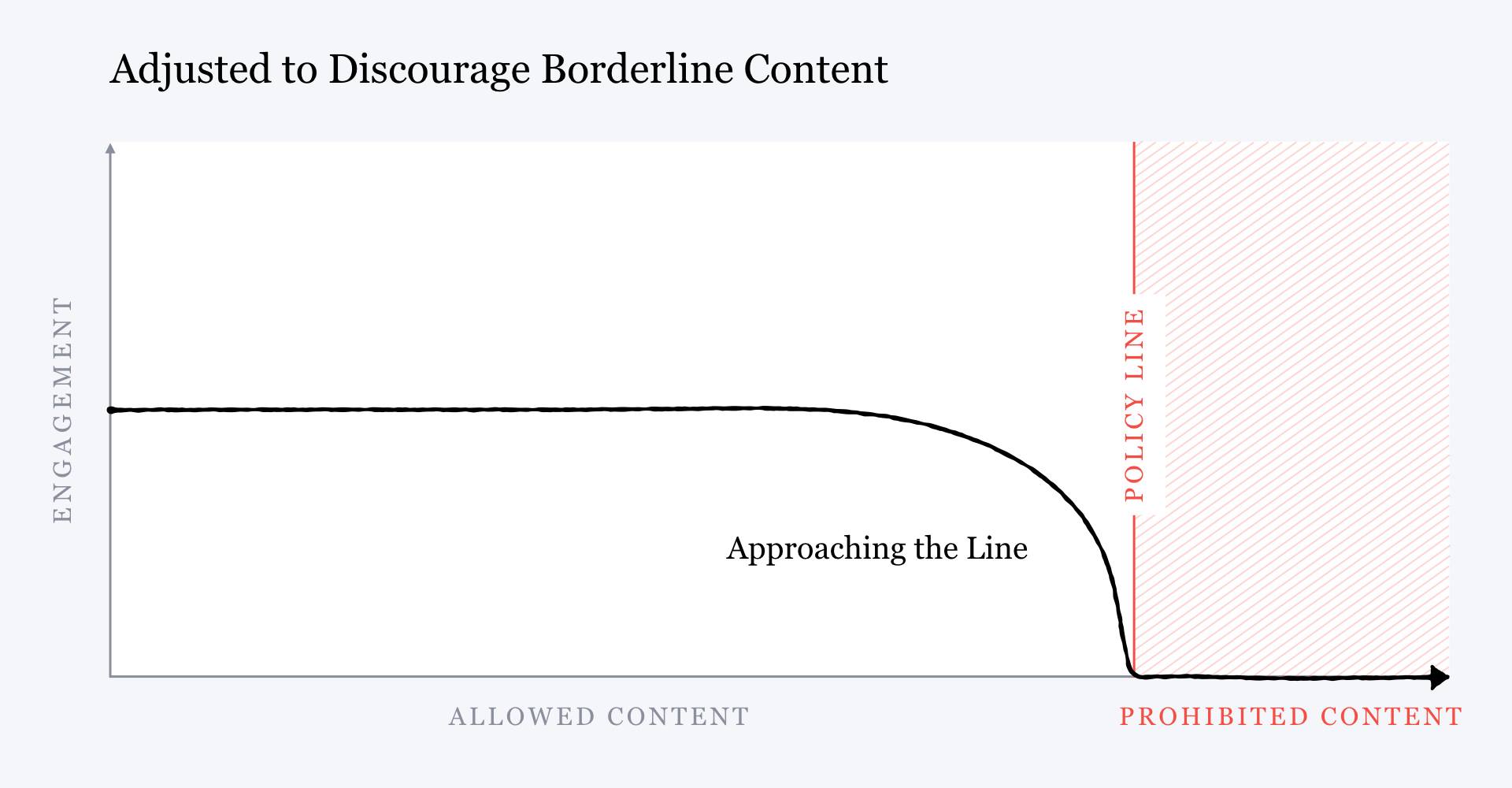
We are suffering through a pandemic of lies — or so we hear from leading voices in media, politics, and academia. Our culture is infected by a disease that has many names: fake news, post-truth, misinformation, disinformation, mal-information, anti-science. The affliction, we are told, is a perversion of the proper role of knowledge in a healthy information society.
What is to be done? To restore truth, we need strategies to “get the facts straight.” For example, we need better “science communication,” “independent fact-checking,” and a relentless commitment to exposing and countering falsehoods. This is why the Washington Post fastidiously counted 30,573 “false or misleading claims” by President Trump during his four years in office. Facebook, meanwhile, partners with eighty organizations worldwide to help it flag falsehoods and inform users of the facts. And some disinformation experts recently suggested in the New York Times that the Biden administration should appoint a “reality czar,” a central authority tasked with countering conspiracy theories about Covid and election fraud, who “could become the tip of the spear for the federal government’s response to the reality crisis.”
Such efforts reflect the view that untruth is a plague on our information society, one that can and must be cured. If we pay enough responsible, objective attention to distinguishing what is true from what is not, and thus excise misinformation from the body politic, people can be kept safe from falsehood. Put another way, it is an implicitly Edenic belief in the original purity of the information society, a state we have lapsed from but can yet return to, by the grace of fact-checkers.
We beg to differ. Fake news is not a perversion of the information society but a logical outgrowth of it, a symptom of the decades-long devolution of the traditional authority for governing knowledge and communicating information. That authority has long been held by a small number of institutions. When that kind of monopoly is no longer possible, truth itself must become contested.
This is treacherous terrain. The urge to insist on the integrity of the old order is widespread: Truth is truth, lies are lies, and established authorities must see to it that nobody blurs the two. But we also know from history that what seemed to be stable regimes of truth may collapse, and be replaced. If that is what is happening now, then the challenge is to manage the transition, not to cling to the old order as it dissolves around us.
Truth, New and Improved
The emergence of widespread challenges to the control of information by mainstream social institutions developed in three phases.
First, new technologies of mass communication in the twentieth century — radio, television, and significant improvements in printing, further empowered by new social science methods — enabled the rise of mass-market advertising, which quickly became an essential tool for success in the marketplace. Philosophers like Max Horkheimer and Theodor Adorno were bewildered by a world where, thanks to these new forms of communication, unabashed lies in the interest of selling products could become not just an art but an industry.
The rise of mass marketing created the cultural substrate for the so-called post-truth world we live in now. It normalized the application of hyperbole, superlatives, and untestable claims of superiority to the rhetoric of everyday commerce. What started out as merely a way to sell new and improved soap powder and automobiles amounts today to a rhetorical infrastructure of hype that infects every corner of culture: the way people promote their careers, universities their reputations, governments their programs, and scientists the importance of their latest findings. Whether we’re listening to a food corporation claim that its oatmeal will keep your heart healthy or a university press office herald a new study that will upend everything we know, radical skepticism would seem to be the rational stance for information consumers.
Politics, Scientized
In a second, partly overlapping phase in the twentieth century, science underwent a massive expansion of its role into the domain of public affairs, and thus into highly contestable subject matters. Spurred by a wealth of new instruments for measuring the world and techniques for analyzing the resulting data, policies on agriculture, health, education, poverty, national security, the environment and much more became subject to new types of scientific investigation. As never before, science became part of the language of policymaking, and scientists became advocates for particular policies.
The dissolving boundary between science and politics was on full display by 1958, when the chemist Linus Pauling and physicist Edward Teller debated the risks of nuclear weapons testing on a U.S. television broadcast, a spectacle that mixed scientific claims about fallout risks with theories of international affairs and assertions of personal moral conviction. The debate presaged a radical transformation of science and its social role. Where science was once a rarefied, elite practice largely isolated from society, scientific experts were now mobilized in increasing numbers to form and inform politics and policymaking. Of course, society had long been shaped, sometimes profoundly, by scientific advances. But in the second half of the twentieth century, science programs started to take on a rapidly expanding portfolio of politically divisive issues: determining the cancer-causing potential of food additives, pesticides, and tobacco; devising strategies for the U.S. government in its nuclear arms race against the Soviet Union; informing guidelines for diet, nutrition, and education; predicting future energy supplies, food supplies, and population growth; designing urban renewal programs; choosing nuclear waste disposal sites; and on and on.
Philosopher-mathematicians Silvio Funtowicz and Jerome Ravetz recognized in 1993 that a new kind of science was emerging, which they termed “post-normal science.” This kind of science was inherently contestable, both because it dealt with the irreducible uncertainties of complex and messy problems at the intersection of nature and society, and because it was being used for making decisions that were themselves value-laden and contested. Questions that may sound straightforward, such as “Should women in their forties get regular mammograms?” or “Will genetically modified crops and livestock make food more affordable?” or “Do the benefits of decarbonizing our energy production outweigh the costs?” became the focus of intractable and never-ending scientific and political disputes.
This situation remained reasonably manageable through the 1990s, because science communication was still largely controlled by powerful institutions: governments, corporations, and universities. Even if these institutions were sometimes fiercely at odds, all had a shared interest in maintaining the idea of a unitary science that provided universal truths upon which rational action should be based. Debates between experts may have raged — often without end — but one could still defend the claim that the search for truth was a coherent activity carried out by special experts working in pertinent social institutions, and that the truths emerging from their work would be recognizable and agreed-upon when finally they were determined. Few questioned the fundamental notion that science was necessary and authoritative for determining good policy choices across a wide array of social concerns. The imperative remained to find facts that could inform action — a basic tenet of Enlightenment rationality.
Science, Democratized
The rise of the Internet and social media marks the third phase of the story, and it has now rendered thoroughly implausible any institutional monopoly on factual claims. As we are continuing to see with Covid, the public has instantly available to it a nearly inexhaustible supply of competing and contradictory claims, made by credentialed experts associated with august institutions, about everything from mask efficacy to appropriate social distancing and school closure policies. And many of the targeted consumers of these claims are already conditioned to be highly skeptical of the information they receive from mainstream media.
Today’s information environment certainly invites mischievous seeding of known lies into public discourse. But bad actors are not the most important part of the story. Institutions can no longer maintain their old stance of authoritative certainty about information — the stance they need to justify their actions, or to establish a convincing dividing line between true news and fake news. Claims of disinterest by experts acting on behalf of these institutions are no longer plausible. People are free to decide what information, and in which experts, they want to believe. The Covid lab-leak hypothesis was fake news until that news itself became fake. Fact-checking organizations are themselves now subject to accusations of bias: Recently, Facebook flagged as “false” a story in the esteemed British Medical Journal about a shoddy Covid vaccine trial, and the editors of the journal in turn called Facebook’s fact-checking “inaccurate, incompetent and irresponsible.”
No political system exists without its share of lies, obfuscation, and fake news, as Plato and Machiavelli taught. Yet even those thinkers would be puzzled by the immense power of modern technologies to generate stories. Ideas have become a battlefield, and we are all getting lost in the fog of the truth wars. When everything seems like it can be plausible to someone, the term “fake news” loses its meaning.
iStock
The celebrated expedient that an aristocracy has the right and the mission to offer “noble lies” to the citizens for their own good thus looks increasingly impotent. In October 2020, U.S. National Institutes of Health director Francis Collins, a veritable aristocrat of the scientific establishment, sought to delegitimize the recently released Great Barrington Declaration. Crafted by a group he referred to as “fringe epidemiologists” (they were from Harvard, Stanford, and Oxford), the declaration questioned the mainstream lockdown approach to the pandemic, including school and business closures. “There needs to be a quick and devastating published take down,” Collins wrote in an email to fellow aristocrat Anthony Fauci.
But we now live in a moment where suppressing that kind of dissent has become impossible. By May 2021, that “fringe” became part of a new think tank, the Brownstone Institute, founded in reaction to what they describe as “the global crisis created by policy responses to the Covid-19 pandemic.” From this perspective, policies advanced by Collins and Fauci amounted to “a failed experiment in full social and economic control” reflecting “a willingness on the part of the public and officials to relinquish freedom and fundamental human rights in the name of managing a public health crisis.” The Brownstone Institute’s website is a veritable one-stop Internet shopping haven for anyone looking for well-credentialed expert opinions that counter more mainstream expert opinions on Covid.
Similarly, claims that the science around climate change is “settled,” and that therefore the world must collectively work to decarbonize the global energy system by 2050, have engendered a counter-industry of dissenting experts, organizations, and websites.
At this point, one might be forgiven for speculating that the public is being fed such a heavy diet of Covid and climate change precisely because these are problems that have been framed politically as amenable to a scientific treatment. But it seems that the more the authoritiesinsist on the factiness of facts, the more suspect these become to larger and larger portions of the populace.
A Scientific Reformation
The introduction of the printing press in the mid-fifteenth century triggered a revolution in which the Church lost its monopoly on truth. Millions of books were printed in just a few decades after Gutenberg’s innovation. Some people held the printing press responsible for stoking collective economic manias and speculative bubbles. It allowed the widespread distribution of astrological almanacs in Europe, which fed popular hysteria around prophesies of impending doom. And it allowed dissemination of the Malleus Maleficarum, an influential treatise on demonology that contributed to rising persecution of witches.
Though the printing press allowed sanctioned ideas to spread like never before, it also allowed the spread of serious but hitherto suppressed ideas that threatened the legitimacy of the Church. A range of alternative philosophical, moral, and ideological perspectives on Christianity became newly accessible to ever-growing audiences. So did exposés of institutional corruption, such as the practice of indulgences — a market for buying one’s way out of purgatory that earned the Church vast amounts of money. Martin Luther, in particular, understood and exploited the power of the printing press in pursuing his attacks on the Church — one recent historical account, Andrew Pettegree’s book Brand Luther, portrays him as the first mass-market communicator.
“Beginning of the Reformation”: Martin Luther directs the posting of his Ninety-five Theses, protesting the practice of the sale of indulgences, to the door of the castle church in Wittenberg on October 31, 1517. W. Baron von Löwenstern, 1830 / Library of Congress
To a religious observer living through the beginning of the Reformation, the proliferation of printed material must have appeared unsettling and dangerous: the end of an era, and the beginning of a threatening period of heterodoxy, heresies, and confusion. A person exposed to the rapid, unchecked dispersion of printed matter in the fifteenth century might have called many such publications fake news. Today many would say that it was the Reformation itself that did away with fake news, with the false orthodoxies of a corrupted Church, opening up a competition over ideas that became the foundation of the modern world. Whatever the case, this new world was neither neat nor peaceful, with the religious wars resulting from the Church’s loss of authority over truth continuing until the mid-seventeenth century.
Like the printing press in the fifteenth century, the Internet in the twenty-first has radically transformed and disrupted conventional modes of communication, destroyed the existing structure of authority over truth claims, and opened the door to a period of intense and tumultuous change.
Those who lament the death of truth should instead acknowledge the end of a monopoly system. Science was the pillar of modernity, the new privileged lens to interpret the real world and show a pathway to collective good. Science was not just an ideal but the basis for a regime, a monopoly system. Within this regime, truth was legitimized in particular private and public institutions, especially government agencies, universities, and corporations; it was interpreted and communicated by particular leaders of the scientific community, such as government science advisors, Nobel Prize winners, and the heads of learned societies; it was translated for and delivered to the laity in a wide variety of public and political contexts; it was presumed to point directly toward right action; and it was fetishized by a culture that saw it as single and unitary, something that was delivered by science and could be divorced from the contexts in which it emerged.
Such unitary truths included above all the insistence that the advance of science and technology would guarantee progress and prosperity for everyone — not unlike how the Church’s salvific authority could guarantee a negotiated process for reducing one’s punishment for sins. To achieve this modern paradise, certain subsidiary truths lent support. One, for example, held that economic rationality would illuminate the path to universal betterment, driven by the principle of comparative advantage and the harmony of globalized free markets. Another subsidiary truth expressed the social cost of carbon emissions with absolute precision to the dollar per ton, with the accompanying requirement that humans must control the global climate to the tenth of a degree Celsius. These ideas are self-evidently political, requiring monopolistic control of truth to implement their imputed agendas.
An easy prophesy here is that wars over scientific truth will intensify, as did wars over religious truth after the printing press. Those wars ended with the Peace of Westphalia in 1648, followed, eventually, by the creation of a radically new system of governance, the nation-state, and the collapse of the central authority of the Catholic Church. Will the loss of science’s monopoly over truth lead to political chaos and even bloodshed? The answer largely depends upon the resilience of democratic institutions, and their ability to resist the authoritarian drift that seems to be a consequence of crises such as Covid and climate change, to which simple solutions, and simple truths, do not pertain.
Both the Church and the Protestants enthusiastically adopted the printing press. The Church tried to control it through an index of forbidden books. Protestant print shops adopted a more liberal cultural orientation, one that allowed for competition among diverse ideas about how to express and pursue faith. Today we see a similar dynamic. Mainstream, elite science institutions use the Internet to try to preserve their monopoly over which truths get followed where, but the Internet’s bottom-up, distributed architecture appears to give a decisive advantage to dissenters and their diverse ideologies and perspectives.
Holding on to the idea that science always draws clear boundaries between the true and the false will continue to appeal strongly to many sincere and concerned people. But if, as in the fifteenth century, we are now indeed experiencing a tumultuous transition to a new world of communication, what we may need is a different cultural orientation toward science and technology. The character of this new orientation is only now beginning to emerge, but it will above all have to accommodate the over-abundance of competing truths in human affairs, and create new opportunities for people to forge collective meaning as they seek to manage the complex crises of our day.
Monitoramento mostra que desinformação e mentiras servem como estratégia para enfraquecer pautas como a demarcação de terras
Fernanda Bassette – 26 de janeiro de 2022
Embaixo de uma das tendas instaladas em Brasília, no maior acampamento indígena da história da democracia brasileira, em setembro de 2021, o cacique Agnelo Xavante, 52, da Terra Indígena Etewawe (MT), assumiu o microfone e, por um momento, parou a mobilização.
Visivelmente consternado, o líder pediu a atenção dos quase 6.000 indígenas presentes. Ele precisava desmentir um vídeo compartilhado em grupos de WhatsApp que prejudicava todos ali.
A postagem tinha alcançado grupos indígenas de todo o país no aplicativo, disse Agnelo. Mas não só. O conteúdo já circulava em outros grupos públicos no Amazonas no WhatsApp, cujos interesses vão de política à religião, monitorados desde agosto pelo projeto Amazonas – Mentira tem Preço, do InfoAmazonia e da produtora FALA.
“O vídeo chegou em muitos grupos de WhatsApp. Aquilo doeu na gente. Você sabe o que são 320 aldeias xavantes irritadas? Isso nunca tinha acontecido. Eu, guerreiro do povo Xavante, não podia ouvir e ficar calado”, lembra.
Agnelo disparou um novo vídeo em suas redes de contato, desmentindo o anterior, que acusava, sem provas, a Apib (Articulação dos Povos Indígenas do Brasil) e a Coiab (Coordenação das Organizações Indígenas da Amazônia Brasileira) de usar recursos do acampamento para outros fins.
“A demarcação de terras indígenas não interessa a muitos, por isso gravam esses vídeos mentirosos. Nosso confronto e a nossa divisão é tudo o que eles querem”, diz Agnelo. O julgamento foi suspenso após um pedido de vista do ministro Alexandre de Moraes, que queria mais tempo para analisar o caso.
Enquanto Agnelo gravava o vídeo, a cacica Eronilde Fermin Omágua, do povo Kambeba de São Paulo de Olivença (AM), que também estava na mobilização nacional, precisou se defender de mensagens de ódio compartilhadas pelas redes.
“Uma pessoa jogou dois áudios contra mim num grupo de WhatsApp que possui mais de 300 mulheres do Amazonas, dizendo que eu não estava lutando pelos direitos coletivos, que não era comprometida com a causa e que não representava o meu povo”, recorda.
“Deixei de ser vista como uma lutadora e virei uma vilã. Sou atacada dia e noite e isso já adoeceu minha família.” Eronilde diz não conhecer a mulher indígena que a acusou.
Quem não estava em Brasília também foi alvo de ataques. Enquanto Milena Mura, liderança do povo Mura (Amazonas), e outras 400 pessoas, de 17 comunidades, protestavam contra a tese do marco temporal na rodovia estadual M254, que liga Manaus a Porto Velho, histórias distorcidas foram compartilhadas.
“Começaram a espalhar que estávamos em busca de briga política, que queríamos causar arruaça e que estávamos prejudicando o comércio e a saúde, por causa da pandemia de Covid-19”, diz.
“Com isso, até mesmo outras aldeias começaram a atacar nossa organização, questionando os objetivos do nosso movimento.”
Segundo Milena, o Conselho Indígena Mura teve de convocar uma reunião extraordinária e reunir lideranças de 34 aldeias para desmentir as notícias falsas.
Para Denise Dora, diretora-executiva da organização Artigo 19 no Brasil e na América do Sul, “a desinformação é uma estratégia”.
“No caso dos povos indígenas, ocorre para ter acesso à terra, aos recursos naturais e às áreas que são constitucionalmente protegidas por serem públicas e por respeitarem a histórica presença dos indígenas”, afirma.
Nos onze grupos públicos do Amazonas monitorados pela reportagem, histórias atacando a mobilização contra a tese do marco temporal também foram compartilhadas. Uma delas, por exemplo, creditava genericamente os protestos a ONGs e partidos de esquerda.
Leda Gitahy, professora do Departamento de Política Científica e Tecnológica da Unicamp (Universidade Estadual de Campinas) e uma das coordenadoras do Grupo de Estudo da Desinformação em Redes Sociais, diz que existe um ecossistema que cuidadosamente organiza estratégias de desinformação e de propaganda política para dividir as comunidades.
“O problema é o mesmo no país inteiro. A lógica que está por trás disso é soltar mensagens de difusão rápida e articulada para causar confusão e dúvida”, afirma.
“A estratégia das mentiras compartilhadas em grupos de WhatsApp é fazer os indígenas brigarem dentro do seu povo para desestruturar o movimento.”
Relatórios do Cimi (Conselho Indigenista Missionário) e da Apib destacam que 2020 ficou marcado pelo alto número de mortes de indígenas ocorridas em decorrência da má gestão do enfrentamento à pandemia no Brasil, pautada pela desinformação e pela negligência do governo.
“O governo federal é o principal agente transmissor do vírus entre os povos indígenas”, diz o documento da Apib.
“As fake news diziam que a vacina era do diabo, que vem com um chip implantado, de um tudo que era para que as pessoas não tomassem. E tivemos resistência dentro do território: em uma calha [área no rio] onde há mais de mil pessoas só 160 quiseram tomar a vacina naquele momento”, contou o presidente da Foirn (Federação das Organizações Indígenas do Rio Negro), no Amazonas, Marivaldo Baré.
Segundo ele, o governo federal não promoveu nenhuma campanha de informação sobre a vacina para combater a estratégia de desinformação que atingiu as aldeias do Alto Rio Negro. Pelo contrário, a descrença pública do presidente sobre as vacinas ajudou a piorar a situação.
“Tivemos que trabalhar muito para produzir, por nossa conta, áudios e cartilhas falando sobre a importância da vacinação e da prevenção para evitar contaminação.”
O Ministério da Saúde foi procurado, via assessoria de imprensa, para comentar os aspectos mencionados pela Apib e pela Foirn, mas não se manifestou até a publicação da reportagem.
A auxiliar de enfermagem indígena Vanda Ortega Witoto foi vítima de difamação e racismo em grupos públicos de WhatsApp e nas redes sociais após ser a primeira pessoa do Amazonas a ser vacinada contra a Covid, em janeiro de 2021.
“Diziam que eu era uma ‘índia fake’ por não vestir roupas tradicionais e por morar na cidade e não na aldeia. Diziam que deveriam vacinar índios de verdade e não eu”, conta. “Passei a receber inúmeras mensagens de ódio, foi horrível.”
Os conteúdos falsos, afirma Francesc Comelles, coordenador regional do Cimi, começaram a ter um impacto maior nas comunidades indígenas à medida que o acesso à internet chegou dentro dos territórios.
Se por um lado a tecnologia conectou lideranças e permitiu que denunciassem violações com agilidade, por outro expôs todos às fake news.
“Essa mistura de informação verdadeira com informação distorcida e mal-intencionada foi potencializada com as fake news em torno da pandemia, o que teve um impacto direto na saúde dos indígenas”, afirma.
Quem é alvo de conteúdos inverídicos distribuídos pelas mídias sociais deve buscar suporte. Segundo Denise Dora, a busca de ajuda deve ser feita sempre por meio da organização indígena majoritária da região ou da Defensoria Pública da União, do Ministério Público Federal e das organizações da sociedade civil. “É preciso buscar ajuda para reverter. E existem mecanismos para isso”, afirma.
Em nota, a Coiab afirmou que os indígenas vítimas de mentiras devem avaliar se o alcance da ação pode causar um mal injusto e dano direto à sua pessoa.
Em caso positivo, devem procurar a autoridade policial e “a sua organização regional com a finalidade de dar publicidade sobre o acontecido e buscar suporte.”
Procurada para comentar sobre ações de suporte aos indígenas, a Funai (Fundação Nacional do Índio) disse que “em vez de trabalhar com assertivas falsas, tem atuado, efetivamente, com medidas práticas de apoio à população indígena, a exemplo do investimento de cerca de R$ 34 milhões em ações de fiscalização em Terras Indígenas de todo o país em 2021”.
A reportagem integra o projeto Amazonas – Mentira tem preço, publicado em parceria pelo InfoAmazonia e pela produtora FALA.
Contra expectativas e previsões, mais uma vez o Brasil surpreende. A população brasileira vive nos últimos dois anos um boom de interesse por ciência, ocasionado pela pandemia e seus efeitos. Apesar de sermos uma sociedade desigual e apenas 5% da população ter curso superior concluído, a maioria apoia e quer conhecer mais a ciência. A eleição presidencial de 2018 foi combustível para a indústria de fake news e deu força a discursos que negam ou distorcem a realidade e as evidências científicas e históricas. Naquele momento, parecia que entraríamos fundo em uma fase de obscurantismo.
Mas a história deu sua volta, diante da tragédia imposta pela gestão do governo federal diante do coronavírus, a mobilização foi em sentido contrário. A sociedade brasileira, majoritariamente, reagiu ao negacionismo, impulsionada pela necessidade de lutar contra a pandemia, procurar informação confiável e defender a vida. Com o auxílio de cientistas, mídia e movimentos pela vida, vimos aumentar o interesse sobre ciência, universidades e institutos que produzem conhecimento.
Foi neste contexto que instituímos o SoU_Ciência. Um centro que congrega pesquisadores e cujas atividades estão voltadas para dialogar com a sociedade sobre a política científica e de educação superior, em especial sobre o que fazem as universidades públicas, que no Brasil são responsáveis por mais de 90% da produção de conhecimento e abrigam 8 entre 10 pesquisadores em nosso país. Em curto período de atuação, fizemos levantamentos de opinião pública, em parceria com o instituto Ideia Big Data, além de análises das mídias sociais, grupos focais e notícias. Descobrimos que o Brasil tem 94,5% da população a favor da vacinação contra Covid-19, e que a campanha antivacina liderada pelo próprio Presidente, tem apoio de apenas 5,5%. O que faz o nosso país ser diferente de países da Europa e dos EUA, onde os movimentos anti-vaxsão muito maiores, ainda podemos estudar. Certamente, a tradição em vacinações obtida pelo Plano Nacional de Imunizações (PNI), além do Sistema Único de Saúde (SUS), são fatores determinantes.
Em nossos levantamentos de opinião pública, 72% da população afirmou que seu interesse pela ciência aumentou com a pandemia. Isso fez 69,7% dos entrevistados declarar ter “muito interesse pela ciência” e apenas 2,2%, “nenhum interesse”. Entre evangélicos e os que consideram o governo ótimo/bom, o elevado interesse pela ciência também é expressivo: 63% e 62% respectivamente. Além disso, 32,1% da população declarou ter o hábito de pesquisar em sites, blogse canais das universidades e institutos de pesquisa na procura de informações confiáveis e, surpreendentemente, 40% gostariam de ler artigos científicos. Comparativamente, apenas 8,8% afirmam confiar no que o Bolsonaro fala sobre a pandemia, num claro distanciamento da população em relação ao presidente eleito em 2018.
A procura por informação confiável na pandemia levou a um fortalecimento do ecossistema que envolve universidades, instituições de pesquisa e cientistas na sua capacidade de comunicação e divulgação científica, com um ampliado espaço na mídia. Dois fenômenos merecem destaque. Em primeiro lugar, a competência que cientistas tiveram para se comunicar e alertar sobre o novo coronavírus e seus efeitos, utilizando redes sociais como o Twitter, e canais do YouTube, como monitorou o Science Pulseda Núcleo e IBPAD com apoio da Fundação Serrapilheira. Adicionalmente, muitos cientistas passaram a falar para a grande mídia, que por sua vez ampliou suas sessões de ciência e saúde e deu espaços para novos colunistas na área. Tem havido rápido aprendizado e maior mobilização de cientistas para utilizar os diferentes meios de comunicação.
O segundo fenômeno decorre do grande interesse da mídia e grande parte da população sobre os estudos clínicos das diversas vacinas que estavam sendo desenvolvidas em tempo recorde. Os estudos geraram grande audiência e expectativa. As universidades públicas, como a USP e a Unifesp, atuaram na coordenação dos estudos das duas primeiras vacinas licenciadas no País, ganharam enorme destaque. O Instituto Butantan e a Fiocruz, além das pesquisas, se tornaram mais conhecidos pelas pesquisas e produção dos imunizantes.
Diante de todos estes elementos, nos parece que, 120 anos depois da Revolta da Vacina, a revolta agora ocorre contra um governo que se recusou a comprar vacinas para sua população e propôs falsas alternativas, como apontou a CPI da Pandemia. A revolta em 2021, dado o enorme contingente a favor da vacina e em defesa da ciência, direcionou-se contra o governo federal e faz derreter a popularidade do presidente, passando a aprovação (ótimo/bom) de 37%, em dezembro de 2020, para 22% em dezembro de 2021, segundo o Datafolha; enquanto a rejeição (ruim/péssimo) passou de 32% para 53% no mesmo período. Dentre os fatores dessa virada de popularidade no “ano da vacina” esteve o contínuo embate presidencial contra a ciência, a partir da negação dos benefícios da vacina e da distorção nos dados. Isto vem ocorrendo de maneira renovada agora, na batalha da vacinação infantil e na fraca reação contra a variante Ômicron. Sem dúvida, em 2021 a maior oposição a Bolsonaro veio pela conscientização por meio da ciência e da aproximação dos cientistas junto à sociedade, mídia e redes sociais.
Tentando reagir nesse embate, o governo federal escalou alguns médicos e outros apoiadores para fazer o contraponto e distorcer dados científicos, criando novas interpretações fantasiosas. E atuou e segue atuando para o desmanche acelerado do sistema de ciência e pesquisa no Brasil, com ataques ao CNPq, CAPES e Finep, e cortes brutais de orçamento, cuja dimensão e impacto discutiremos noutros artigos deste blog. Ataques estes que não se reproduziram na opinião pública, já que levantamento do SoU_Ciência mostrou que somente 9% da população apoiam os cortes impostos.
Temos pela frente um grande desafio: consolidar a onda pró-ciência, para além da pandemia, e para tanto é necessária a recuperação do sistema nacional de ciência e pesquisa, com a recomposição efetiva de seu financiamento. Estamos diante da oportunidade de alcançarmos um novo patamar na relação sociedade-ciência com a formulação de políticas públicas baseadas em evidências científicas. Para isso, buscamos um “letramento científico” que colabore no combate às fake news e amplie a capacidade da população em tomar decisões racionais e fundamentadas. Os sinais são de esperança, mas nos pedem atenção e muito trabalho. A criação do Centro SoU_Ciência que terá neste blog uma voz, faz parte desse momento e pretende colaborar para fortalecer as conexões com a sociedade, na defesa da democracia, e na garantia de direitos para um novo momento da história de nosso país.
Soraya Smaili, farmacologista, professora titular da Escola Paulista de Medicina, Reitora da Unifesp (2013-2021). Atualmente é Coordenadora Adjunta do Centro de Saúde Global e Coordenadora Geral do SoU_Ciência;
Maria Angélica Minhoto, pedagoga e economista, professora da EFLCH-Unifesp, Pró- Reitora de Graduação (2013-2017) e Coordenadora Adjunta do SoU_Ciência;
Pedro Arantes, arquiteto e urbanista, professor da EFLCH-Unifesp, Pró-Reitor de Planejamento (2017-2021) e Coordenador Adjunto do SoU_Ciência.
Social and psychological forces are combining to make the sharing and believing of misinformation an endemic problem with no easy solution.
Credit: Jonathan Ernst/Reuters
Published May 7, 2021; Updated May 13, 2021
There’s a decent chance you’ve had at least one of these rumors, all false, relayed to you as fact recently: that President Biden plans to force Americans to eat less meat; that Virginia is eliminating advanced math in schools to advance racial equality; and that border officials are mass-purchasing copies of Vice President Kamala Harris’s book to hand out to refugee children.
All were amplified by partisan actors. But you’re just as likely, if not more so, to have heard it relayed from someone you know. And you may have noticed that these cycles of falsehood-fueled outrage keep recurring.
We are in an era of endemic misinformation — and outright disinformation. Plenty of bad actors are helping the trend along. But the real drivers, some experts believe, are social and psychological forces that make people prone to sharing and believing misinformation in the first place. And those forces are on the rise.
“Why are misperceptions about contentious issues in politics and science seemingly so persistent and difficult to correct?” Brendan Nyhan, a Dartmouth College political scientist, posed in a new paper in Proceedings of the National Academy of Sciences.
It’s not for want of good information, which is ubiquitous. Exposure to good information does not reliably instill accurate beliefs anyway. Rather, Dr. Nyhan writes, a growing body of evidence suggests that the ultimate culprits are “cognitive and memory limitations, directional motivations to defend or support some group identity or existing belief, and messages from other people and political elites.”
Put more simply, people become more prone to misinformation when three things happen. First, and perhaps most important, is when conditions in society make people feel a greater need for what social scientists call ingrouping — a belief that their social identity is a source of strength and superiority, and that other groups can be blamed for their problems.
As much as we like to think of ourselves as rational beings who put truth-seeking above all else, we are social animals wired for survival. In times of perceived conflict or social change, we seek security in groups. And that makes us eager to consume information, true or not, that lets us see the world as a conflict putting our righteous ingroup against a nefarious outgroup.
This need can emerge especially out of a sense of social destabilization. As a result, misinformation is often prevalent among communities that feel destabilized by unwanted change or, in the case of some minorities, powerless in the face of dominant forces.
Framing everything as a grand conflict against scheming enemies can feel enormously reassuring. And that’s why perhaps the greatest culprit of our era of misinformation may be, more than any one particular misinformer, the era-defining rise in social polarization.
“At the mass level, greater partisan divisions in social identity are generating intense hostility toward opposition partisans,” which has “seemingly increased the political system’s vulnerability to partisan misinformation,” Dr. Nyhan wrote in an earlier paper.
Growing hostility between the two halves of America feeds social distrust, which makes people more prone to rumor and falsehood. It also makes people cling much more tightly to their partisan identities. And once our brains switch into “identity-based conflict” mode, we become desperately hungry for information that will affirm that sense of us versus them, and much less concerned about things like truth or accuracy.
Credit: Gabriela Bhaskar for The New York Times
In an email, Dr. Nyhan said it could be methodologically difficult to nail down the precise relationship between overall polarization in society and overall misinformation, but there is abundant evidence that an individual with more polarized views becomes more prone to believing falsehoods.
The second driver of the misinformation era is the emergence of high-profile political figures who encourage their followers to indulge their desire for identity-affirming misinformation. After all, an atmosphere of all-out political conflict often benefits those leaders, at least in the short term, by rallying people behind them.
Then there is the third factor — a shift to social media, which is a powerful outlet for composers of disinformation, a pervasive vector for misinformation itself and a multiplier of the other risk factors.
“Media has changed, the environment has changed, and that has a potentially big impact on our natural behavior,” said William J. Brady, a Yale University social psychologist.
“When you post things, you’re highly aware of the feedback that you get, the social feedback in terms of likes and shares,” Dr. Brady said. So when misinformation appeals to social impulses more than the truth does, it gets more attention online, which means people feel rewarded and encouraged for spreading it.
How do we fight disinformation? Join Times tech reporters as they untangle the roots of disinformation and how to combat it. Plus we speak to special guest comedian Sarah Silverman. R.S.V.P. to this subscriber-exclusive event.
“Depending on the platform, especially, humans are very sensitive to social reward,” he said. Research demonstrates that people who get positive feedback for posting inflammatory or false statements become much more likely to do so again in the future. “You are affected by that.”
In 2016, the media scholars Jieun Shin and Kjerstin Thorson analyzed a data set of 300 million tweets from the 2012 election. Twitter users, they found, “selectively share fact-checking messages that cheerlead their own candidate and denigrate the opposing party’s candidate.” And when users encountered a fact-check that revealed their candidate had gotten something wrong, their response wasn’t to get mad at the politician for lying. It was to attack the fact checkers.
“We have found that Twitter users tend to retweet to show approval, argue, gain attention and entertain,” researcher Jon-Patrick Allem wrote last year, summarizing a study he had co-authored. “Truthfulness of a post or accuracy of a claim was not an identified motivation for retweeting.”
In another study, published last month in Nature, a team of psychologists tracked thousands of users interacting with false information. Republican test subjects who were shown a false headline about migrants trying to enter the United States (“Over 500 ‘Migrant Caravaners’ Arrested With Suicide Vests”) mostly identified it as false; only 16 percent called it accurate. But if the experimenters instead asked the subjects to decide whether to share the headline, 51 percent said they would.
“Most people do not want to spread misinformation,” the study’s authors wrote. “But the social media context focuses their attention on factors other than truth and accuracy.”
In a highly polarized society like today’s United States — or, for that matter, India or parts of Europe — those incentives pull heavily toward ingroup solidarity and outgroup derogation. They do not much favor consensus reality or abstract ideals of accuracy.
As people become more prone to misinformation, opportunists and charlatans are also getting better at exploiting this. That can mean tear-it-all-down populists who rise on promises to smash the establishment and control minorities. It can also mean government agencies or freelance hacker groups stirring up social divisions abroad for their benefit. But the roots of the crisis go deeper.
“The problem is that when we encounter opposing views in the age and context of social media, it’s not like reading them in a newspaper while sitting alone,” the sociologist Zeynep Tufekci wrote in a much-circulated MIT Technology Review article. “It’s like hearing them from the opposing team while sitting with our fellow fans in a football stadium. Online, we’re connected with our communities, and we seek approval from our like-minded peers. We bond with our team by yelling at the fans of the other one.”
In an ecosystem where that sense of identity conflict is all-consuming, she wrote, “belonging is stronger than facts.”
Joaquin Quiñonero Candela, a director of AI at Facebook, was apologizing to his audience.
It was March 23, 2018, just days after the revelation that Cambridge Analytica, a consultancy that worked on Donald Trump’s 2016 presidential election campaign, had surreptitiously siphoned the personal data of tens of millions of Americans from their Facebook accounts in an attempt to influence how they voted. It was the biggest privacy breach in Facebook’s history, and Quiñonero had been previously scheduled to speak at a conference on, among other things, “the intersection of AI, ethics, and privacy” at the company. He considered canceling, but after debating it with his communications director, he’d kept his allotted time.
As he stepped up to face the room, he began with an admission. “I’ve just had the hardest five days in my tenure at Facebook,” he remembers saying. “If there’s criticism, I’ll accept it.”
The Cambridge Analytica scandal would kick off Facebook’s largest publicity crisis ever. It compounded fears that the algorithms that determine what people see on the platform were amplifying fake news and hate speech, and that Russian hackers had weaponized them to try to sway the election in Trump’s favor. Millions began deleting the app; employees left in protest; the company’s market capitalization plunged by more than $100 billion after its July earnings call.
In the ensuing months, Mark Zuckerberg began his own apologizing. He apologized for not taking “a broad enough view” of Facebook’s responsibilities, and for his mistakes as a CEO. Internally, Sheryl Sandberg, the chief operating officer, kicked off a two-year civil rights audit to recommend ways the company could prevent the use of its platform to undermine democracy.
Finally, Mike Schroepfer, Facebook’s chief technology officer, asked Quiñonero to start a team with a directive that was a little vague: to examine the societal impact of the company’s algorithms. The group named itself the Society and AI Lab (SAIL); last year it combined with another team working on issues of data privacy to form Responsible AI.
Quiñonero was a natural pick for the job. He, as much as anybody, was the one responsible for Facebook’s position as an AI powerhouse. In his six years at Facebook, he’d created some of the first algorithms for targeting users with content precisely tailored to their interests, and then he’d diffused those algorithms across the company. Now his mandate would be to make them less harmful.
Facebook has consistently pointed to the efforts by Quiñonero and others as it seeks to repair its reputation. It regularly trots out various leaders to speak to the media about the ongoing reforms. In May of 2019, it granted a series of interviews with Schroepfer to the New York Times, which rewarded the company with a humanizing profile of a sensitive, well-intentioned executive striving to overcome the technical challenges of filtering out misinformation and hate speech from a stream of content that amounted to billions of pieces a day. These challenges are so hard that it makes Schroepfer emotional, wrote the Times: “Sometimes that brings him to tears.”
In the spring of 2020, it was apparently my turn. Ari Entin, Facebook’s AI communications director, asked in an email if I wanted to take a deeper look at the company’s AI work. After talking to several of its AI leaders, I decided to focus on Quiñonero. Entin happily obliged. As not only the leader of the Responsible AI team but also the man who had made Facebook into an AI-driven company, Quiñonero was a solid choice to use as a poster boy.
He seemed a natural choice of subject to me, too. In the years since he’d formed his team following the Cambridge Analytica scandal, concerns about the spread of lies and hate speech on Facebook had only grown. In late 2018 the company admitted that this activity had helped fuel a genocidal anti-Muslim campaign in Myanmar for several years. In 2020 Facebook started belatedly taking action against Holocaust deniers, anti-vaxxers, and the conspiracy movement QAnon. All these dangerous falsehoods were metastasizing thanks to the AI capabilities Quiñonero had helped build. The algorithms that underpin Facebook’s business weren’t created to filter out what was false or inflammatory; they were designed to make people share and engage with as much content as possible by showing them things they were most likely to be outraged or titillated by. Fixing this problem, to me, seemed like core Responsible AI territory.
I began video-calling Quiñonero regularly. I also spoke to Facebook executives, current and former employees, industry peers, and external experts. Many spoke on condition of anonymity because they’d signed nondisclosure agreements or feared retaliation. I wanted to know: What was Quiñonero’s team doing to rein in the hate and lies on its platform?
Joaquin Quiñonero Candela outside his home in the Bay Area, where he lives with his wife and three kids.
But Entin and Quiñonero had a different agenda. Each time I tried to bring up these topics, my requests to speak about them were dropped or redirected. They only wanted to discuss the Responsible AI team’s plan to tackle one specific kind of problem: AI bias, in which algorithms discriminate against particular user groups. An example would be an ad-targeting algorithm that shows certain job or housing opportunities to white people but not to minorities.
By the time thousands of rioters stormed the US Capitol in January, organized in part on Facebook and fueled by the lies about a stolen election that had fanned out across the platform, it was clear from my conversations that the Responsible AI team had failed to make headway against misinformation and hate speech because it had never made those problems its main focus. More important, I realized, if it tried to, it would be set up for failure.
The reason is simple. Everything the company does and chooses not to do flows from a single motivation: Zuckerberg’s relentless desire for growth. Quiñonero’s AI expertise supercharged that growth. His team got pigeonholed into targeting AI bias, as I learned in my reporting, because preventing such bias helps the company avoid proposed regulation that might, if passed, hamper that growth. Facebook leadership has also repeatedly weakened or halted many initiatives meant to clean up misinformation on the platform because doing so would undermine that growth.
In other words, the Responsible AI team’s work—whatever its merits on the specific problem of tackling AI bias—is essentially irrelevant to fixing the bigger problems of misinformation, extremism, and political polarization. And it’s all of us who pay the price.
“When you’re in the business of maximizing engagement, you’re not interested in truth. You’re not interested in harm, divisiveness, conspiracy. In fact, those are your friends,” says Hany Farid, a professor at the University of California, Berkeley who collaborates with Facebook to understand image- and video-based misinformation on the platform.
“They always do just enough to be able to put the press release out. But with a few exceptions, I don’t think it’s actually translated into better policies. They’re never really dealing with the fundamental problems.”
In March of 2012, Quiñonero visited a friend in the Bay Area. At the time, he was a manager in Microsoft Research’s UK office, leading a team using machine learning to get more visitors to click on ads displayed by the company’s search engine, Bing. His expertise was rare, and the team was less than a year old. Machine learning, a subset of AI, had yet to prove itself as a solution to large-scale industry problems. Few tech giants had invested in the technology.
Quiñonero’s friend wanted to show off his new employer, one of the hottest startups in Silicon Valley: Facebook, then eight years old and already with close to a billion monthly active users (i.e., those who have logged in at least once in the past 30 days). As Quiñonero walked around its Menlo Park headquarters, he watched a lone engineer make a major update to the website, something that would have involved significant red tape at Microsoft. It was a memorable introduction to Zuckerberg’s “Move fast and break things” ethos. Quiñonero was awestruck by the possibilities. Within a week, he had been through interviews and signed an offer to join the company.
His arrival couldn’t have been better timed. Facebook’s ads service was in the middle of a rapid expansion as the company was preparing for its May IPO. The goal was to increase revenue and take on Google, which had the lion’s share of the online advertising market. Machine learning, which could predict which ads would resonate best with which users and thus make them more effective, could be the perfect tool. Shortly after starting, Quiñonero was promoted to managing a team similar to the one he’d led at Microsoft.
Quiñonero started raising chickens in late 2019 as a way to unwind from the intensity of his job.
Unlike traditional algorithms, which are hard-coded by engineers, machine-learning algorithms “train” on input data to learn the correlations within it. The trained algorithm, known as a machine-learning model, can then automate future decisions. An algorithm trained on ad click data, for example, might learn that women click on ads for yoga leggings more often than men. The resultant model will then serve more of those ads to women. Today at an AI-based company like Facebook, engineers generate countless models with slight variations to see which one performs best on a given problem.
Facebook’s massive amounts of user data gave Quiñonero a big advantage. His team could develop models that learned to infer the existence not only of broad categories like “women” and “men,” but of very fine-grained categories like “women between 25 and 34 who liked Facebook pages related to yoga,” and targeted ads to them. The finer-grained the targeting, the better the chance of a click, which would give advertisers more bang for their buck.
Within a year his team had developed these models, as well as the tools for designing and deploying new ones faster. Before, it had taken Quiñonero’s engineers six to eight weeks to build, train, and test a new model. Now it took only one.
News of the success spread quickly. The team that worked on determining which posts individual Facebook users would see on their personal news feeds wanted to apply the same techniques. Just as algorithms could be trained to predict who would click what ad, they could also be trained to predict who would like or share what post, and then give those posts more prominence. If the model determined that a person really liked dogs, for instance, friends’ posts about dogs would appear higher up on that user’s news feed.
Quiñonero’s success with the news feed—coupled with impressive new AI research being conducted outside the company—caught the attention of Zuckerberg and Schroepfer. Facebook now had just over 1 billion users, making it more than eight times larger than any other social network, but they wanted to know how to continue that growth. The executives decided to invest heavily in AI, internet connectivity, and virtual reality.
They created two AI teams. One was FAIR, a fundamental research lab that would advance the technology’s state-of-the-art capabilities. The other, Applied Machine Learning (AML), would integrate those capabilities into Facebook’s products and services. In December 2013, after months of courting and persuasion, the executives recruited Yann LeCun, one of the biggest names in the field, to lead FAIR. Three months later, Quiñonero was promoted again, this time to lead AML. (It was later renamed FAIAR, pronounced “fire.”)
“That’s how you know what’s on his mind. I was always, for a couple of years, a few steps from Mark’s desk.”
Joaquin Quiñonero Candela
In his new role, Quiñonero built a new model-development platform for anyone at Facebook to access. Called FBLearner Flow, it allowed engineers with little AI experience to train and deploy machine-learning models within days. By mid-2016, it was in use by more than a quarter of Facebook’s engineering team and had already been used to train over a million models, including models for image recognition, ad targeting, and content moderation.
Zuckerberg’s obsession with getting the whole world to use Facebook had found a powerful new weapon. Teams had previously used design tactics, like experimenting with the content and frequency of notifications, to try to hook users more effectively. Their goal, among other things, was to increase a metric called L6/7, the fraction of people who logged in to Facebook six of the previous seven days. L6/7 is just one of myriad ways in which Facebook has measured “engagement”—the propensity of people to use its platform in any way, whether it’s by posting things, commenting on them, liking or sharing them, or just looking at them. Now every user interaction once analyzed by engineers was being analyzed by algorithms. Those algorithms were creating much faster, more personalized feedback loops for tweaking and tailoring each user’s news feed to keep nudging up engagement numbers.
Zuckerberg, who sat in the center of Building 20, the main office at the Menlo Park headquarters, placed the new FAIR and AML teams beside him. Many of the original AI hires were so close that his desk and theirs were practically touching. It was “the inner sanctum,” says a former leader in the AI org (the branch of Facebook that contains all its AI teams), who recalls the CEO shuffling people in and out of his vicinity as they gained or lost his favor. “That’s how you know what’s on his mind,” says Quiñonero. “I was always, for a couple of years, a few steps from Mark’s desk.”
With new machine-learning models coming online daily, the company created a new system to track their impact and maximize user engagement. The process is still the same today. Teams train up a new machine-learning model on FBLearner, whether to change the ranking order of posts or to better catch content that violates Facebook’s community standards (its rules on what is and isn’t allowed on the platform). Then they test the new model on a small subset of Facebook’s users to measure how it changes engagement metrics, such as the number of likes, comments, and shares, says Krishna Gade, who served as the engineering manager for news feed from 2016 to 2018.
If a model reduces engagement too much, it’s discarded. Otherwise, it’s deployed and continually monitored. On Twitter, Gade explained that his engineers would get notifications every few days when metrics such as likes or comments were down. Then they’d decipher what had caused the problem and whether any models needed retraining.
But this approach soon caused issues. The models that maximize engagement also favor controversy, misinformation, and extremism: put simply, people just like outrageous stuff. Sometimes this inflames existing political tensions. The most devastating example to date is the case of Myanmar, where viral fake news and hate speech about the Rohingya Muslim minority escalated the country’s religious conflict into a full-blown genocide. Facebook admitted in 2018, after years of downplaying its role, that it had not done enough “to help prevent our platform from being used to foment division and incite offline violence.”
While Facebook may have been oblivious to these consequences in the beginning, it was studying them by 2016. In an internal presentation from that year, reviewed by the Wall Street Journal, a company researcher, Monica Lee, found that Facebook was not only hosting a large number of extremist groups but also promoting them to its users: “64% of all extremist group joins are due to our recommendation tools,” the presentation said, predominantly thanks to the models behind the “Groups You Should Join” and “Discover” features.
“The question for leadership was: Should we be optimizing for engagement if you find that somebody is in a vulnerable state of mind?”
A former AI researcher who joined in 2018
In 2017, Chris Cox, Facebook’s longtime chief product officer, formed a new task force to understand whether maximizing user engagement on Facebook was contributing to political polarization. It found that there was indeed a correlation, and that reducing polarization would mean taking a hit on engagement. In a mid-2018 document reviewed by the Journal, the task force proposed several potential fixes, such as tweaking the recommendation algorithms to suggest a more diverse range of groups for people to join. But it acknowledged that some of the ideas were “antigrowth.” Most of the proposals didn’t move forward, and the task force disbanded.
Since then, other employees have corroborated these findings. A former Facebook AI researcher who joined in 2018 says he and his team conducted “study after study” confirming the same basic idea: models that maximize engagement increase polarization. They could easily track how strongly users agreed or disagreed on different issues, what content they liked to engage with, and how their stances changed as a result. Regardless of the issue, the models learned to feed users increasingly extreme viewpoints. “Over time they measurably become more polarized,” he says.
The researcher’s team also found that users with a tendency to post or engage with melancholy content—a possible sign of depression—could easily spiral into consuming increasingly negative material that risked further worsening their mental health. The team proposed tweaking the content-ranking models for these users to stop maximizing engagement alone, so they would be shown less of the depressing stuff. “The question for leadership was: Should we be optimizing for engagement if you find that somebody is in a vulnerable state of mind?” he remembers. (A Facebook spokesperson said she could not find documentation for this proposal.)
But anything that reduced engagement, even for reasons such as not exacerbating someone’s depression, led to a lot of hemming and hawing among leadership. With their performance reviews and salaries tied to the successful completion of projects, employees quickly learned to drop those that received pushback and continue working on those dictated from the top down.
One such project heavily pushed by company leaders involved predicting whether a user might be at risk for something several people had already done: livestreaming their own suicide on Facebook Live. The task involved building a model to analyze the comments that other users were posting on a video after it had gone live, and bringing at-risk users to the attention of trained Facebook community reviewers who could call local emergency responders to perform a wellness check. It didn’t require any changes to content-ranking models, had negligible impact on engagement, and effectively fended off negative press. It was also nearly impossible, says the researcher: “It’s more of a PR stunt. The efficacy of trying to determine if somebody is going to kill themselves in the next 30 seconds, based on the first 10 seconds of video analysis—you’re not going to be very effective.”
Facebook disputes this characterization, saying the team that worked on this effort has since successfully predicted which users were at risk and increased the number of wellness checks performed. But the company does not release data on the accuracy of its predictions or how many wellness checks turned out to be real emergencies.
That former employee, meanwhile, no longer lets his daughter use Facebook.
Quiñonero should have been perfectly placed to tackle these problems when he created the SAIL (later Responsible AI) team in April 2018. His time as the director of Applied Machine Learning had made him intimately familiar with the company’s algorithms, especially the ones used for recommending posts, ads, and other content to users.
It also seemed that Facebook was ready to take these problems seriously. Whereas previous efforts to work on them had been scattered across the company, Quiñonero was now being granted a centralized team with leeway in his mandate to work on whatever he saw fit at the intersection of AI and society.
At the time, Quiñonero was engaging in his own reeducation about how to be a responsible technologist. The field of AI research was paying growing attention to problems of AI bias and accountability in the wake of high-profile studies showing that, for example, an algorithm was scoring Black defendants as more likely to be rearrested than white defendants who’d been arrested for the same or a more serious offense. Quiñonero began studying the scientific literature on algorithmic fairness, reading books on ethical engineering and the history of technology, and speaking with civil rights experts and moral philosophers.
Over the many hours I spent with him, I could tell he took this seriously. He had joined Facebook amid the Arab Spring, a series of revolutions against oppressive Middle Eastern regimes. Experts had lauded social media for spreading the information that fueled the uprisings and giving people tools to organize. Born in Spain but raised in Morocco, where he’d seen the suppression of free speech firsthand, Quiñonero felt an intense connection to Facebook’s potential as a force for good.
Six years later, Cambridge Analytica had threatened to overturn this promise. The controversy forced him to confront his faith in the company and examine what staying would mean for his integrity. “I think what happens to most people who work at Facebook—and definitely has been my story—is that there’s no boundary between Facebook and me,” he says. “It’s extremely personal.” But he chose to stay, and to head SAIL, because he believed he could do more for the world by helping turn the company around than by leaving it behind.
“I think if you’re at a company like Facebook, especially over the last few years, you really realize the impact that your products have on people’s lives—on what they think, how they communicate, how they interact with each other,” says Quiñonero’s longtime friend Zoubin Ghahramani, who helps lead the Google Brain team. “I know Joaquin cares deeply about all aspects of this. As somebody who strives to achieve better and improve things, he sees the important role that he can have in shaping both the thinking and the policies around responsible AI.”
At first, SAIL had only five people, who came from different parts of the company but were all interested in the societal impact of algorithms. One founding member, Isabel Kloumann, a research scientist who’d come from the company’s core data science team, brought with her an initial version of a tool to measure the bias in AI models.
The team also brainstormed many other ideas for projects. The former leader in the AI org, who was present for some of the early meetings of SAIL, recalls one proposal for combating polarization. It involved using sentiment analysis, a form of machine learning that interprets opinion in bits of text, to better identify comments that expressed extreme points of view. These comments wouldn’t be deleted, but they would be hidden by default with an option to reveal them, thus limiting the number of people who saw them.
And there were discussions about what role SAIL could play within Facebook and how it should evolve over time. The sentiment was that the team would first produce responsible-AI guidelines to tell the product teams what they should or should not do. But the hope was that it would ultimately serve as the company’s central hub for evaluating AI projects and stopping those that didn’t follow the guidelines.
Former employees described, however, how hard it could be to get buy-in or financial support when the work didn’t directly improve Facebook’s growth. By its nature, the team was not thinking about growth, and in some cases it was proposing ideas antithetical to growth. As a result, it received few resources and languished. Many of its ideas stayed largely academic.
On August 29, 2018, that suddenly changed. In the ramp-up to the US midterm elections, President Donald Trump and other Republican leaders ratcheted up accusations that Facebook, Twitter, and Google had anti-conservative bias. They claimed that Facebook’s moderators in particular, in applying the community standards, were suppressing conservative voices more than liberal ones. This charge would later be debunked, but the hashtag #StopTheBias, fueled by a Trump tweet, was rapidly spreading on social media.
For Trump, it was the latest effort to sow distrust in the country’s mainstream information distribution channels. For Zuckerberg, it threatened to alienate Facebook’s conservative US users and make the company more vulnerable to regulation from a Republican-led government. In other words, it threatened the company’s growth.
Facebook did not grant me an interview with Zuckerberg, but previousreporting has shown how he increasingly pandered to Trump and the Republican leadership. After Trump was elected, Joel Kaplan, Facebook’s VP of global public policy and its highest-ranking Republican, advised Zuckerberg to tread carefully in the new political environment.
On September 20, 2018, three weeks after Trump’s #StopTheBias tweet, Zuckerberg held a meeting with Quiñonero for the first time since SAIL’s creation. He wanted to know everything Quiñonero had learned about AI bias and how to quash it in Facebook’s content-moderation models. By the end of the meeting, one thing was clear: AI bias was now Quiñonero’s top priority. “The leadership has been very, very pushy about making sure we scale this aggressively,” says Rachad Alao, the engineering director of Responsible AI who joined in April 2019.
It was a win for everybody in the room. Zuckerberg got a way to ward off charges of anti-conservative bias. And Quiñonero now had more money and a bigger team to make the overall Facebook experience better for users. They could build upon Kloumann’s existing tool in order to measure and correct the alleged anti-conservative bias in content-moderation models, as well as to correct other types of bias in the vast majority of models across the platform.
This could help prevent the platform from unintentionally discriminating against certain users. By then, Facebook already had thousands of models running concurrently, and almost none had been measured for bias. That would get it into legal trouble a few months later with the US Department of Housing and Urban Development (HUD), which alleged that the company’s algorithms were inferring “protected” attributes like race from users’ data and showing them ads for housing based on those attributes—an illegal form of discrimination. (The lawsuit is still pending.) Schroepfer also predicted that Congress would soon pass laws to regulate algorithmic discrimination, so Facebook needed to make headway on these efforts anyway.
(Facebook disputes the idea that it pursued its work on AI bias to protect growth or in anticipation of regulation. “We built the Responsible AI team because it was the right thing to do,” a spokesperson said.)
But narrowing SAIL’s focus to algorithmic fairness would sideline all Facebook’s other long-standing algorithmic problems. Its content-recommendation models would continue pushing posts, news, and groups to users in an effort to maximize engagement, rewarding extremist content and contributing to increasingly fractured political discourse.
Zuckerberg even admitted this. Two months after the meeting with Quiñonero, in a public note outlining Facebook’s plans for content moderation, he illustrated the harmful effects of the company’s engagement strategy with a simplified chart. It showed that the more likely a post is to violate Facebook’s community standards, the more user engagement it receives, because the algorithms that maximize engagement reward inflammatory content.
But then he showed another chart with the inverse relationship. Rather than rewarding content that came close to violating the community standards, Zuckerberg wrote, Facebook could choose to start “penalizing” it, giving it “less distribution and engagement” rather than more. How would this be done? With more AI. Facebook would develop better content-moderation models to detect this “borderline content” so it could be retroactively pushed lower in the news feed to snuff out its virality, he said.
The problem is that for all Zuckerberg’s promises, this strategy is tenuous at best.
Misinformation and hate speech constantly evolve. New falsehoods spring up; new people and groups become targets. To catch things before they go viral, content-moderation models must be able to identify new unwanted content with high accuracy. But machine-learning models do not work that way. An algorithm that has learned to recognize Holocaust denial can’t immediately spot, say, Rohingya genocide denial. It must be trained on thousands, often even millions, of examples of a new type of content before learning to filter it out. Even then, users can quickly learn to outwit the model by doing things like changing the wording of a post or replacing incendiary phrases with euphemisms, making their message illegible to the AI while still obvious to a human. This is why new conspiracy theories can rapidly spiral out of control, and partly why, even after such content is banned, forms of it canpersist on the platform.
In his New York Times profile, Schroepfer named these limitations of the company’s content-moderation strategy. “Every time Mr. Schroepfer and his more than 150 engineering specialists create A.I. solutions that flag and squelch noxious material, new and dubious posts that the A.I. systems have never seen before pop up—and are thus not caught,” wrote the Times. “It’s never going to go to zero,” Schroepfer told the publication.
Meanwhile, the algorithms that recommend this content still work to maximize engagement. This means every toxic post that escapes the content-moderation filters will continue to be pushed higher up the news feed and promoted to reach a larger audience. Indeed, a study from New York University recently found that among partisan publishers’ Facebook pages, those that regularly posted political misinformation received the most engagement in the lead-up to the 2020 US presidential election and the Capitol riots. “That just kind of got me,” says a former employee who worked on integrity issues from 2018 to 2019. “We fully acknowledged [this], and yet we’re still increasing engagement.”
But Quiñonero’s SAIL team wasn’t working on this problem. Because of Kaplan’s and Zuckerberg’s worries about alienating conservatives, the team stayed focused on bias. And even after it merged into the bigger Responsible AI team, it was never mandated to work on content-recommendation systems that might limit the spread of misinformation. Nor has any other team, as I confirmed after Entin and another spokesperson gave me a full list of all Facebook’s other initiatives on integrity issues—the company’s umbrella term for problems including misinformation, hate speech, and polarization.
A Facebook spokesperson said, “The work isn’t done by one specific team because that’s not how the company operates.” It is instead distributed among the teams that have the specific expertise to tackle how content ranking affects misinformation for their part of the platform, she said. But Schroepfer told me precisely the opposite in an earlier interview. I had asked him why he had created a centralized Responsible AI team instead of directing existing teams to make progress on the issue. He said it was “best practice” at the company.
“[If] it’s an important area, we need to move fast on it, it’s not well-defined, [we create] a dedicated team and get the right leadership,” he said. “As an area grows and matures, you’ll see the product teams take on more work, but the central team is still needed because you need to stay up with state-of-the-art work.”
When I described the Responsible AI team’s work to other experts on AI ethics and human rights, they noted the incongruity between the problems it was tackling and those, like misinformation, for which Facebook is most notorious. “This seems to be so oddly removed from Facebook as a product—the things Facebook builds and the questions about impact on the world that Facebook faces,” said Rumman Chowdhury, whose startup, Parity, advises firms on the responsible use of AI, and was acquired by Twitter after our interview. I had shown Chowdhury the Quiñonero team’s documentation detailing its work. “I find it surprising that we’re going to talk about inclusivity, fairness, equity, and not talk about the very real issues happening today,” she said.
“It seems like the ‘responsible AI’ framing is completely subjective to what a company decides it wants to care about. It’s like, ‘We’ll make up the terms and then we’ll follow them,’” says Ellery Roberts Biddle, the editorial director of Ranking Digital Rights, a nonprofit that studies the impact of tech companies on human rights. “I don’t even understand what they mean when they talk about fairness. Do they think it’s fair to recommend that people join extremist groups, like the ones that stormed the Capitol? If everyone gets the recommendation, does that mean it was fair?”
“We’re at a place where there’s one genocide [Myanmar] that the UN has, with a lot of evidence, been able to specifically point to Facebook and to the way that the platform promotes content,” Biddle adds. “How much higher can the stakes get?”
Over the last two years, Quiñonero’s team has built out Kloumann’s original tool, called Fairness Flow. It allows engineers to measure the accuracy of machine-learning models for different user groups. They can compare a face-detection model’s accuracy across different ages, genders, and skin tones, or a speech-recognition algorithm’s accuracy across different languages, dialects, and accents.
Fairness Flow also comes with a set of guidelines to help engineers understand what it means to train a “fair” model. One of the thornier problems with making algorithms fair is that there are different definitions of fairness, which can be mutually incompatible. Fairness Flow lists four definitions that engineers can use according to which suits their purpose best, such as whether a speech-recognition model recognizes all accents with equal accuracy or with a minimum threshold of accuracy.
But testing algorithms for fairness is still largely optional at Facebook. None of the teams that work directly on Facebook’s news feed, ad service, or other products are required to do it. Pay incentives are still tied to engagement and growth metrics. And while there are guidelines about which fairness definition to use in any given situation, they aren’t enforced.
This last problem came to the fore when the company had to deal with allegations of anti-conservative bias.
In 2014, Kaplan was promoted from US policy head to global vice president for policy, and he began playing a more heavy-handed role in content moderation and decisions about how to rank posts in users’ news feeds. After Republicans started voicing claims of anti-conservative bias in 2016, his team began manually reviewing the impact of misinformation-detection models on users to ensure—among other things—that they didn’t disproportionately penalize conservatives.
All Facebook users have some 200 “traits” attached to their profile. These include various dimensions submitted by users or estimated by machine-learning models, such as race, political and religious leanings, socioeconomic class, and level of education. Kaplan’s team began using the traits to assemble custom user segments that reflected largely conservative interests: users who engaged with conservative content, groups, and pages, for example. Then they’d run special analyses to see how content-moderation decisions would affect posts from those segments, according to a former researcher whose work was subject to those reviews.
The Fairness Flow documentation, which the Responsible AI team wrote later, includes a case study on how to use the tool in such a situation. When deciding whether a misinformation model is fair with respect to political ideology, the team wrote, “fairness” does not mean the model should affect conservative and liberal users equally. If conservatives are posting a greater fraction of misinformation, as judged by public consensus, then the model should flag a greater fraction of conservative content. If liberals are posting more misinformation, it should flag their content more often too.
But members of Kaplan’s team followed exactly the opposite approach: they took “fairness” to mean that these models should not affect conservatives more than liberals. When a model did so, they would stop its deployment and demand a change. Once, they blocked a medical-misinformation detector that had noticeably reduced the reach of anti-vaccine campaigns, the former researcher told me. They told the researchers that the model could not be deployed until the team fixed this discrepancy. But that effectively made the model meaningless. “There’s no point, then,” the researcher says. A model modified in that way “would have literally no impact on the actual problem” of misinformation.
“I don’t even understand what they mean when they talk about fairness. Do they think it’s fair to recommend that people join extremist groups, like the ones that stormed the Capitol? If everyone gets the recommendation, does that mean it was fair?”
Ellery Roberts Biddle, editorial director of Ranking Digital Rights
This happened countless other times—and not just for content moderation. In 2020, the Washington Post reported that Kaplan’s team had undermined efforts to mitigate election interference and polarization within Facebook, saying they could contribute to anti-conservative bias. In 2018, it used the same argument to shelve a project to edit Facebook’s recommendation models even though researchers believed it would reduce divisiveness on the platform, according to the Wall Street Journal. His claims about political bias also weakened a proposal to edit the ranking models for the news feed that Facebook’s data scientists believed would strengthen the platform against the manipulation tactics Russia had used during the 2016 US election.
And ahead of the 2020 election, Facebook policy executives used this excuse, according to the New York Times, to veto or weaken several proposals that would have reduced the spread of hateful and damaging content.
Facebook disputed the Wall Street Journal’s reporting in a follow-up blog post, and challenged the New York Times’s characterization in an interview with the publication. A spokesperson for Kaplan’s team also denied to me that this was a pattern of behavior, saying the cases reported by the Post, the Journal, and the Times were “all individual instances that we believe are then mischaracterized.” He declined to comment about the retraining of misinformation models on the record.
Many of these incidents happened before Fairness Flow was adopted. But they show how Facebook’s pursuit of fairness in the service of growth had already come at a steep cost to progress on the platform’s other challenges. And if engineers used the definition of fairness that Kaplan’s team had adopted, Fairness Flow could simply systematize behavior that rewarded misinformation instead of helping to combat it.
Often “the whole fairness thing” came into play only as a convenient way to maintain the status quo, the former researcher says: “It seems to fly in the face of the things that Mark was saying publicly in terms of being fair and equitable.”
The last time I spoke with Quiñonero was a month after the US Capitol riots. I wanted to know how the storming of Congress had affected his thinking and the direction of his work.
In the video call, it was as it always was: Quiñonero dialing in from his home office in one window and Entin, his PR handler, in another. I asked Quiñonero what role he felt Facebook had played in the riots and whether it changed the task he saw for Responsible AI. After a long pause, he sidestepped the question, launching into a description of recent work he’d done to promote greater diversity and inclusion among the AI teams.
I asked him the question again. His Facebook Portal camera, which uses computer-vision algorithms to track the speaker, began to slowly zoom in on his face as he grew still. “I don’t know that I have an easy answer to that question, Karen,” he said. “It’s an extremely difficult question to ask me.”
Entin, who’d been rapidly pacing with a stoic poker face, grabbed a red stress ball.
I asked Quiñonero why his team hadn’t previously looked at ways to edit Facebook’s content-ranking models to tamp down misinformation and extremism. He told me it was the job of other teams (though none, as I confirmed, have been mandated to work on that task). “It’s not feasible for the Responsible AI team to study all those things ourselves,” he said. When I asked whether he would consider having his team tackle those issues in the future, he vaguely admitted, “I would agree with you that that is going to be the scope of these types of conversations.”
Near the end of our hour-long interview, he began to emphasize that AI was often unfairly painted as “the culprit.” Regardless of whether Facebook used AI or not, he said, people would still spew lies and hate speech, and that content would still spread across the platform.
I pressed him one more time. Certainly he couldn’t believe that algorithms had done absolutely nothing to change the nature of these issues, I said.
“I don’t know,” he said with a halting stutter. Then he repeated, with more conviction: “That’s my honest answer. Honest to God. I don’t know.”
Corrections:We amended a line that suggested that Joel Kaplan, Facebook’s vice president of global policy, had used Fairness Flow. He has not. But members of his team have used the notion of fairness to request the retraining of misinformation models in ways that directly contradict Responsible AI’s guidelines. We also clarified when Rachad Alao, the engineering director of Responsible AI, joined the company.
“Coordenei uma equipe de trolls formada por 10 pessoas. Mas há equipes maiores no setor”, diz um community manager que durante boa parte da última década atuou em uma agência internacional que vendia serviços de amplificação artificial de mensagens no Twitter. “Trabalhei em projetos em cinco países, entre eles a Espanha. Existe uma demanda para contratos desse tipo que não é anunciada nas Páginas Amarelas”, diz.
Com esta experiência, ele agora quer revelar como funciona esse negócio obscuro capaz de influenciar a opinião pública. Há algumas semanas, começou a contar detalhes em uma conta do Twitter chamada ironicamente @thebotruso (“o robô russo”). O EL PAÍS, que comprovou seu papel na agência em questão, trocou dúzias de mensagens com @thebotruso sobre como são preparadas a executadas atualmente as célebres campanhas de bots e trolls a serviço de empresas, partidos políticos ou clubes esportivos. O ex-funcionário mantém o anonimato porque um contrato de confidencialidade o impede de revelar o conteúdo específico e os clientes de seu antigo trabalho.
O Twitter não é uma réplica da vida real. Mas os debates ou opiniões que dominam a rede frequentemente vão parar na mídia. Ou mesmo na tribuna dos Parlamentos. “As ruas estão ficando cheias de bots”, disse com ironia Santiago Abascal, líder do partido Vox, ao primeiro-ministro espanhol, o socialista Pedro Sánchez, durante um debate nesta segunda-feira, referindo-se a recentes manifestações da direita no país. Uma parte das contas que discutem no Twitter é falsa. O problema é saber quantas ou, mais difícil, quais são, e que influência exercem. “Eu gostava de chamar a atenção de jornalistas afins. Aumenta muito nosso ego que um jornalista pegue os conteúdos de sua conta troll como fonte dos seus artigos, além de ajudar a ganhar visibilidade”, conta @thebotruso.
1. Nem todos são ‘bots’
Por definição se usa bot como sinônimo de conta falsa no Twitter. Mas um bot é uma conta automatizada, não necessariamente falsa. Anos atrás, eles eram os principais encarregados de amplificar mensagens: faziam milhares de retuítes ou likes, ou serviam para engrossar contas de seguidores. Continuam tendo essa finalidade, mas, graças a ações do Twitter e à maior sofisticação dos usuários atuais, ficou mais fácil descobri-los e eliminá-los.
A agência onde @thebotruso trabalhava tem um software para programar bots. Ele dá ordens para fazer tantos retuítes de tais contas ou disparar tuítes previamente redigidos em horários determinados. É barato, mas pouco refinado. “Continua-se trabalhando para amplificar o conteúdo, mas é preciso ser cuidadoso, porque pode acarretar um problema de reputação ao cliente”, diz.
Para evitá-lo, há vários recursos que permitem humanizar ou desvincular esses bots de uma campanha: “Os bots não irão retuitar qualquer coisa que se mexa. Se forem feitas ações com um troll específico, por exemplo, isso gera um padrão, com o que um analista de dados da concorrência seria capaz de levantar a lebre”, diz.
Os bots tampouco seguirão a conta do cliente que os paga, como precaução para uma eventual descoberta. “Se pegarmos como exemplo a causa independentista [da Catalunha], os bots seguirão diferentes partidos, políticos e associações, mas não o cliente final”, explica. Também se observa se há usuários reais interagindo com algum bot. Nesse caso, um funcionário entrará no circuito para responder.
2. A chave são dois tipos de trolls
A definição habitual de troll está associada a um usuário vândalo ou impertinente. Na agência, essas eram suas contas-estrelas. Cada empregado podia administrar 30 delas, cada uma com seu comportamento humano. Os trolls se dividiam em alfa e beta.
As contas alfa difundem a mensagem. Começavam com uma estratégia de “me siga e eu te sigo”, para ganhar peso. Seus tuítes iniciais eram inflados pelos bots e depois interagiam com contas importantes para chamar a atenção. Na Espanha, ficou famosa a conta de Miguel Lacambra, que conseguiu 20.000 seguidores em poucas semanas com uma estratégia similar.
Os trolls beta são os guerrilheiros. Dedicam-se a amansar a crítica. São contas que respondem a tuítes de famosos com insultos ou ameaças. “Os afetados pelos ataques dos beta veem as respostas a seus tuítes e muitas vezes se contêm um pouco na hora de tuitar, dependendo do tema. Sentem-se incômodos e passam a querer ter um perfil mais discreto. O sistema é eficaz. Por isso, continuam sendo contratados e aperfeiçoados. E nós, usuários, continuamos caindo”, diz.
3. O objetivo: enganar o Twitter
Uma parte dos esforços é dedicada a evitar a detecção das armadilhas e aumentar a probabilidade de sucesso: “Os trolls não se seguirão entre si e se limitará a interação entre eles para que liderem vários grupos de diálogo e porque uma relação habitual entre dois ou mais trolls poria a operação em risco”, diz @thebotruso. As contas são mapeadas com uma ferramenta habitual entre pesquisadores, chamada Gephi, para ver se a relação entre eles é destacável: “Esses gephis seriam capazes de revelar a relação entre nossas contas (trolls e bots), por isso todo cuidado é pouco”, diz.
Há, além disso, um objetivo permanente em todas essas operações: evitar padrões. “Cada conta que um troll dirige deve escrever diferente: as pessoas têm tendência a utilizar certas expressões e deixar padrões de escrita, como pôr dois pontos de exclamação ou terminar todas as frases com reticências”, conta.
Os ardis para enganar o Twitter são ainda mais destacáveis com os bots automatizados: “O software comanda todos os bots, que se dividem em grupos. Cada grupo utiliza uma API [ferramenta para usar automaticamente o Twitter]. E o endereço IP é variado de forma aleatória. Chegamos a ter 3.000 ou 4.000 contas em uma mesma API, e me consta que poderiam ser usadas até mais. O problema é que, se você tiver muitas contas tuitando direto sob uma mesma API, pode levar o Twitter a bloqueá-la”, explica. Embora essas ferramentas permitam administrar milhares de contas, é preciso personalizar cada uma delas com foto, nome e biografia. É um trabalho longo demais para que o Twitter derrube 2.000 perfis de uma vez.
4. Toda campanha tem um plano
Cada campanha é preparada com análise de dados e objetivos diários. Os bots e trolls não surgem do nada. Antes de uma campanha, cientistas de dados analisam a conversação pública sobre o tema que interessa ao cliente: um partido que deseja ampliar sua bancada, uma empresa que espera bater um concorrente, ou um time de futebol com problemas de credibilidade.
“Eles veem quantas contas estão participando de um tema e se estabelece quantas seriam necessárias para ter influência”, diz. Também é analisado o sentimento e os influencers desses assuntos: “São feitas listas de contas favoráveis e contrárias, e se analisa o peso que elas têm”, diz. Essa informação é chave para o funcionamento da campanha: “Serve para que o troll saiba com que usuários interagir, para gerar um núcleo com eles, a quais responder e perseguir com os beta, e com que usuários nem sequer vale a pena perder tempo. Não é a mesma coisa iniciar uma conta do tranco ou com uma quantidade imensa de informação. O troll alfa sabe a quem se dirigir, com que tom, e o que comunicar”.
Uma campanha pode chegar a custar um milhão de euros (6,2 milhões de reais). O cliente espera resultados concretos e demonstráveis. Uma campanha média pode exigir entre 1.500 e 2.000 bots e trolls.
Enquanto os usuários normais do Twitter entram na rede para ver o que acontece, estas operações envolvendo centenas de contas falsas têm um plano diário. É como se a cada jornada um chefe mafioso enviasse um grupo de asseclas a uma cidade com um plano delicadamente concebido para que executem uma série de missões concretas e semeiem o pânico sem serem detectados. O objetivo é fazer os cidadãos acreditarem em coisas que não são verdade: não só com notícias falsas, mas também com ações que sugiram que mais gente acredita em determinada coisa do que realmente ocorre. Seria como inflar uma pesquisa de opinião. Claro que frequentemente se enfrentam equipes que buscam justamente o contrário.
Isto não fica só na teoria. Seus efeitos têm consequências no mundo real. “As pessoas tendem a compartilhar sua opinião quando se sentem protegidas pela comunidade”, diz esse agente. “Houve um tempo em que muitos catalães não independentistas não publicavam suas ideias nas redes porque entravam no Twitter e tinham a sensação que meio mundo era independentista.”
Estas ações em redes permitem abrir o caminho para opiniões radicais. De repente, alguém vê que a crítica aberta a imigrantes ou mulheres está permitida. Talvez não seja feita com crueldade ostensiva, e sim com memes ou palavras em código, mas está lá. Não se sabe se essas contas são controladas por uma dúzia de empregados em um escritório.
5. Como enganar um jornalista
Frequentemente, os jornalistas não têm consciência de como é fácil lhes passar mercadoria falsa. Um dos motivos que levou @thebotruso a criar essa conta e querer contar sua experiência foi para tentar advertir dos perigos: “Quem trabalha na mídia nem sempre conhece esse ecossistema. De certo modo, é fácil enganar um jornalista. Eles estão sempre procurando informações e, hoje em dia, a Internet é uma fonte muito grande. Se um jornalista topar com seu conteúdo, vir que tem apoio e que se encaixa no que ele quer (ou precisa) comunicar, talvez pegue. As estratégias para cada caso são diferentes. Por exemplo: para uma empresa acusada de corrupção, criamos um ecossistema que defendia os postos de trabalho (trabalhadores preocupados com as medidas exigidas contra a empresa)”, explica.
6. Como manipular uma pesquisa no Twitter
Os bots são úteis para ganhar uma pesquisa na rede. Estes são os passos que esta agência seguia: “Detecta-se a pesquisa e se faz uma captura de tela. É feito um cálculo para saber quantos votos são necessários para virar os resultados, e o valor de cada ponto percentual. Tem início a operação para que a opção desejada vença. Monitora-se para ver que tudo funciona corretamente”.
7. A criação de um ‘trending topic’
As opções para conseguir um trending topic eram mais reduzidas, mas a estratégia era clara. A agência trabalhava durante dias para atingir seu objetivo. “A primeira coisa é escolher um dia e uma hora. Procura-se não coincidir com eventos como um jogo de futebol ou o Big Brother”, explica @thebotruso. “Escolhe-se uma hashtag, é importante que não tenha sido utilizada antes, porque são mais difíceis de posicionar. Aciona-se a equipe de redatores que escrevem milhares de tuítes durante vários dias para que sejam publicados pela rede de bots”, acrescenta.
Usuários reais também são avisados, para caso tenham interesse. “São enviadas comunicações a pessoas afins para avisar da ação: tal dia, a tal hora, sairemos com tal hashtag para nos queixar, convidamos você à ação para ver se conseguimos ser tendência e fazer que nos ouçam”.
Chega o grande dia: “Os analistas olham quantos tuítes são necessários para entrar nas tendências. Os tuítes são inseridos na plataforma de bots. O cliente dispara o primeiro tuíte. Rapidamente a rede de bots é acionada. É crucial que haja muitos tuítes em um espaço curto de tempo. Os trolls alfa saem com tuítes de impacto. Os analistas de dados monitoram para saber se é preciso disparar mais tuítes, ou se é o caso de frear a rede de bots. Os trolls beta apoiam a ação, respondem aos críticos, estimulam outros usuários com a mesma ideologia”.
Passada a missão, com sucesso ou não, é hora de dissimular as provas: “A ação dos bots é detida e limpa: as contas bot fazem tuítes e retuítes de outros temas para que, se alguém aparecer para ver essas contas, não veja que só entraram para fazer tuítes sobre o trending e foram dormir. Os trolls podem continuar tuitando por algum tempo, e depois farão uma limpa, como os bots”, acrescenta. “Finalmente, prepara-se um relatório para o cliente”.
E como tudo isso afeta quem o faz? “Todos estávamos conscientes do que estávamos pondo em jogo. E eu gosto dessa palavra: jogo. Sempre recomendei a todo mundo que encarasse como jogar War, porque é fácil encarar os projetos como algo pessoal, e às vezes é difícil administrar a diferença entre a sua conta troll e você. Por sorte, nunca tive ninguém de licença por depressão, ansiedade ou nada parecido”.
So why can’t we stop such views from spreading? My opinion is that we have failed to understand their root causes, often assuming it is down to ignorance. But new research, published in my book, Knowledge Resistance: How We Avoid Insight from Others, shows that the capacity to ignore valid facts has most likely had adaptive value throughout human evolution. Therefore, this capacity is in our genes today. Ultimately, realising this is our best bet to tackle the problem.
So far, public intellectuals have roughly made two core arguments about our post-truth world. The physician Hans Rosling and the psychologist Steven Pinker argue it has come about due to deficits in facts and reasoned thinking – and can therefore be sufficiently tackled with education.
Meanwhile, Nobel Prize winner Richard Thaler and other behavioural economists have shown how the mere provision of more and better facts often lead already polarised groups to become even more polarised in their beliefs.
The conclusion of Thaler is that humans are deeply irrational, operating with harmful biases. The best way to tackle it is therefore nudging – tricking our irrational brains – for instance by changing measles vaccination from an opt-in to a less burdensome opt-out choice.
Such arguments have often resonated well with frustrated climate scientists, public health experts and agri-scientists (complaining about GMO-opposers). Still, their solutions clearly remain insufficient for dealing with a fact-resisting, polarised society.
Evolutionary pressures
In my comprehensive study, I interviewed numerous eminent academics at the University of Oxford, London School of Economics and King’s College London, about their views. They were experts on social, economic and evolutionary sciences. I analysed their comments in the context of the latest findings on topics raging from the origin of humanity, climate change and vaccination to religion and gender differences.
It became evident that much of knowledge resistance is better understood as a manifestation of social rationality. Essentially, humans are social animals; fitting into a group is what’s most important to us. Often, objective knowledge-seeking can help strengthen group bonding – such as when you prepare a well-researched action plan for your colleagues at work.
But when knowledge and group bonding don’t converge, we often prioritise fitting in over pursuing the most valid knowledge. In one large experiment, it turned out that both liberals and conservatives actively avoided having conversations with people of the other side on issues of drug policy, death penalty and gun ownership. This was the case even when they were offered a chance of winning money if they discussed with the other group. Avoiding the insights from opposing groups helped people dodge having to criticise the view of their own community.
Similarly, if your community strongly opposes what an overwhelming part of science concludes about vaccination or climate change, you often unconsciously prioritise avoiding getting into conflicts about it.
This is further backed up by research showing that the climate deniers who score the highest on scientific literacy tests are more confident than the average in that group that climate change isn’t happening – despite the evidence showing this is the case. And those among the climate concerned who score the highest on the same tests are more confident than the average in that group that climate change is happening.
This logic of prioritising the means that get us accepted and secured in a group we respect is deep. Those among the earliest humans who weren’t prepared to share the beliefs of their community ran the risk of being distrusted and even excluded.
And social exclusion was an enormous increased threat against survival – making them vulnerable to being killed by other groups, animals or by having no one to cooperate with. These early humans therefore had much lower chances of reproducing. It therefore seems fair to conclude that being prepared to resist knowledge and facts is an evolutionary, genetic adaptation of humans to the socially challenging life in hunter-gatherer societies.
Today, we are part of many groups and internet networks, to be sure, and can in some sense “shop around” for new alliances if our old groups don’t like us. Still, humanity today shares the same binary mindset and strong drive to avoid being socially excluded as our ancestors who only knew about a few groups. The groups we are part of also help shape our identity, which can make it hard to change groups. Individuals who change groups and opinions constantly may also be less trusted, even among their new peers.
In my research, I show how this matters when it comes to dealing with fact resistance. Ultimately, we need to take social aspects into account when communicating facts and arguments with various groups. This could be through using role models, new ways of framing problems, new rules and routines in our organisations and new types of scientific narratives that resonate with the intuitions and interests of more groups than our own.
There are no quick fixes, of course. But if climate change were reframed from the liberal/leftist moral perspective of the need for global fairness to conservative perspectives of respect for the authority of the father land, the sacredness of God’s creation and the individual’s right not to have their life project jeopardised by climate change, this might resonate better with conservatives.
If we take social factors into account, this would help us create new and more powerful ways to fight belief in conspiracy theories and fake news. I hope my approach will stimulate joint efforts of moving beyond disputes disguised as controversies over facts and into conversations about what often matters more deeply to us as social beings.